文章是由Intel的Java性能架构师(Java performance architect)Eric Kaczmared发表,用于探索如何对HBase进行Java GC调优,全文的测试基于YCSB 100% Read进行测试。
Apache HBase是一个有Apache基金会开源,提供Nosql 数据存储的项目。通常和HDFS一起使用,HBase已被全世界广泛引用。比如众所周知的Facebook,Twitter,Yahoo等等。从开发者的角度看,HBase是一个在Google Bigtable之后的分布式,版本控制,非关系数据库模型,对结构化数据进行分布式存储的系统。HBase可以轻松的通过纵向(使用更好的服务器)和横向(使用更多的机器)扩展处理非常高的吞吐。
从用户角度看,查询的延迟非常重要。我们通过和用户的合作,测试,调试,优化HBase的工作负载,我们遇到很多关注第99个百分位操作延迟的用户。这意味着从客户端请求到结果范围到客户端的一次往返,要在100ms内结束。
延迟受几个变量的影响。一个最具毁灭性和不可预测性的造成延迟的因素是JVM在GC时进行的停机“Stop the world(后面都用STW简写)”
为了复现,我们尝试用Oracle jdk7u21 and jdk7u60 G1 收集器。服务器的使用了Intel Xeon Ivy-bridge EP processors with Hyper-threading (40 logical processors). 256GB DDR3-1600 内存, 三块400GB SSD本地磁盘. 这个缩小版的配置包含了一个Master和一个Slave,配置成了单机集群,并且参数经过了适当的调整。我们使用HBase 0.98.1的版本和本地文件系统用于存储hfile。HBase 测试表配置成4亿行,共580G的大小。我们使用HBase的默认堆分配策略,40%给blockcache,40%给memstore。YCSB使用600个线程向HBase server发送请求。
下面的图片展示了在使用-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100在一小时100% read下情况。我们指定了收集器的堆大小和期望GC停机时间。 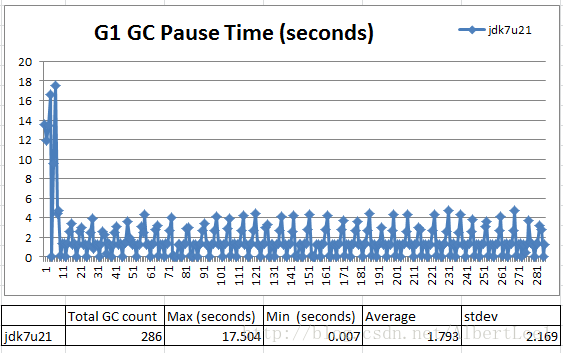
Figure 1: Wild swings in GC Pause time
在这种场景下,我们得到的GC停机时间浮动很大。GC停机时间在初始化时的峰值17.5s之后,从7ms到5s不等。
下面这张图展示了在GC稳定期的更多细节。 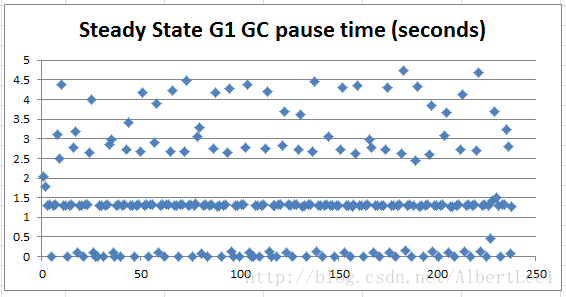
Figure 2: GC pause details, during steady state
上面这张图告诉我们GC停机时间有三个浮动区间,(1)在1~1.5s之间,(2)在0.007~5s之间,(3)在1.5和5s间。挺奇怪的,所以我们使用更新的版本jdk7u60来看看会有什么不同情况发生:
我们使用相同的100% read场景和相同的JVM参数测试:-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100 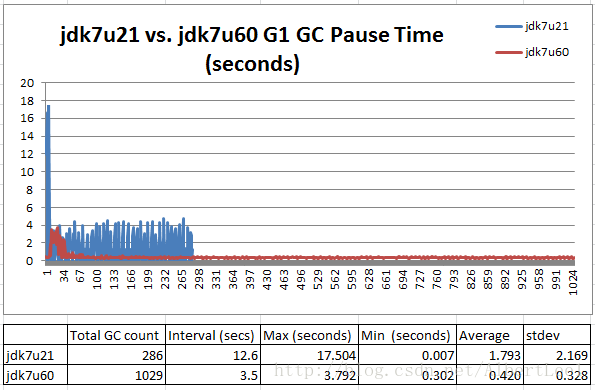
Figure 3: Greatly improved handling of pause time spikes
Jdk7u60能极大的提升GC停机时间的浮动。Jdk7u60在运行的这一小时当中共进行了1029次Young和Mixed GC。GC大约每3.5s进行一次。Jdk7u21进行了 286 次GC,每次大约12.6s。Jdk7u60可以将GC时间控制在0.3~1s之内,没有太大的浮动。
图4,展示了稳定状态期间的150次GC 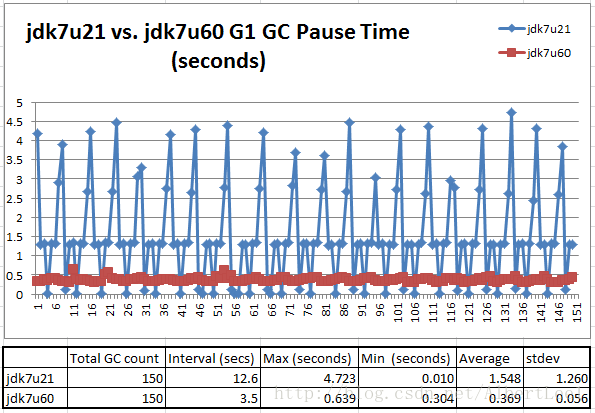
Figure 4: Better, but not good enough
在稳定期期间,jdk7u60可以将停机均值时间控制在369ms。比jdk7u21好太多,但是还不是通过–Xx:MaxGCPauseMillis=100配置的100ms以内。
为了确定通过其他的什么方式我们才能得到100ms的停机时间,我们需要理解G1 内存管理行为上的更多细节。下面这张图展示了G1 在Young代回时如何工作。 
Figure 5: Slide from the 2012 JavaOne presentation by Charlie Hunt and Monica Beckwith: “G1 Garbage Collector Performance Tuning”
当JVM基于参数启动,它会向操作系统申请一大块连续的内存空间来装载JVM Heap。这个大块连续的内存空间被分割成了JVM中的一个个Region。 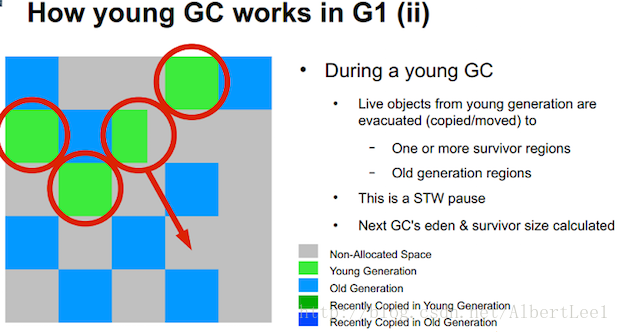
Figure 6: Slide from the 2012 JavaOne presentation by Charlie Hunt and Monica Beckwith: “G1 Garbage Collector Performance Tuning”
如图6所示,每个通过Java API初始化的对象会被分配在Young代的Eden区左侧。过一段时间,Eden区满了,Young代GC被处罚。仍然有引用的对象会被拷贝到Survivor区。当对象通过这种方式存活几次后,会被晋升到Old代空间。
当Young GC发生时,Java应用的线程会为了安全的标记和拷贝存活对象进行停机。这个停机就是臭名昭著的STW,会使得Java应用直到STW结束前都无相应。
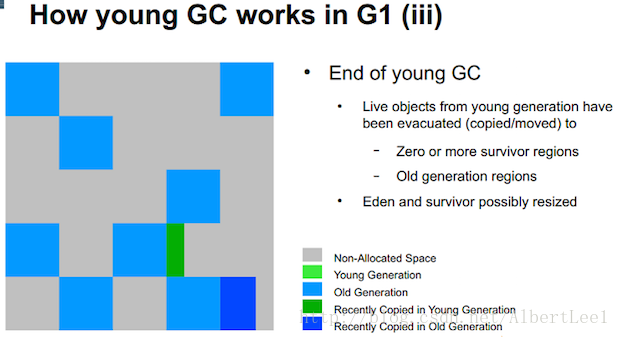
Figure 7: Slide from the 2012 JavaOne presentation by Charlie Hunt and Monica Beckwith: “G1 Garbage Collector Performance Tuning”
老年代也会变得拥挤。到达通过-XX:InitiatingHeapOccupancyPercent=?设置的一个程度后(默认值是45%),mixed GC被触发。它同时收集Young代和Old代。Mixed GC的停机时间由Young代有多长的清理时间决定。
所以,我们 可以看到G1的STW由G1的标记和拷贝Eden区存活对象决定。考虑到这一点,我们来分析HBase内存分配模式如何帮助我们调试G1 gc到我们的100ms期望停机时间。
在HBase中,有两个在内存中的结构消费了绝大多数的heap空间。BlockCache缓存读操作的HFile block,Memstore缓存近期的写操作。 
Figure 8: In HBase, two in-memory structures consume most of its heap.
HBase默认的BlockCache实现是LruBlockCache,可以简单地使用一个很大的byte数组装在所有的HBase Block。当Block被“驱逐(evicted)”,block引用的的java对象被删除,允许GC重新分配内存。
LruBlockCache和Memstore中的新对象首先会被放在Young代。如果存活时间够长(比如他们未被LruBlockCache驱逐或Memstore没有flush操作),之后经过了几次Young代GC,他们被晋升到了堆内存Old代。当Old代剩余空间低于一个给定的threshOld阈值(InitiatingHeapOccupancyPercent控制),mixed GC在老年代清理出dead对象,从Young代将存活对象拷贝到老年代,并且重新计算Young代Eden区和Old代HeapOccupancyPercent使用情况,当到达HeapOccupancyPercent的程度,FULL GC被触发,FULL GC会进行一次长时间的停机以清理掉Old代死掉的对象。
在学习了-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy打印的GC log后,我们注意到在100%读场景下,堆内存从未到达HeapOccupancyPercent以产生一次Full GC。我们看到的GC停机是由Young代STW引起引用处理超时。
综上所述,我们制定了默认G1 GC的三组修改:
1. 使用-XX:+ParallelRefProcEnabled
这个标识被打开,GC使用多线程在Young和mixed GC期间处理增加的引用。HBase使用这个标记后,GC remarking时间减少了75%,整体GC停机时间减少了30%。
2. 配置-XX:-ResizePLAB and -XX:ParallelGCThreads=8+(logical processors-8)(5/8)
Promotion Local Allocation Buffers(PLABs)是在Young代回收时被使用。并且是多线程。每个需要分配空间的对象被拷贝到Survior或者Old代。PLABs 需要避免使用线程共享的数据结构为了管理空闲内存。每个GC线程有一个PLAB用于一个Survival区和一个Old区。我们需要重新配置PLAB的大小来避免GC线程间的大量通信,这也是影响GC的一个变量。
3. 修改-XX:G1NewSizePercent,默认是100G HEAP的5%。因为使用了-XX:+PrintGCDetails and -XX:+PrintAdaptiveSizePolicy,我们注意到G1没有达到100ms预期gc时间的原因是因为把时间花在了Eden上。换句话说,G1清空5GEden空间的均值是369ms。所以,我们使用-XX:G1NewSizePercent=修改Eden大小,从默认的5降到1。基于这个变更,我们看到GC停机时间减少到了100ms。
从这个实验来看,我们发现G1清理Eden空间的速度是每1GB使用100ms,或者10GB每秒。
基于这个速度,我们配置-XX:G1NewSizePercent=使得Eden空间保持1GB左右。 例如:
- 32GB heap,-XX:G1NewSizePercent=3
- 64GB heap, -XX:G1NewSizePercent=2
- 100GB heap以上,-XX:G1NewSizePercent=1
- 所以,最后的HRegionServer参数确定为
- -XX:+UseG1GC
- -Xms100g -Xmx100g
- -XX:MaxGCPauseMillis=100
- –XX:+ParallelRefProcEnabled
- -XX:-ResizePLAB
- -XX:ParallelGCThreads= 8+(40-8)(5/8)=28
- -XX:G1NewSizePercent=1
下面是100% read运行1小时后,得到的GC图:
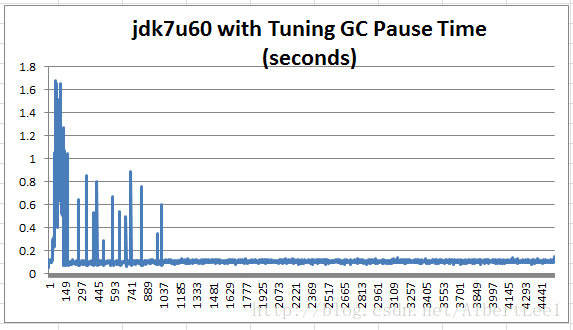
Figure 9: The highest initial settling spikes were reduced by more than half.
在图里,最高的波动从3.792s减少到了1.684s。初始化时的浮动减少了1s。修改过这些配置后,GC可以保持在100ms内。
下面这张图对比了jdk7u60调优前和调优后,在稳定期的对比情况: 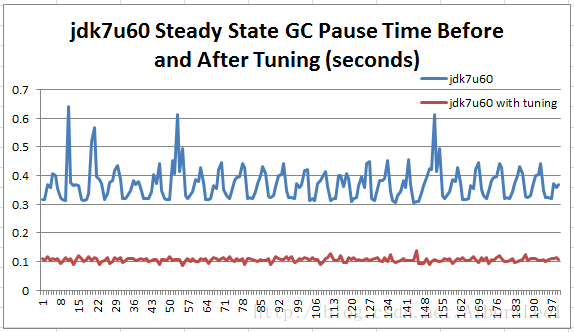
Figure 10: jdk7u60 runs with and without tuning, during steady state.
经过这个简单的GC调优,我们得到了理想的GC停机时间,在100ms左右,106ms的均值,7ms的标准差。
总结
HBase是一个响应时间敏感,并且需要对GC时间可控的应用。通过jdk7u60,基于GC回收信息命令-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy,我们可以调试GC的停机时间到理想的100ms