3>4 or 4<3 and 1==1 1 < 2 and 3 < 4 or 1>2 2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
1.while循环
在生活中,我们遇到过循环的事情吧?比如循环听歌。在程序中,也是存才的,这就是流程控制语句 while
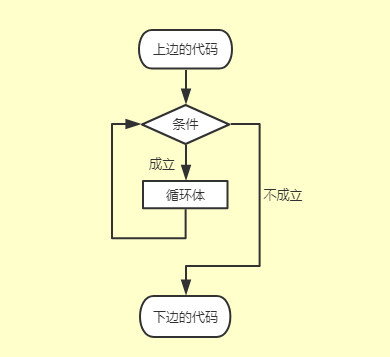
1、基本循环
while 条件:
# 循环体
# 如果条件为真,那么循环则执行
# 如果条件为假,那么循环不执行
2、break
break 用于退出当层循环
#-*- coding:utf-8 -*-
num = 1
while num <6:
print(num)
num+=1
break
print("end")
3、continue
continue 用于退出当前循环,继续下一次循环
#!/usr/bin/env python
#-*- coding:utf-8 -*-
num = 1
while num <6:
print(num)
num+=1
continue
print("end")
4、while else
while True:
if 3 > 2:
print('你好')
break
else:
print('不好')
while True:
if 3 > 2:
print('你好')
print('不好')
首先让用户输入序号选择格式如下: 0.退出 1.开始登录 如果用户选择序号0 就提示用户退出成功 如果用户选择序号1就让用户输入用户名密码然后进行判断,正确就终止循环,错误重新输入 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 用户可持续输入(用while循环),用户使用的情况: 输入A,则显示走大路回家,然后在让用户进一步选择: 是选择公交车,还是步行? 选择公交车,显示10分钟到家,并退出整个程序。 选择步行,显示20分钟到家,并退出整个程序。 输入B,则显示走小路回家,并退出整个程序。 输入C,则显示绕道回家,然后在让用户进一步选择: 是选择游戏厅玩会,还是网吧? 选择游戏厅,则显示 ‘一个半小时到家,爸爸在家,拿棍等你。’并让其重新输入A,B,C选项。 选择网吧,则显示‘两个小时到家,妈妈已做好了战斗准备。’并让其重新输入A,B,C选项。
 答案
答案
2.格式化输出
现在有个需要我们录入我们身边好友的信息,格式如下:
------------ info of MBH----------
Name : MBH
Age : 22
job : Teacher
Hobbie: 666
------------- end ----------------
我们现在能想到的办法就是用一下方法:
name = input('请输入姓名:') age = input('请输入年龄:') job = input('请输入职业:') hobby = input('请输入爱好:') a = '------------ info of MBH ----------' b = 'Name:' c = 'Age:' d = 'Job:' e = 'Hobby:' f = '------------- end ----------------' print(a+ '\n'+ b+ name+ '\n'+ c+ age+ '\n'+ d+ job+ '\n'+ e+ hobby+ '\n'+ f)
运行结果
------------ info of MBH---------- Name:meet Age:18 Job:it Hobby:3 ------------- end ----------------
name = input('请输入姓名:')
age = input('请输入年龄:')
job = input('请输入职业:')
hobby = input('请输入爱好:')
msg = '''
------------ info MBH----------
Name : %s
Age : %s
job : %s
Hobbie: %s
------------- end ----------------
'''
print(msg%(name,age,job,hobby))
我们但从代码的数量来看,这样就比那样的少,看到这里有细心的老铁们肯定在想%s这是啥玩意?
% 是一个占位, 回想下我们小时候给朋友占位子的场景,是的这个就是占位.那s又是什么呢? s代码的字符串类型;
具体详细参数如下,大家可以参考一下
|
|||||||||||||||||||||||
这样写完全没有问题,但是会不会比较繁琐呢,有些大佬肯定会想这不都实现了吗,还逼叨逼什么啊,那是没有体验过格式化输出有多霸道,我们现在来体验下霸道的姿势
3.运算符
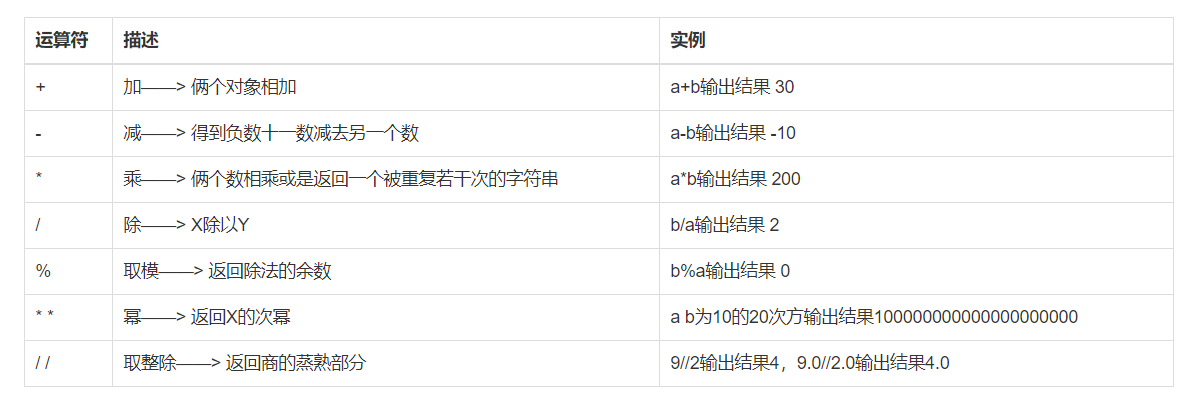
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
算数运算
以下假设变量:a=10,b=20
比较运算
以下假设变量:a=10,b=20

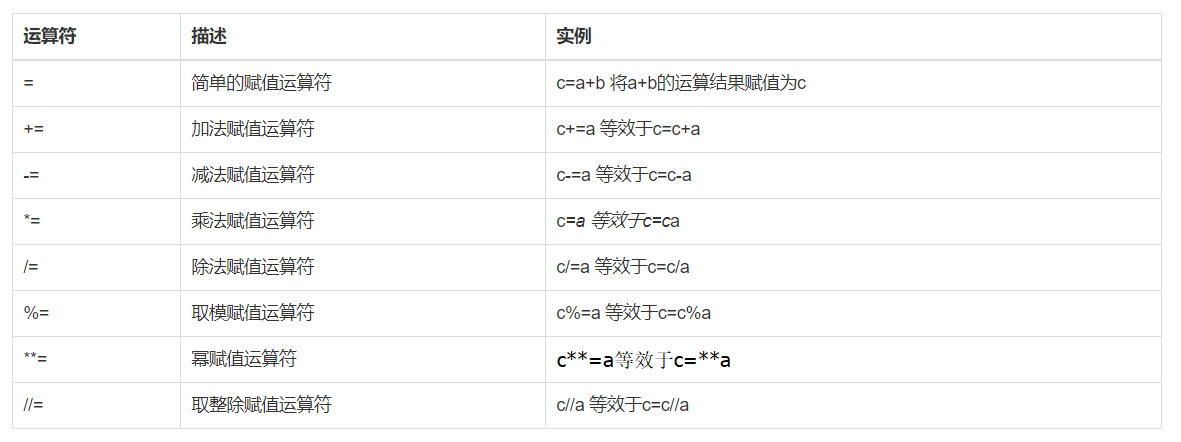
赋值运算
以下假设变量:a=10,b=20
逻辑运算

针对逻辑运算的进一步研究:
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
4.初识编码(一)
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
随着计算机的发展. 以及普及率的提高. 流⾏到欧洲和亚洲. 这时ASCII码就不合适了. 比如: 中⽂汉字有几万个. 而ASCII 多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境. 比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了.
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不支持英文肯定不行. 而英文已经使用了ASCII码. 所以GBK要兼容ASCII.
这里GBK国标码. 前⾯的ASCII码部分. 由于使⽤两个字节. 所以对于ASCII码⽽言. 前9位都是0
字母A:0100 0001 # ASCII 字母A:0000 0000 0100 0001 # 国标码
国标码的弊端:
只能中国用. 日本就垮了. 所以国标码不满足我们的使用. 这时提出了一个万国码Unicode一 开始设计是每个字符两个字节. 设计完了. 发现我大中国汉字依然无法进行编码.
只能进行扩充. 扩充成32位也就是4个字 节. 这回够了. 但是. 问题来了. 中国字9万多. 而unicode可以表示40多亿. 根本用不了. 太浪费了. 于是乎, 就提出了新的 UTF编码.可变长度编码
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536
注:此处说的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、
欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
UTF-16: 每个字符最少占16位.
GBK: 每个字符占2个字节, 16位.
单位转换
8bit = 1byte 1024byte = 1KB 1024KB = 1MB 1024MB = 1GB 1024GB = 1TB 1024TB = 1PB 1024TB = 1EB 1024EB = 1ZB 1024ZB = 1YB 1024YB = 1NB 1024NB = 1DB 常⽤到TB就够了