前面两篇博客我们分别利用requests请求库抓取页面(链接https://blog.csdn.net/MG1723054/article/details/81604116)和利用selenium模拟浏览器来获取页面数据(链接https://blog.csdn.net/MG1723054/article/details/81630769),这些获取信息的方法也有弊端,对于requests请求库在抓取网页时候,得到的结果可能与浏览器中看到的不一样,这是因为requests获取的是原始的HTML文档,而现实的网页中,浏览器可能经过JavaScript处理后生成的结果,这些数据可能是ajax加jason载的,或者通过JavaScript渲染的;利用selenium抓取数据时候,主要的问题是效率不高。
下面我们主要来讨论通过分析ajax来获取json数据,获取需要的网址,利用requests模拟ajax请求,最后获得我们想要的数据。
这里,我们用搜狗美女网址为例,如图所示为网页源代码,在源代码中我们没有找到那些图片的url链接。

于是,我们打开开发者模式,如下图所示,点击network按钮,按F5,我们可以看到一系列的请求,我们在XHR中的preview看到一系列的美女图片的ID,以及或图片的url,下拉网页我们看到后面的图片出现时候,XHR请求就增加。然后我们分析不同链接的url的规律,
url=http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jspcategory=%E7%BE%8E%E5%A5%B3&tag=%E5%85%A8%E9%83%A8&start=15&len=15
url=http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jspcategory=%E7%BE%8E%E5%A5%B3&tag=%E5%85%A8%E9%83%A8&start=30&len=15
url=http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jspcategory=%E7%BE%8E%E5%A5%B3&tag=%E5%85%A8%E9%83%A8&start=45&len=15

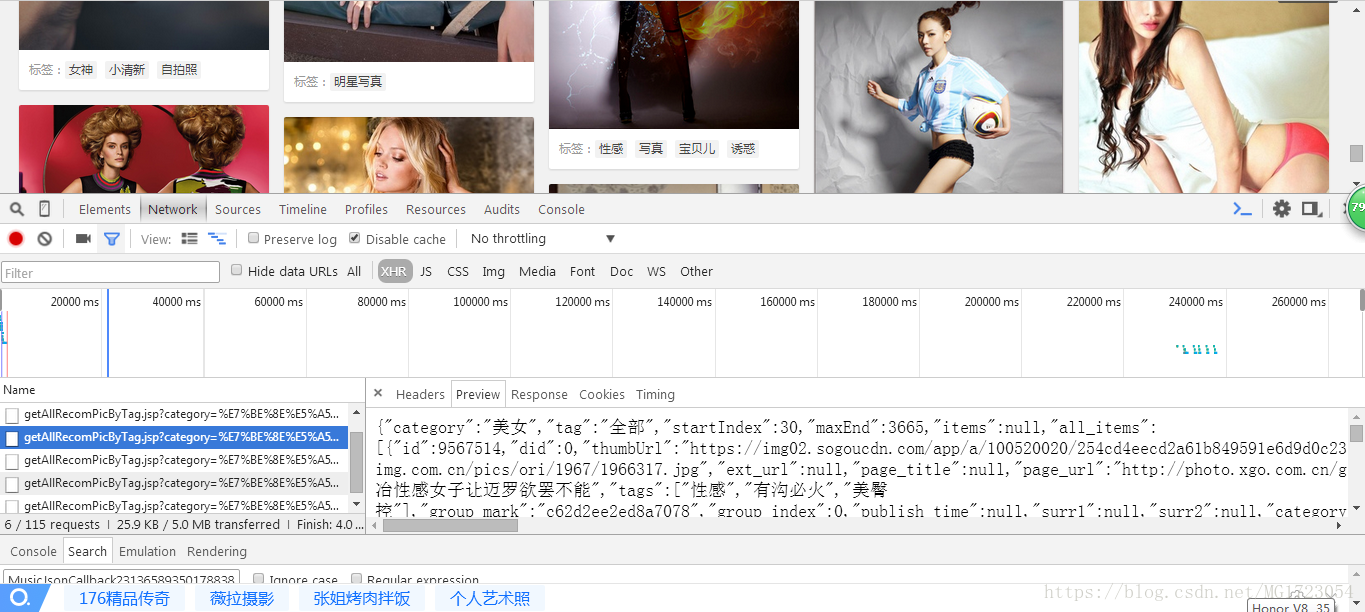
通过分析上面的链接,我们可以先发现对于不同的链接只是start数据改变,规律是15*n(n=1,2,3,),其他的数据均不改变,通过以上分析,我们给出代码,我们在代码里面详细分析每一个程序的意义
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a NJUer.
"""
import requests
import time
from urllib.parse import urlencode #网址编码
import json #导入json库
urls=[]
def image_json (url) :###请求库,利用requests请求构造的链接,然后转化为json格式,然后得到图######片的标题和图片链接。
response=requests.get(url,headers={'User-Agent':'Mozilla/5.0'})
data=json.loads(response.text)['all_items']
for m in range(len(data)) :
items={
'image_url':data[m]['thumbUrl'],'title':data[m]['title']
}
yield items
def image_download(item):###下载图片
resource=requests.get(item['image_url'])
item['title']=item['title'].replace('|','_')
item['title']=item['title'].replace('/','_')###改名,因为有些图片中有些字符不符合jpg
###图片命名规范
file='C:\\Users\\FangWei\\Desktop\\网络爬虫\\爬取酷狗美女图片\\'+item['title'][0:20]+'.jpg'
with open (file,'wb') as f:
f.write(resource.content)###将图片下载,放到指定文件夹
def get_image (offest) : ###get_image函数主要是构造需要的ajax链接
base_url='http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?'
data={'category':'美女',
'tag':'全部',
'start':str(offest*15),
'len':'15',}
url=base_url+urlencode(data) ###利用urlencode将字典拼接为一个网址链接
return url
def main(offest):
time.sleep(1)
infor=get_image(offest) #mian函数内部调用get_image函数
#time.sleep(1)
for item in image_json (infor):
image_download(item)
if __name__=='__main__' :
start=time.time()
for x in range(30): #设置爬取变量,设置30,根据上面分析表示可以爬取30*15张图片
offest=x
main(offest) #调用主函数main()
end=time.time()
times=end-start
print(times)
通过上面的代码,我们就可以完成我们所需要的图片,爬取的部分结果如下:
最后,我们可以利用进程中的进程池来提高爬取效率,针对该程序,时间缩短了30s左右,因为在里面加了休息一秒,所以结果有差别,如果将time.sleep(1)删除,两个结果运行时间差不多,这是因为爬取是密集型IO操作,利用进程对其效率提高不大,可以考虑线程和协程(python协程还不太成熟),这方面的只是我会在某个时候贴出来。
附:多进程源代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 5 15:43:59 2018
@author: NJUer
"""
# -*- coding: utf-8 -*-
import requests
from multiprocessing.pool import Pool
import time
from urllib.parse import urlencode
import json
urls=[]
def image_json (url) :
response=requests.get(url,headers={'User-Agent':'Mozilla/5.0'})
data=json.loads(response.text)['all_items']
for m in range(len(data)) :
items={
'image_url':data[m]['thumbUrl'],'title':data[m]['title']
}
yield items
def image_download(item):
resource=requests.get(item['image_url'])
item['title']=item['title'].replace('|','_')
item['title']=item['title'].replace('/','_')
file='C:\\Users\\FangWei\\Desktop\\网络爬虫\\爬取酷狗美女图片\\'+item['title'][0:10]+'.jpg'
with open (file,'wb') as f:
f.write(resource.content)
def get_image (offest) :
base_url='http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?'
data={'category':'美女',
'tag':'全部',
'start':str(offest*15),
'len':'15',}
url=base_url+urlencode(data)
return url
def main(offest):
time.sleep(1)
infor=get_image(offest)
for item in image_json (infor):
image_download(item)
if __name__=='__main__' :
start=time.time()
pool=Pool()
offest=[x for x in range(30)]
pool.map(main,(offest))
pool.close()
pool.join()
end=time.time()
times=end-start
print(times)
原创不易,如需转载,请注明出处和作者,谢谢。