SQLAlchemy介绍
SQLAlchemy是一个基于Python的ORM框架。该框架是建立在DB-API之上,使用关系对象映射进行数据库操作。
简而言之就是,将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
补充:什么是DB-API ? 是Python的数据库接口规范。
在没有DB-API之前,各数据库之间的应用接口非常混乱,实现各不相同,
项目需要更换数据库的时候,需要做大量的修改,非常不方便,DB-API就是为了解决这样的问题。
pip install sqlalchemy
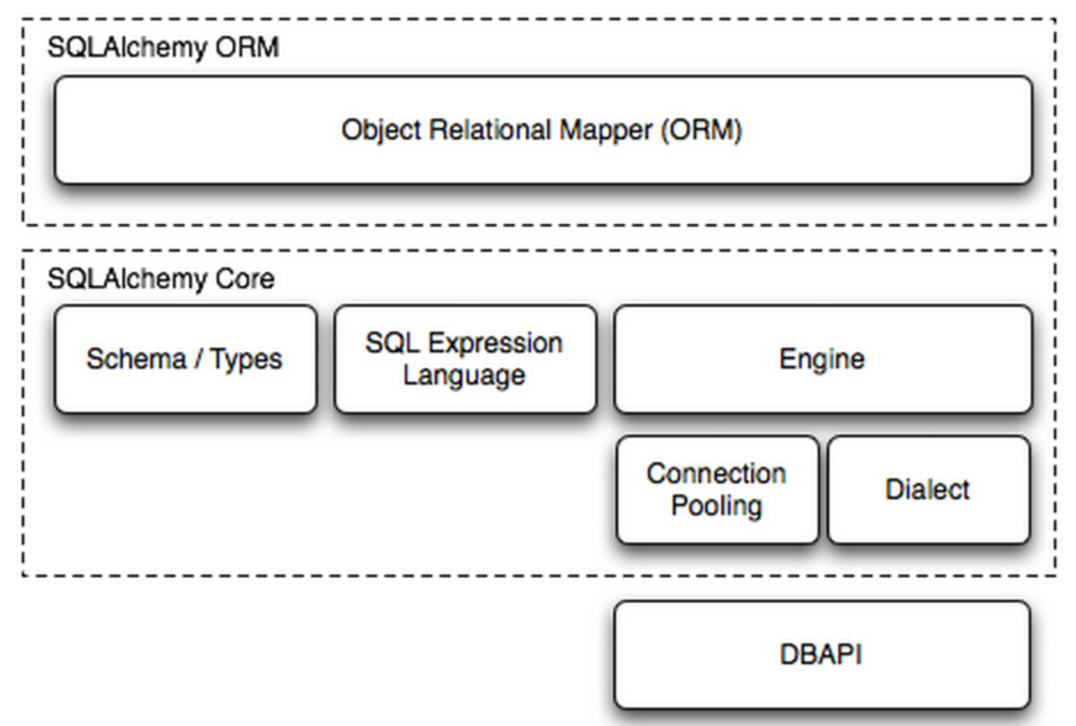
组成部分:
-- engine,框架的引擎
-- connection pooling 数据库连接池
-- Dialect 选择链接数据库的DB-API种类(实际选择哪个模块链接数据库)
-- Schema/Types 架构和类型
扫描二维码关注公众号,回复:
4753667 查看本文章

-- SQL Expression Language SQL表达式语言
连接数据库
SQLAlchemy 本身无法操作数据库,其必须依赖遵循DB-API规范的三方模块,
Dialect 用于和数据API进行交互,根据配置的不同调用不同数据库API,从而实现数据库的操作。


# MySQL-PYthon mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> #pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] # MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> # cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] # 更多 # http://docs.sqlalchemy.org/en/latest/dialects/index.html
from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接数 pool_size=5, # 连接池大小 pool_timeout=30, # 连接池中没有线程最多等待时间,否则报错 pool_recycle=-1, # 多久之后对连接池中的连接进行回收(重置)-1不回收 )
执行原生SQL
from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8", max_overflow=0, pool_size=5, ) def test(): cur = engine.execute("select * from Course") result = cur.fetchall() print(result) cur.close() if __name__ == '__main__': test() # [(1, '生物', 1), (2, '体育', 2), (3, '物理', 1)]
ORM
一,创建表
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime from sqlalchemy import Index, UniqueConstraint import datetime ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8",) Base = declarative_base() class UserInfo(Base): __tablename__ = "user_info" id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) email = Column(String(32), unique=True) create_time = Column(DateTime, default=datetime.datetime.now) __table_args__ = ( UniqueConstraint("id", "name", name="uni_id_name"), Index("name", "email") ) def create_db(): Base.metadata.create_all(ENGINE) def drop_db(): Base.metadata.drop_all(ENGINE) if __name__ == '__main__': create_db()
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime from sqlalchemy import Index, UniqueConstraint, ForeignKey from sqlalchemy.orm import relationship import datetime ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8",) Base = declarative_base() # ======一对多示例======= class UserInfo(Base): __tablename__ = "user_info" id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) email = Column(String(32), unique=True) create_time = Column(DateTime, default=datetime.datetime.now) # FK字段的建立 hobby_id = Column(Integer, ForeignKey("hobby.id")) # 不生成表结构 方便查询使用 hobby = relationship("Hobby", backref="user") __table_args__ = ( UniqueConstraint("id", "name", name="uni_id_name"), Index("name", "email") ) class Hobby(Base): __tablename__ = "hobby" id = Column(Integer, primary_key=True) title = Column(String(32), default="码代码") def create_db(): Base.metadata.create_all(ENGINE) def drop_db(): Base.metadata.drop_all(ENGINE) if __name__ == '__main__': create_db() # drop_db()
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime from sqlalchemy import Index, UniqueConstraint, ForeignKey from sqlalchemy.orm import relationship import datetime ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8",) Base = declarative_base() # ======多对多示例======= class Book(Base): __tablename__ = "book" id = Column(Integer, primary_key=True) title = Column(String(32)) # 不生成表字段 仅用于查询方便 tags = relationship("Tag", secondary="book2tag", backref="books") class Tag(Base): __tablename__ = "tag" id = Column(Integer, primary_key=True) title = Column(String(32)) class Book2Tag(Base): __tablename__ = "book2tag" id = Column(Integer, primary_key=True) book_id = Column(Integer, ForeignKey("book.id")) tag_id = Column(Integer, ForeignKey("tag.id")) def create_db(): Base.metadata.create_all(ENGINE) def drop_db(): Base.metadata.drop_all(ENGINE) if __name__ == '__main__': create_db() # drop_db()
二,对数据库表的操作(增删改查)
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session from models_demo import Tag ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8",) Session = sessionmaker(bind=ENGINE) # 每次执行数据库操作的时候,都需要创建一个session # 线程安全,基于本地线程实现每个线程用同一个session session = scoped_session(Session) # =======执行ORM操作========== tag_obj = Tag(title="SQLAlchemy") # 添加 session.add(tag_obj) # 提交 session.commit() # 关闭session session.close()
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session from models_demo import Tag, UserInfo import threading ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/code_record?charset=utf8",) Session = sessionmaker(bind=ENGINE) # 每次执行数据库操作的时候,都需要创建一个session session = Session() session = scoped_session(Session) # ============添加============ # tag_obj = Tag(title="SQLAlchemy") # # 添加 # session.add(tag_obj) # session.add_all([ # Tag(title="Python"), # Tag(title="Django"), # ]) # # 提交 # session.commit() # # 关闭session # session.close() # ============基础查询============ # ret1 = session.query(Tag).all() # ret2 = session.query(Tag).filter(Tag.title == "Python").all() # ret3 = session.query(Tag).filter_by(title="Python").all() # ret4 = session.query(Tag).filter_by(title="Python").first() # print(ret1, ret2, ret3, ret4) # ============删除=========== # session.query(Tag).filter_by(id=1).delete() # session.commit() # ===========修改=========== session.query(Tag).filter_by(id=22).update({Tag.title: "LOL"}) session.query(Tag).filter_by(id=23).update({"title": "王者农药"}) session.query(Tag).filter_by(id=24).update({"title": Tag.title + "~"}, synchronize_session=False) # synchronize_session="evaluate" 默认值进行数字加减 session.commit()
# 条件查询 ret1 = session.query(Tag).filter_by(id=22).first() ret2 = session.query(Tag).filter(Tag.id > 1, Tag.title == "LOL").all() ret3 = session.query(Tag).filter(Tag.id.between(22, 24)).all() ret4 = session.query(Tag).filter(~Tag.id.in_([22, 24])).first() from sqlalchemy import and_, or_ ret5 = session.query(Tag).filter(and_(Tag.id > 1, Tag.title == "LOL")).first() ret6 = session.query(Tag).filter(or_(Tag.id > 1, Tag.title == "LOL")).first() ret7 = session.query(Tag).filter(or_( Tag.id>1, and_(Tag.id>3, Tag.title=="LOL") )).all() # 通配符 ret8 = session.query(Tag).filter(Tag.title.like("L%")).all() ret9 = session.query(Tag).filter(~Tag.title.like("L%")).all() # 限制 ret10 = session.query(Tag).filter(~Tag.title.like("L%")).all()[1:2] # 排序 ret11 = session.query(Tag).order_by(Tag.id.desc()).all() # 倒序 ret12 = session.query(Tag).order_by(Tag.id.asc()).all() # 正序 # 分组 ret13 = session.query(Tag.test).group_by(Tag.test).all() # 聚合函数 from sqlalchemy.sql import func ret14 = session.query( func.max(Tag.id), func.sum(Tag.test), func.min(Tag.id) ).group_by(Tag.title).having(func.max(Tag.id > 22)).all() # 连表 ret15 = session.query(UserInfo, Hobby).filter(UserInfo.hobby_id == Hobby.id).all() # print(ret15) 得到一个列表套元组 元组里是两个对象 ret16 = session.query(UserInfo).join(Hobby).all() # print(ret16) 得到列表里面是前一个对象 # 相当于inner join # for i in ret16: # # print(i[0].name, i[1].title) # print(i.hobby.title) ret17 = session.query(Hobby).join(UserInfo, isouter=True).all() ret17_1 = session.query(UserInfo).join(Hobby, isouter=True).all() ret18 = session.query(Hobby).outerjoin(UserInfo).all() ret18_1 = session.query(UserInfo).outerjoin(Hobby).all() # 相当于left join print(ret17) print(ret17_1) print(ret18) print(ret18_1)
# 基于relationship的FK # 添加 user_obj = UserInfo(name="提莫", hobby=Hobby(title="种蘑菇")) session.add(user_obj) hobby = Hobby(title="弹奏一曲") hobby.user = [UserInfo(name="琴女"), UserInfo(name="妹纸")] session.add(hobby) session.commit() # 基于relationship的正向查询 user_obj_1 = session.query(UserInfo).first() print(user_obj_1.name) print(user_obj_1.hobby.title) # 基于relationship的反向查询 hb = session.query(Hobby).first() print(hb.title) for i in hb.user: print(i.name) session.close()
# 添加 book_obj = Book(title="Python源码剖析") tag_obj = Tag(title="Python") b2t = Book2Tag(book_id=book_obj.id, tag_id=tag_obj.id) session.add_all([ book_obj, tag_obj, b2t, ]) session.commit() # 上面有坑哦~~~~ book = Book(title="测试") book.tags = [Tag(title="测试标签1"), Tag(title="测试标签2")] session.add(book) session.commit() tag = Tag(title="LOL") tag.books = [Book(title="大龙刷新时间"), Book(title="小龙刷新时间")] session.add(tag) session.commit() # 基于relationship的正向查询 book_obj = session.query(Book).filter_by(id=4).first() print(book_obj.title) print(book_obj.tags) # 基于relationship的反向查询 tag_obj = session.query(Tag).first() print(tag_obj.title) print(tag_obj.books)