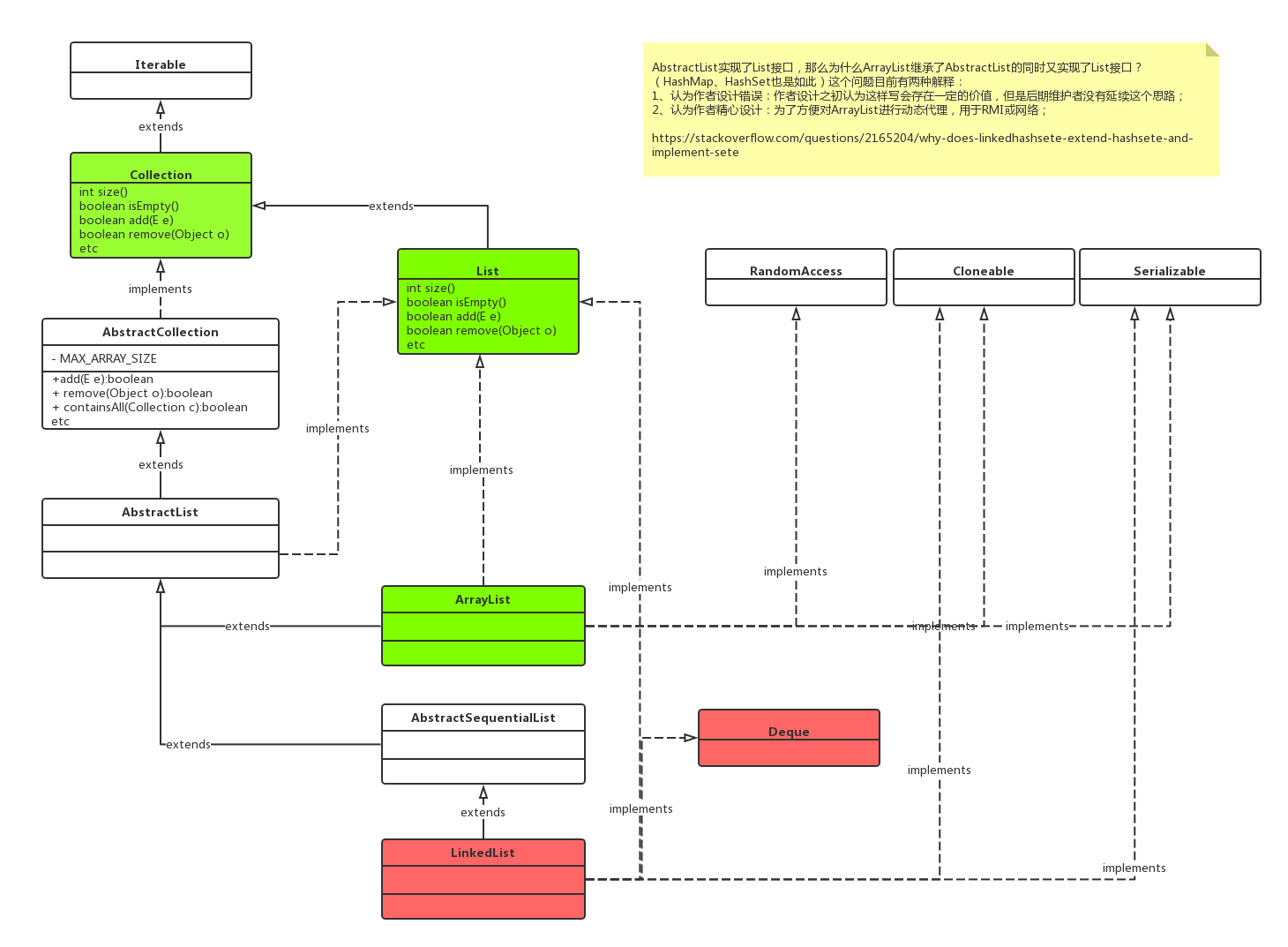
1、ArrayList本质
数组 + 动态扩容实现的数据列表。
private static final Object[] EMPTY_ELEMENTDATA = {};
// elementData初始为空数组 public ArrayList() { super(); this.elementData = EMPTY_ELEMENTDATA; } // 指定初始容量,不能为负数 // 如果能预估集合大小,建议初始化时指定容量,避免扩容,提升性能 public ArrayList(int initialCapacity) { super(); if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; }
初始为空数组,故每次添加元素时进行扩容判断,首次添加,默认初始化大小为10,见下文扩容内容。
private static final int DEFAULT_CAPACITY = 10;
2、主要属性
| private transient Object[] elementData | ArrayList实际维护的底层数组, 初始为空数组,元素为对象引用。虽然该属性是瞬态,但是ArrayList实现了Serializable接口,并内部自行实现了writeObjec和readObject序列化方法。见下文。 |
| private int size | elementData数组中有效元素的个数,并非elementData数组实际大小,扩容后使用null元素占位,即:每次add均+1。size参与元素的按索引检索。 |
3、主要特性
| 是否允许null元素 | 需要关注下源码中remove方法对null值的处理逻辑,见5 |
|
是否有序
|
是
|
| 是否线程安全 | 否 (Vector是线程安全的集合类 或 Collections.synchronizedList包装) |
| 是否允许重复元素 | 是 |
| 按索引插入、删除元素的效率低 | 这两类方法均涉及到数组的复制,数组个数越多,执行效率越低 |
|
顺序插入、检索(get)元素效率高
|
1、顺序插入只有触发扩容时才会进行数组复制,其余场景均连续添加数组元素即可;
2、按索引随机访问数组元素的效率高,数组在内存中连续的内存空间,cpu缓存会读入连续的内存空间,所以数组按下标寻址时都是在cpu缓存中进行,效率较高;
(题外:链表非连续存储,故在内存中寻址,效率不如数组);
|
4、插入元素
// 将指定元素e加入到elementData数组中
public boolean add(E e) { // 检查是否需要扩容,如果需要则执行扩容操作 ensureCapacityInternal(size + 1); // Increments modCount!! // 将新元素赋值给底层数组对应的size++的位置 elementData[size++] = e; return true; } // 将指定元素添加至指定索引的位置, // 1. index位置元素及其后所有有效元素(使用size计算)进行复制并从index+1处进行粘贴; // 2. 将element设置为index位置的元素; public void add(int index, E element) { // 检查index位置是否越界 rangeCheckForAdd(index); // 检查是否需要扩容,如果需要则执行扩容操作 ensureCapacityInternal(size + 1); // 完成元素的拷贝移动, 如: // elementData = [A, B, C, null, null, null, null, null, null, null] // add(1, D) // elementData = [A, B, B, C, null, null, null, null, null, null] System.arraycopy(elementData, index, elementData, index + 1, size - index); // 将新元素赋值给底层数组对应的索引位置 elementData = [A, D, B, C, null, null, null, null, null, null] elementData[index] = element; // 有效元素size+1 size++; }
5、删除元素
// 删除首次匹配到的指定元素
public boolean remove(Object o) { // 如果删除的元素是null,则不能使用equal判断,故此处进行分支逻辑处理 if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) // 使用equals判断对象内容是否相等 if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; } // 删除指定索引位置的元素 public E remove(int index) { // 检查参数索引值是否越界 rangeCheck(index); // 修改次数自增 modCount++; // 获取要删除的元素 E oldValue = elementData(index); // 从index+1处开始复制并在index处进行粘贴 // 如: elementData=[A, B, C, D] // 删除index=1位置的元素B,调用arrayCopy方法后, elementData=[A, C, D, D] // 赋值最后一个元素为null,等待gc回收,则 elementData=[A, C, D, null] int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); // size自减,将最后一个元素赋值为null,用于gc该多余元素 elementData[--size] = null; // clear to let GC do its work // 返回被删除元素的引用 return oldValue; }
6、动态扩容
// 内部动态扩容实现
// minCapacity为最小容量,即容纳有效元素所需的容量,add操作时minCapacity为size + 1/numNew
private void ensureCapacityInternal(int minCapacity) { // 首次add,底层数据为空数组,则minCapacity为10 if (elementData == EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } // 确认精确的新容量 ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity(int minCapacity) { modCount++; // 如果所需的容量大于当前实际容量,则进行扩容 if (minCapacity - elementData.length > 0) grow(minCapacity); } private void grow(int minCapacity) { // 当前实际容量 int oldCapacity = elementData.length; // 计算新容量,实际容量 * 1.5,1.5为时间与空间的权衡,扩容太大,则浪费空间,扩容太小,则发生频繁扩容,则耗费性能 int newCapacity = oldCapacity + (oldCapacity >> 1); // 新的容量比所需的容量小,即:现有容量扩容1.5倍后仍然不够,则使用所需容量进行扩容,当首次添加元素时,新容量为0,所需容量为10,则新容量为10 if (newCapacity - minCapacity < 0) newCapacity = minCapacity; // 如果新容量大于最大容量,则触发hugeCapacity操作 // MAX_ARRAY_SIZE为Integer.MAX_VALUE - 8, -8为防止内存溢出,见源码MAX_ARRAY_SIZE常量注释 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // 数组复制,根据新容量大小,进行扩容 elementData = Arrays.copyOf(elementData, newCapacity); } // java.util.Arrays中的copyOf实现 // 如:original = [0, 1, 2, ...., 9 ] 当前容量oldCapacity=10, 新容量newCapacity=10*1.5=15,则 // 1、创建一个容量为15的新数组copy, elementData = [null, null, null, ...., null] // 2、将原数组original元素复制到新数组copy中,返回新数组 copy = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, null, null, null, null] public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { // 开辟新数组,大小为newCapacity T[] copy = ((Object)newType == (Object)Object[].class) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); // 将已有数组original元素复制到新数组copy中 System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; } /** * 有些虚拟机数组对象中存在8个字节的对象头,所以此处-8目的为减少OOM的可能性 * 如果超过了MAX_ARRAY_SIZE,那么扩容至Integer.MAX_VALUE */ private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); // 最大扩容Integer.MAX_VALUE,即:整数上限值 return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
7、序列化
虽然ArrayList实现了Serializable接口, 但elementData为瞬态的,作者不希望使用默认的序列化方法对elementData进行序列化。原因为elementData包含占位元素,直接序列化后会导致序列化后的内容比较大,浪费空间及序列化的效率,所以ArrayList中重写writeObjec和readObject方法,writeObjec实现了对elementData中有效元素进行序列化的过程,readObject为反序列化过程。
序列化:ObjectOutputStream.defaultWriteObject序列化非 transient内容 -> ArrayList的writeObject序列化transient的elementData。参考 ObjectOutputStream。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; // 序列化非瞬态内容 s.defaultWriteObject(); // Write out size as capacity for behavioural compatibility with clone() // 序列化实际大小size s.writeInt(size); // 按size序列化底层数组元素 // Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); } if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } }
8、与Vector的比较
Vector的源码实现与ArrayList继承关系一致,底层均基于数组实现且初始默认长度均为10,实现方式基本相同,所以这里不再另起文章进行源码分析,这里对Vector与ArrayList的区别进行梳理:
1、Vector是线程安全,而ArrayList是非线程安全的;
Vector类中的关键方法使用了Synchronized进行修饰,多线程同步执行,保障安全性,自然也牺牲了性能。
public synchronized boolean add(E e) {
modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }
2、Vector允许自定义指定扩容增长因子,默认扩容增量100%,ArrayList扩容增量固定为50%;
public Vector() {
this(10);
}
public Vector(int initialCapacity) { this(initialCapacity, 0); } public Vector(int initialCapacity, int capacityIncrement) { super(); if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; this.capacityIncrement = capacityIncrement; } public Vector(Collection<? extends E> c) { elementData = c.toArray(); elementCount = elementData.length; // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, elementCount, Object[].class); } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); }
3、Vector的底层数组不是瞬态的且序列化只重写了writeObject方法;
// 未使用transient修饰
protected Object[] elementData;
// 重写writeObject方法与ArrayList不同 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // 获取缓冲中的持久化字段对象 final java.io.ObjectOutputStream.PutField fields = s.putFields(); final Object[] data; // 同步将capacityIncrement、elementCount添加至持久化字段对象中 //复制底层数组 synchronized (this) { fields.put("capacityIncrement", capacityIncrement); fields.put("elementCount", elementCount); data = elementData.clone(); } // 将复制后的底层数组添加至持久化字段对象中 fields.put("elementData", data); // 将持久化字段对象写入流 s.writeFields(); }
4、Vector具有一些特有的方法
public synchronized E firstElement() { ... }
public synchronized E lastElement() { ... } public synchronized void removeElementAt(int index) { ... } public synchronized void insertElementAt(E obj, int index) { ... } public synchronized void addElement(E obj) { ... } .......
9、迭代器、fail-fast和fail-safe
Iterator(迭代器):容器类通过实现Iterable接口来定义获取迭代器对象的方法,通过实现Iterator接口来定义一个迭代器。通过迭代器对象,使访问容器的代码逻辑从容器实现代码中剥离,使用者只需要通过迭代器的操作即可对容器进行遍历,无需了解容器的内部结构,消除了容器由于内部结构不同而导致遍历方式的差异,即迭代器模式的思想。
fail-fast(快速失败)
对于非并发容器当使用迭代器遍历时,当前线程或另一个线程通过调用容器的方法如add/remove等改变了容器结构,那么容器在迭代过程中会抛出ConcurrentModificationException运行时异常而终止后续迭代过程的机制。
下面通过ArrayList的源码来分析Iterator和fail-fast,ArrayList集成AbstractList抽象类,AbstractList继承AbstractCollection抽象类并实现了该抽象类的iterator方法:
// 操作计数
protected transient int modCount = 0; // 获取一个迭代器对象 public Iterator<E> iterator() { return new Itr(); } //迭代器类,AbstractList抽象类中的私有内部类,实现了Iterator接口 private class Itr implements Iterator<E> { // 下一个元素的索引 int cursor = 0; // 上一个元素的索引,当调用remove方法时重置为-1 int lastRet = -1; // 迭代器实例化时将期待的modCount值初始化为当前的modCount值,用于快速失败检查 int expectedModCount = modCount; // 判断是否存在下一个元素 public boolean hasNext() { // 下一个元素的索引不等于总的底层数组长度,则说明还有下一个元素 return cursor != size(); } // 获取下一个元素 public E next() { // 检查底层数组结构是否发生修改,即判断迭代器初始化时备份的expectedModCount的值和当前的modCount是否相等 // 不等,则抛出ConcurrentModificationException checkForComodification(); try { // 将当前下一个元素的索引赋值给i int i = cursor; // 获取下一个元素 E next = get(i); // 将当前下一个元素索引作为上一个元素索引 lastRet = i; // 重置cursor指向新的next索引 cursor = i + 1; // 返回next对象 return next; } catch (IndexOutOfBoundsException e) { // 如果数组越界则优先判断是否发生了并发修改,如果是优先抛出ConcurrentModificationException checkForComodification(); // 否则 抛出NoSuchElementException throw new NoSuchElementException(); } } // 迭代器对象的删除操作 public void remove() { // 迭代器对象未吊用过next()方法便调用remove方法的话,会抛出IllegalStateException if (lastRet < 0) throw new IllegalStateException(); // 并发修改异常判断 checkForComodification(); try { // 根据索引删除元素 AbstractList.this.remove(lastRet); // 下一元素索引减1 if (lastRet < cursor) cursor--; //重置上一元素/当前元素索引 lastRet = -1; // 更新 expectedModCount,所以单线程迭代过程中,通过迭代器对象的remove方法删除元素,不会导致并发修改异常 expectedModCount = modCount; } catch (IndexOutOfBoundsException e) { throw new ConcurrentModificationException(); } } // fail-fast检查 final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }
通过源码可以发现:
1、迭代器调用next()方法时才会进行fail-fast检查;
2、单线程场景,在迭代过程中通过调用容器对象自身的add/remove操作修改了modCount,那么在下次next()方法调用时会发生ConcurrentModificationException,所以可以使用迭代器对象自身的remove方法进行删除;
// 错误方式
List<String> list = new ArrayList<>(3);
list.add("a"); list.add("b"); list.add("c"); Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { // 第二次遍历时调用next()方法时,会抛出ConcurrentModificationException iterator.next(); list.remove(0); } // 正确方式 while (iterator.hasNext()) { iterator.next(); iterator.remove(); }
3、多线程场景,因为迭代器对象是线程私有的,也就是expectedModCount是线程私有的,线程一迭代遍历,线程二调用了迭代器的remove修改了容器对象的modCount,那么进行迭代遍历的线程一也会发生ConcurrentModificationException,所以可以使用CopyOnWriteArrayList容器,详见《CopyOnWriteArrayList源码分析》;
fail-safe(安全失败)
CopyOnWriteArrayList等JUC包下的容器都具有安全失败的特性,在迭代器初始化时快照容器内容,迭代遍历的是容器的内容的快照,所以其他线程对容器结构的修改不会被迭代器感知到,也就不会抛出ConcurrentModificationException。以CopyOnWriteArrayList源码为例:
// 迭代器对象获取方法
public Iterator<E> iterator() {
// 获取当前数组从索引为0的位置实例化一个迭代器对象 return new COWIterator<E>(getArray(), 0); } private static class COWIterator<E> implements ListIterator<E> { // 迭代器内部对原数组的引用进行了快照(浅拷贝),final修饰,构造函数中初始化,迭代器遍历操作针对该快照完成 private final Object[] snapshot; /** Index of element to be returned by subsequent call to next. */ private int cursor; private COWIterator(Object[] elements, int initialCursor) { cursor = initialCursor; snapshot = elements; } ..... // 该迭代器与ArrayList不同,不支持remove方法 public void remove() { throw new UnsupportedOperationException(); } // 不支持通过迭代器进行set public void set(E e) { throw new UnsupportedOperationException(); } // 不支持通过迭代器进行add public void add(E e) { throw new UnsupportedOperationException(); } }