一.多路复用
循环UDP服务器:
socket(...);
bind(...);
while(1)
{
recvfrom(...);
process(...);
sendto(...);
}并发TCP服务器:
socket(...);
bind(...);
listen(...);
while(1)
{
accept(...);
//if(fork(...)==0){
while(1)
{
read(...);
process(...);
write(...);
}
close(...);
exit(...);
//}
close(...);
}多路复用I/O的TCP服务器:
int use_select(int *readfd,int n)
{
fd_set my_readfd;
int maxfd;
int i;
maxfd=readfd[0];
for(i=1;i<n;i++)
if(readfd>;maxfd) maxfd=readfd;
while(1)
{
FD_ZERO(&my_readfd);
for(i=0;i<n;i++)
FD_SET(readfd,*my_readfd);
select(maxfd+1,&my_readfd,NULL,NULL,NULL);
for(i=0;i<n;i++)
{ if(FD_ISSET(readfd,&my_readfd))
{
/* 原来是我可以读了 */
we_read(readfd);
}
}
}
}poll\select\epoll都是同步I\O多路复用的机制,epoll和poll最大的区别在于mmap和epoll分解了poll函数。
1.epoll也是同步阻塞的。阻塞就是一个进程从用户空间向内核空间发起了I\O后进入休眠状态,之后一直等待结果产生再被唤醒。而非阻塞是一个进程在发起了I\O后不休眠,而是可以不断的进行其他操作然后定时轮询即可。轮询其实是很浪费CPU资源的。
等待队列就是因为同样等待一个信号的进程都存放进的那个队列。
2.异步通知:也就是fasync,就是让驱动程序去告诉应用底层硬件发生了什么事,而不是应用主动的去查询驱动。在驱动中需要定义一个fasync_struct来存放对应设备文件的信息,如fd和filp并交给内核处理,再用fasync_helper将fd、filp和定义的结构体传给内核。在异步队列里注册过的进程当kill_fasync信号出现时就会去找到对应的进程。
fasync_helper(fd,filp,mode,&dev->async_queue)
3.
a.用fcntl(fd,F_SETOWN,getpid());设置接收SIGIO信号的进程组
b.Oflags=fcntl(fd,F_GETFL);得到文件的标志位
c.fcntl(fd,F_SETFL,Oflags|FASYNC);当标志位改变驱动程序中的fasync()函数得以执行
d.signal(SIGIO,my_signal_func);if(dev->async_queue){
kill_fasync(&dev->async_queue,SIGIO,POLL_IN);
}
POLL_IN指设备可读,POLL_OUT指设备可写,可读或可写时将SIGIO信号发送给内核。test_fasync(-1,filp,0);当设备关闭时使用test_fasync将设备删除。
原子上下文:不允许内核访问用户空间、不允许内核睡眠、不允许调用任何可能引起睡眠的函数。
#define in_irq() (hardirq_count()) //在处理硬中断中
#define in_softirq() (softirq_count()) //在处理软中断中
#define in_interrupt() (irq_count()) //在处理硬中断或软中断中
#define in_atomic() ((preempt_count() & ~PREEMPT_ACTIVE) != 0) //包含以上所有情况,在禁用抢占时会返回错误结果。临界区是轻量级的锁,通常不会产生内核对象,内部实现是基于自旋锁与事件对象等待来实现的,互斥体和信号量都是内核对象,效率不如临界区。互斥体是基于上锁机制而信号量是基于信号机制。互斥体和信号量可以跨线程,且都是基于引用计数,信号量可以用于同步。
互斥体和临界区是可重入的,大概是说一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行而无需重新获得锁。
自旋锁最多只能被一个可执行线程持有,如果一个执行线程试图获得一个已经被持有的自旋锁,那么该线程就会一直进行忙循环-旋转-等待锁。自旋锁可以防止多于一个的执行线程同时进入临界区。适合短时间内的轻量级加锁。长时间或可被抢占时最好使用互斥体。自旋锁可在中断上下文中加锁。
seqlock用于读多写少的情况,常用于时钟的获取,使用sequence++的奇偶方式判断读写状态。
RCU锁,一种改进的读写锁,使用read-copy-update,适用于网络路由表的查询更新、设备状态表的维护、数据结构的延迟释放以及多径I/O设备的维护。读随意,不过写的开销较大。
异步的应用程序和驱动程序:
https://blog.csdn.net/psvoldemort/article/details/21184525
wait_event_iterruptable()使进程休眠
wake_up_interruptable()唤醒休眠的进程
request_irq()注册中断处理函数
free_irq()注销中断处理函数
local_irq_disable()
local_irq_enable()本地CPU的中断情况
disable_irq()人为关闭某个中断
enable_irq()人为打开某个中断strace -p 2624查看进程的系统调用
redis端口号。。。这个面试被问到贼拉拉难受。端口号6379
https端口号443
FTP端口号21
SSH、SCP、端口重定向端口号22
Telnet端口号23

二.笔试问题总结杂记
数据库(主从数据库一读一写)+服务器+消息队列+分布式服务复用业务+(HTTPS+json+web(cookie+session)+App后台(token))
消息队列可以将并行请求变为串行情求,常见的消息队列软件有redis、RabbitMQ、ActiveMQ、ZeroMQ
token情况:收到用户的URL请求和表单body信息,后台验证正确后随机生成一个token,该token与数据库信息相对应,数据库将token返回给App,为了不在网络上传输token我们使用了MD5算法将token和信息转化成一个sign,时间戳也ok如果数据库token值与MD5的sign结果相同则继续下一步操作。
URL上会包含uid和sign。
会使用推模式以及稍长时间的轮询。
原始套接字的使用:
setuid(getpid());//只有管理员能用原始套接字,原始套接字可以自定义TCP内容。
10ms比较接近windows的调度时间片。
慢查询:慢查询是指当SQL语句超过long_query_time阈值时,将这些语句记录在查询日志中。
索引
拆分表:纵向与横向
B树中每一个节点都存储了信息,而B+树只有叶子节点存储了信息。B树每一个节点都包含key和value,经常访问的元素可能离根节点更近,访问也更迅速。B+树的内部结点不包含数据信息,数据存放更加紧密,B+树遍历只需遍历叶子结点,由于数据顺序排列并且相连便于区间查找和搜索。
数据库的对象有表,索引,视图(看上去与表一样但是上面限制了用户访问的信息),图表,缺省值,规则,触发器,用户,函数等。
java调优命令:
1.jps用于查看有权访问的hotspot虚拟机的进程。jps -v可以查看虚拟机启动时显示指定的参数列表。
2.jstat测量Java hotspot虚拟机的性能统计信息,包括类装载、内存、垃圾收集、JIT编译等运行数据。
3.jmap查看进程内存信息。
4.jhat查看堆复制信息,是平台独立的。
5.jstack用于打印出给定的java进程id或core file或远程调试服务的Java堆栈消息。是线程快照。
6.jinfo用于查看正在运行的java应用程序的扩展参数(JVM中-X标示的参数),甚至支持在运行时修改部分参数。
jmap将信息dump到文件中之后使用jhat进行堆内存分析。
java程序崩溃形成core文件,如果运行的java程序hung死则可以用-F强制打出stack。
dump文件中有:
死锁 DeadLock !
执行中Runnable
等待资源Waiting on condition !
等待获取监视器Waiting on monitor entry !
暂停Suspended
对象等待中Object.wait()
阻塞Blocked !
停止Parked
sleep来自Thread类,wait来自Object类。Thread.Sleep(0)的作用是触发操作系统立刻重新进行一次CPU竞争。wait、notify、notifyAll只能在同步块中使用,sleep必须捕获异常。synchronized关键字用于保护共享数据,避免其他线程对共享数据进行存取。
sleep不出让系统资源,没有释放锁。而wait出让了系统资源,释放了锁,但没有释放同步资源,使得其他线程可以同步控制块或方法。
多线程共享堆内存,效率比多进程要好。
Wait\Notify\NotifyAll可用于线程间通信关于资源锁的状态。
Java的每个对象都有一个锁(monitor,也被称为监视器)。
sleep()和yield()都是静态方法,可以在当前正在执行的线程中工作。
保证线程同步的方法有:同步,原子类,并发锁,volatile,使用不变类和线程安全类。
阻塞队列是java collections框架的一部分,用于实现生产者消费者问题。
索引:
1.有索引的好处是搜索比较快但是在有索引的前提下进行插入更新操作会很慢。因此当查询操作比更新频繁时需要建立索引。
2.不要在值较少的字段上建立索引比如性别。
3.表的主键和外键必须有索引。
4.经常出现在where子句中的子段,特别是大表的字段应该建立索引。
5.索引应该建立在小字段上,不要在大的文本字段甚至超长字符上建立索引。
6.优先考虑where和order by涉及的列上建立索引。
7.避免对where子句中的字段进行null判断,否则会放弃索引而进行全表扫描。where numis null//应该给num赋0值。
8.避免在where子句中使用!=或<>操作符。
9.避免在where子句中使用or来连接条件。
如:select id from t where num=10 or num=20可以这样查询:select id from t where num=10 union all
select id from t where num=20
10.in和not in慎用
select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 3
11.避免like '李%',这个也是走全表扫描。
12.避免在where子句上对字段进行表达式操作和函数操作。
13.用where子句替换having子句,用exists代替in。
14.当索引列有大量数据重复时SQL查询不会去使用索引。
15.一个表上的索引最好不要超过6个。只能有一个聚簇索引,不能有多个非聚簇索引。
create (clustered) index mycolumn_index on mytable(mycolumn) (with allow_dup_row) drop index mytable.mycolumn_index
%yue%,由于在yue前加上了%号,因此这是一个全表查询。
快速排序每轮都有一个partition归位
希尔排序每轮都排好了步长的大小
选择、希尔、堆排、快排都是不稳定的
ip link指令用于第二层链路层设置网卡。
ip address指令用于第三层也就是网络层的设置。
ip route指令用于路由器的设置。
判断两个IP是否在同一个网段:
A类地址:0.0.0.0--127.255.255.255
B类地址:128.0.0.0--191.255.255.255 2^7开始
C类地址:192.0.0.0--223.255.255.255 2^7+2^6开始
D类地址:224.0.0.0--239.255.255.255 2^7+2^6+2^5开始
E类地址:240.0.0.0--247.255.255.255 2^7+2^6+2^5+2^4开始
链表去重:
list<int> ll;
ll.push_back(xx);
ll.sort();
ll.erase(unique(ll.begin(),ll.end()),ll.end());list的erase使用注意:
list<int>::iterator itList=ll.begin();
for(;itList!=ll.end;)
{
list<int>::iterator it=itList++;//先赋值再递增
ll.erase(it);
}
查看数组信息:设置断点,点击数组(链表)名称然后右键选快速监视(quickwatch),添加需要查看的个数然后点击数组前的+号,就可以看到了。
Hash是vector上接链表。unordered_set和unordered_map是基于hash的set和map实现,而set和map是基于RBTree实现的。如果没有排序需求只是为了快速的查找和删除那么使用unordered即可。主要在于定义
hash<value>和equal_to<value>
template<class key,
class Hash=hash<key>,
class Pred=equal_to<key>,
class Alloc=allocator<key>
>class unordered_set;
struct myHash
{
size_t operator()(pair<int,int> __val)const
{
return static_cast<size_t>(__val.first*101+val.second);
}
};
int main()
{
unordered_set<pair<int,int>,myHash> S;
S.insert(make_pair(x,y));
}
序列式容器:Vector、List(基于BiDirectional Iterator)->sList(基于Forward Iterator)->ArrayList\LinkedList、Deque->queue\stack、max-heap->priority_queue。heap可基于array|vector|list来实现。
vector便于read、list便于write。
关联式容器:map、set、multimap、multiset
set和map键值都不能随意更改,但map可以更改key对应的value。
set和multiset:
set只允许插入key,不允许键值重复。比较器默认是less,分配器默认是alloc。
multiset允许键值重复,底层调用的是RBTree的insert_equal函数,而set调用的是RBTree的insert_unique函数。
set可以进行交集、差集、并集运算
Set<String> result=new HashSet<String>();
Set<String> set1=new HashSet<String>(){
{
add("王者荣耀");
add("英雄联盟");
add("穿越火线");
add("地下城与勇士");
}
};
Set<String> set2=new HashSet<String>(){
{
add("王者荣耀");
add("英雄联盟");
add("魔兽世界");
}
};
result.clear());
result.addAll(set1);
result.retainAll(set2);
system.out.println("交集:"+result);
result.clear());
result.addAll(set1);
result.addAll(set2);
system.out.println("并集:"+result);
result.clear());
result.addAll(set1);
result.removeAll(set2);
system.out.println("差集:"+result);ConcurrentHashMap是分段的,相比于HashTable实现了锁分离技术。使用多个子哈希表,允许多个读操作并行,读操作不需要加锁,保证HashEntry几乎是不可变的,底层将key-value当成一个整体进行处理,底层采用一个Entry[]数组,当需要取出一Entry时需要根据key的hash算法找到其在数组中的存储位置,再根据equals方法从该位置上取出该Entry。
ArrayList是List接口的可变数组非同步实现,采用fail-fast机制,面对并发的修改时迭代器会完全失败,数组扩容时将旧元素拷贝到一份新的数组中,新数组容量增长是旧数组的1.5倍,remove方法会让下标到数组末尾的元素向前移动一个单位,将最后一位置空,方便GC。
LinkedList是List接口的双向链表非同步实现的。双向链表的结点对应类Node的实例,查找是折半查找。
HashMap是基于哈希表的Map接口的非同步实现,底层使用数组实现,数组中每一项是一个单向链表,当链表长度大于一个阈值时转化为红黑树,这样可以减少链表查询时间。采用fail-fast机制有一个modCount来记录修改情况,迭代器初始化是有一个expectedModCount,两者不对则说明有外部线程进行了修改,立马抛出异常。
typedef multiset<int,greater<int>> intSet;
typedef multiset<int,greater<int>>::iterator itSet;
int FindLeastKth(const vector<int>& data,intSet& LeastNumber,int k){}
priority_queue<int> Q;//默认为最大值优先
priority_queue<int,vector<int>,greater<int>> Q1;//最小值优先稳定性的好处:第一次排序的结果可以被第二次排序所使用
哪些排序是稳定的:
插入排序中:直接插入和折半插入
交换排序中:冒泡排序
归并排序和基数排序
哪些是不稳定的:
插入排序中:希尔排序
选择排序中:直接选择和堆排序
交换排序中:快速排序
快速排序每一轮都有一个数字归位。
希尔排序每一轮都是只与之后的步长数比较。
归并排序(二路)第一轮两两排序,第二轮四个排,第三轮八个排,如果有九个必须用到十六路归并,也就是四轮。
基数排序个位数先排序,再是十位数排序
FIFO对于已存在的页面不改变结构,而LRU会对已存在的界面移至队列头。
突破反爬虫代理限制的方法:
正常的时间访问路径:time.sleep(random.choice(range(1,3)))
使用多个代理IP
合法cookie
url headers request response content pattern ip_page ip_array.extend(ip_page) time.sleep
管道:无名管道用于具有亲缘关系的进程之间,有名管道叫named pipe或FIFO,可以用函数mkfifo()创建。管道通过VFS索引节点指向file结构,是一次性读操作,通过锁,等待队列和信号来控制。
1.匈牙利算法:给每个男生找出最适合的匹配妹子的算法。求最大匹配问题。
bool find(int x){
int i,j;
for (j=1;j<=m;j++){ //扫描每个妹子
if (line[x][j]==true && used[j]==false)
//如果有暧昧并且还没有标记过(这里标记的意思是这次查找曾试图改变过该妹子的归属问题,但是
没有成功,所以就不用瞎费工夫了)
{
used[j]=1;
if (girl[j]==0 || find(girl[j])) {
//名花无主或者能腾出个位置来,这里使用递归。
girl[j]=x;
return true;
}
}
}
return false;
}
for (i=1;i<=n;i++)
{
memset(used,0,sizeof(used)); //这个在每一步中清空
if find(i) all+=1;
}
2.着色问题:冲突时间情况下的分配,使用DFS递归。
#define MEETING 5
#define NO_COLOR 0
#define MAX_COLOR 6
// 'N' = NONE 'R' = Red 'G' = Green 'B' = Blue 'Y' = Yellow 'W' = White 'M' = MAX
char colors[MAX_COLOR + 1] = {'N', 'G', 'R', 'B', 'Y', 'W', 'M' };
// A : { 1 - 2 - 3 }
// B : { 1 - 3 - 4 }
// C : { 2 - 3 }
// D : { 3 - 4 - 5 }
// E : { 1 - 4 - 5 }
int meetings[MEETING][MEETING] = { { 0, 1, 1, 1, 1 },
{ 1, 0,1, 0, 0 },
{ 1, 1, 0, 1, 1 },
{ 1, 0, 1, 0, 1 },
{ 1, 0, 1, 1, 0 } };
int result[MEETING] = {NO_COLOR, NO_COLOR, NO_COLOR, NO_COLOR, NO_COLOR };
bool check(int meeting, int color)//坏检测,循环continue
{
int i = 0;
for (i = 0; i < MEETING; i++)
{
if ((meetings[i][meeting] == 1) &&(color == result[i]))//当值为1时颜色而颜色相等
,则说明检测到不对应的颜色。
{
return true;
}
}
return false;
}
void compute()
{
int i = 0, j = 0;
for (i = 0; i < MEETING; i++)
{
if (result[i] == NO_COLOR)
{
for (j = NO_COLOR + 1; j < MAX_COLOR; j++)
{
if (check(i, j))//如果检测到他们之间相连并且颜色值相同,则使用
continue让颜色值向前加一。如果相连且颜色不相同,则赋上颜色的值并跳出这个MEETING。
continue;
else
{
result[i] = j;
break;
}
}
}
}
}
void print()
{
int i = 0;
for (i = 0; i < MEETING; i++)
{
cout << i << ":" << colors[result[i]] << " ";
}
cout << endl;
}三.生产者消费者锁的问题&MESI
使用上condition_variable头文件,常与unique_lock一并使用。
如果是mutex则两个线程不能同时工作,因此semaphor有时更好。
std::mutex mut;
std::condition_variable empty,full;
std::queue<int> Q;生产者:
std::unique_lock<std::mutex> lk(mut);
empty.wait(lk);
full.notify_all();
lk.unlock();
消费者:
std::unique_lock<std::mutex> lk(mut);
full.wait(lk,[&](){return flag==id;});
empty.notify_one();
full.notify_all();以下内容取自:https://www.cnblogs.com/aiheyiwen/p/4925810.html
P(S)意为占用则信号量减一,如果为0则说明刚好分配完全,如果为负数则说明当前有多少人在等待使用。
V(S)意为释放,S一样的意思。
也就是进入临界区之前要对互斥进程使用P操作,以免抢占资源。
//a.多个生产者,多个消费者,一个公共缓冲区(生产者先生产,消费者后消费,两者互斥使用缓冲区即可)
//生产者
{
生产产品
P(m)//保证消费者无法再生产
产品送往buffer
V(n)//唤醒消费者
}
//消费者
{
P(n)//保证有产品可消费
从buffer取走产品----与buffer相关操作一定要有P(m)阻止生产者生产
V(m)//唤醒生产者继续生产
消费产品
}
//b.一个生产者,一个消费者,无数个公共缓冲区
//生产者
{
生产产品
P(m)//阻止生产者消费
产品送至buffer
V(m)//继续生产产品
V(n)//唤醒消费者
}
//消费者
{
P(n)//保证有产品可消费
P(m)//阻止生产者消费
从buffer取出产品
V(m)//唤醒生产者继续生产
消费产品
}环形缓冲区也就是多添加一个P(count)
以下内容取自:https://blog.csdn.net/liuxuejiang158blog/article/details/17301739
queue的push和pop接口中的pop改为try_pop()和wait_and_pop()。
private中的数据结构需要增加一个
mutable std::mutex mut;
std::condition_variable data_cond;//使用和上面一样,lock_guard<mutex> lk(mut);
push里是data_cond.notify_one();
pop里是data_cond.wait()
//这里使用到shared_ptr主要问题在于此时的队列首元素可能是不确定的,
std::shared_ptr<T> res(std::make_shared<T>(data_queue.front()));
data_queue.pop();
return res;//push、pop、pop_front时都需要独占锁
以下内容取自:https://blog.csdn.net/ljh081231/article/details/19342963
关于CAS、ABA、无锁队列,这里用的是CAS中使用的总线锁。
生产者先申请一个slot,用
CAS(&claimSequence,slot-1,slot);执行成功的这个生产者可以获得这一slot。
生产者占好位后进行发布。
CAS(&cursor,slot,slot-1)消费者可以消费这一区段的物品,并且需要跟踪避免一次性生产的值超过了环形队列的大小。
std::mutex可以实现跨平台的互斥锁,std::atomic_flag类才是真正的无锁实现,此类没有lock、unlock、try_lock等接口,只有test_and_set和clear,使用automic_flag可以方便的实现跨平台的旋转锁,效率比mutex高出很多,但同时CPU的使用率也高出很多,我们可以在加锁时按旋转锁的方式尝试一定次数,如果指定次数加锁失败则转为调用等待。
MESI协议:
M是被修改,与主存不一致
E是独享的,单一CPU,未被修改,可转为M
S是共享的,多CPU,未被修改,可转为M
I是无效的,有其他CPU对它进行修改则无效
四.网络部分
top查看系统资源情况
netstat查看网络相关情况
ICMP、ARP、RARP是属于网络层的协议,网络层还有IP、IGMP、RIP、OSPF、BGP、IS-IS、IPsec、NAT(NAPT由于涉及到端口号按理是属于网络+传输层)
DHCP是应用层协议,动态主机配置协议保证任何IP同一时刻只能有一台DHCP客户机所使用,可以给用户分配永久固定的IP地址。(应用层的协议有DNS、FTP、Gopher、POP3、SIP、SMTP、SNMP、SSH、TELNET、TLS、RPC、SOAP、GTP、NTP、STUN、SDP、RTSP、XMPP(基于XML)、NNTP、IRC等等)
组播是组播路由器借助组播路由协议为组播数据包建立树形路由,组播源只发送一次。
IGP内部网关协议:
RIP是距离矢量路由选择协议,度量是跳数
OSPF是链路状态路由选择协议,度量是带宽和延迟,优势在于无环,收敛速度快,hello报文的邻居发现协议,支持基于接口的明文和MD5验证。缺点在于负载均衡能力较差,配置复杂。
EIGRP则是解决了负载均衡的问题。
EGP外部网关协议:
BGP
隧道技术实际上是用一种网络层的协议来传输另一种网络层协议,基本功能是加密和封装,VPN:封装是指用来创建、维持和撤销一个通道,加密是指对流经通道的数据进行加密,来实现VPN的安全性和私有性。
SNMP是简单网络管理协议,他有一个MIB管理信息库,每个产品可以给自己的品牌申请一个MIB。
一个函数是一个线程,同一个线程保证原子执行顺序。
网桥用于局域网之间的连接,有令牌环网段和局域网网段,透明网桥通过自学习(适合以太网,也叫生成树网桥,他们选举ID最小的网桥为根网桥生成一颗生成树使得每两个点只有一条路径可达且无环)而源路由网桥通过广播(适合令牌环,),通过转发、存储、自学习等方式,有混杂接口可以处理不同的帧信息。
虚拟机中有bridge、nat、host-only等模式,其中nat+dhcp最为容易配置,但局域网内无法访问,而bridge局域网内其他用户可访问。docker中一般开放前端端口,后端端口只暴露给前端端口。前端一个容器,后台一个容器。
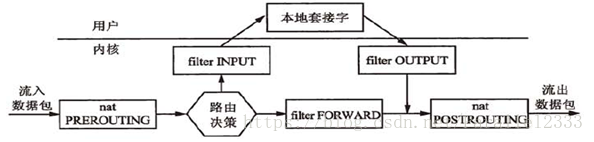
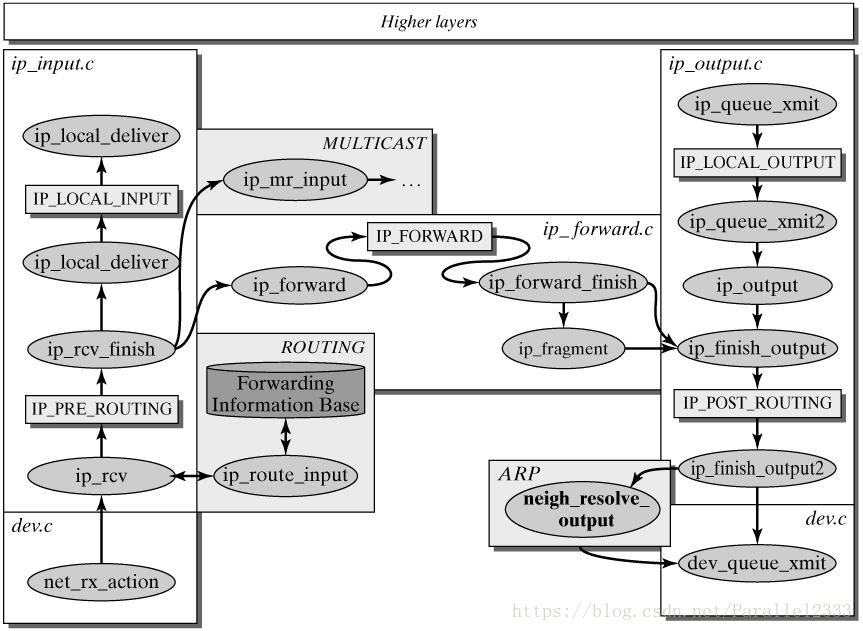
iptables命令:prerouting1->路由决策1->input1->forward2->output1->postrouting2
iptables -A INPUT -p tcp --dport 22 -j ACCEPT等价于有一条数据流想进入,目的端口为22
iptables -A INPUT -p tcp --sport 22 -j ACCEPT等价于有一条数据流想进入,来源于对方的22端口
iptables -A INPUT -s 192.168.0.3 -p tcp --dport 22 -j ACCEPT//SSH功能
有napt:iptables -t nat -A PREROUTING -p tcp --dport 21 -d 211.101.46.253 -j DROP
iptables -t nat -A PREROUTING -d 202.96.129.5 -j DNAT 192.168.1.2netfilter架构就是在整个网络流程的若干位置防止了一些监测点hook,每个监测点上登记一些处理函数。这
些处理函数返回NF_ACCEPT\NF_DROP\NF_STOLEN\NF_QUEUE\NF_REPEAT
sk-buff处理:
alloc_skb:分配一块sk-buff内存
skb_reserver:写指针向后移动到一个位置p,确定为数据包尾部,自始,写指针开始从该位置前移封装数据包
skb_push:写指针前移n,更新数据包长度,从它返回的位置可以写n个字节数据-即封装n字节的协议
skb_put:写指针移动到数据包尾部,返回尾部指针,可以从此位置写n字节数据,同时更新尾指针和数据nf_ip_checksum
先router cache、再router table、再邻居结构+路由结构、再ARP查找。
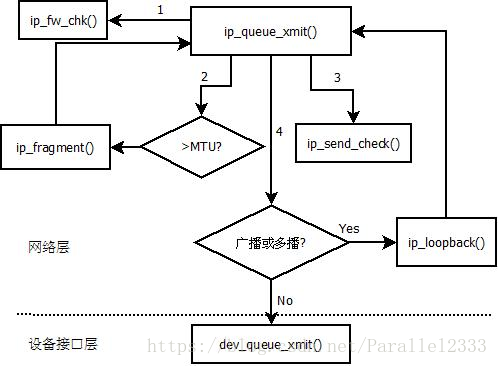
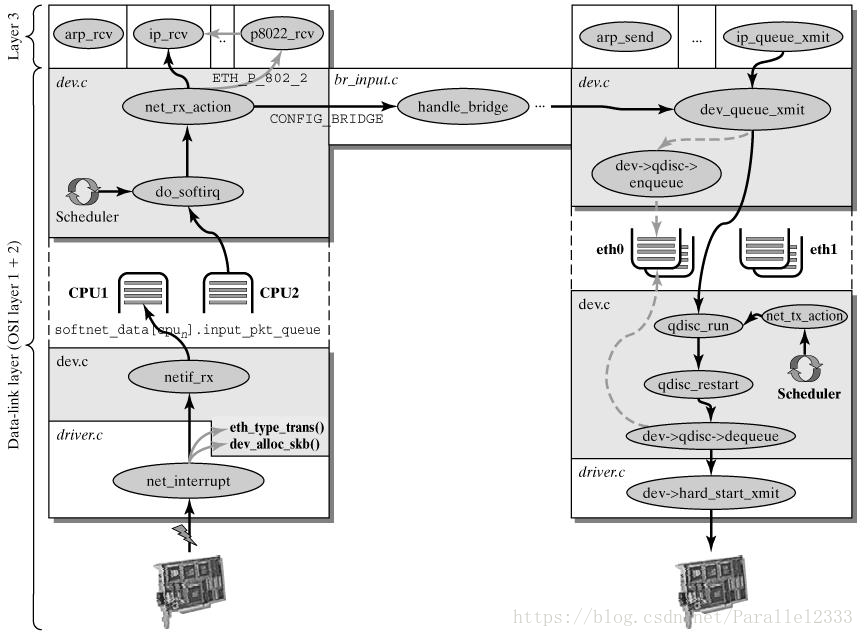
图片转载自:https://blog.csdn.net/CODINGCS/article/details/77803983
这个部分有一个重点:prerouting->路由决策->forward->postrouting
或prerouting->路由决策->input->系统内核->output->postrouting
prerouting和postrouting用于处理nat的情况。
当有input进来时系统会产生硬件中断。
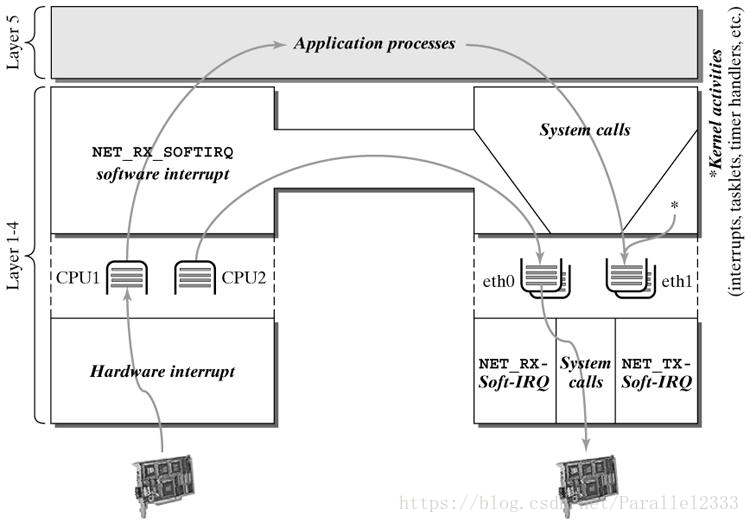
五.redis专题:
1.expire key seconds设置一个键的生存时间,persist取消时间限制,set会刷新生存时间
2.watch key观察一个值如果该值被修改之后的对该key的单个或multi行为都不会执行
3.multi一次性执行一个事务transact
sort:sadd set 1 4 5 2 3 9 10 -1;sort set;
sort set2 alpha:排列数字+字典序
sort set2 alpha desc limit 开始位置 个数4.散列存储:
sadd set a b c d e
hset a time 5 title hello
hset b time 1 title world
hset c time 7 title this
sort set by *->time get *->title //by意为key->field5.任务队列:lpush和rpop(brpop阻塞队列输出,brpop list 0意为超时时间设置为0,不限制等待时间)
6.消息队列:
brpop list 0;
lpush list hehe;
brpop list 0;
//(结果为"list""hehe")
7.优先级队列:brpop接收多个键,只要有一个键有元素就会pop出来
brpop list1 list2 0;
lpush list2 this;
brpop list1 list2 0;
//(结果为"list2""this")brpop list2 list1 0//设置了list2优先级大于list1,只要list2存在值则优先输出list2,否则输出list1.8.发布/订阅:
publish channel1 hi//(消息不会持久化也就是订阅读不到订阅之前的数据)
subscribe channel1//去读消息
publish channel1 mina客户端和redis之间使用TCP连接,如果上一条不被执行那么无法执行下一条。redis底层通信协议对管道提供了支持,通过管道可以一次性发送多条命令,并在执行完后将结果一次性返回来降低时延。
RDB持久化处理
AOF记录每次的写操作,不适用于备份,RDB是快照形式,适合快速还原到某一点。
Redis的五个数据结构的底层实现:
参考:https://www.cnblogs.com/jaycekon/archive/2017/01/02/6227442.html
数据库的键有字符串对象
数据库的值可以是字符串对象,列表对象,哈希对象,集合对象,有序集合对象。
1.字符串结构(字符串)
SDS动态增长,不是像C那样预先申请空间会出现溢出、覆盖等现象,而是记录了当前buffer的已用、未用的buffer长度,当free不够预增长时并且len小于1MB时,free申请和len一样的大小。当len>1MB时,free只申请1MB。也就是free最多申请不超过1MB。因为用len记录长度因此可以存储二进制文件而不像C那样局限在了以\0结尾的文本数据。
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
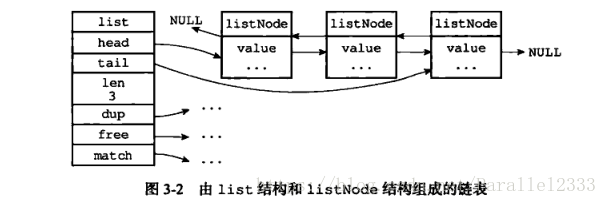
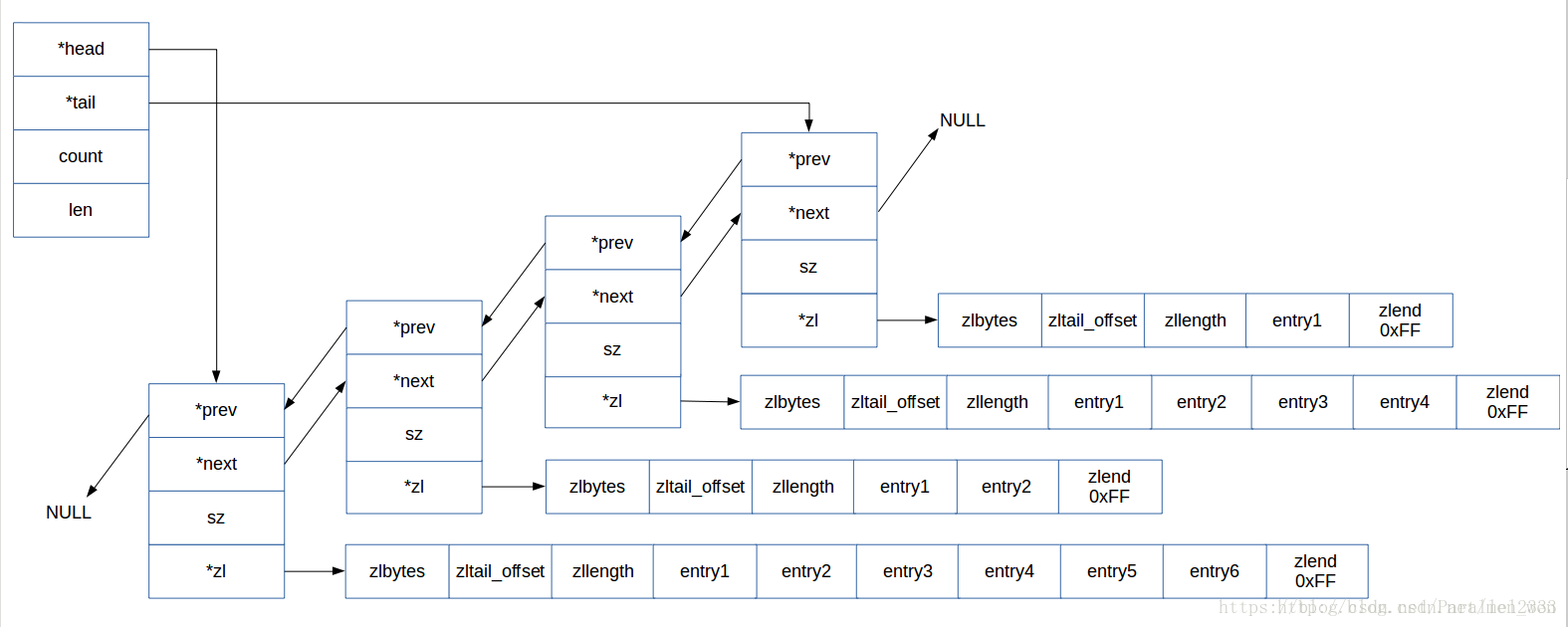
}; 2.链表结构(列表)
这里是用链表实现列表的功能,如LPUSH
typedef struct listNode{
struct listNode *prev;
struct listNode * next;
void * value;
}
typedef struct list{
//表头节点
listNode * head;
//表尾节点
listNode * tail;
//链表长度
unsigned long len;
//节点值复制函数
void *(*dup) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match)(void *ptr, void *key);
}
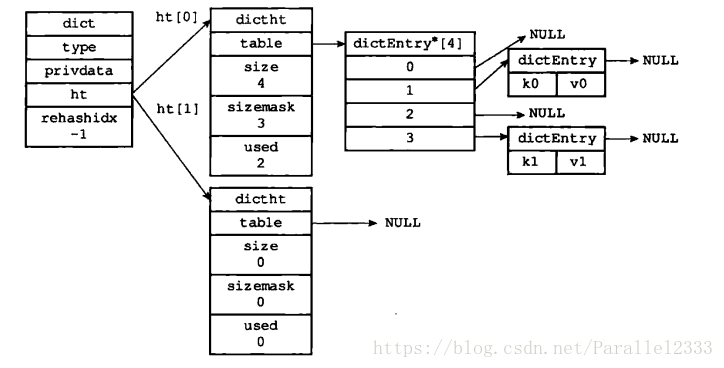
3.字典(哈希)
用哈希来实现,字典主要用于关联数组或映射。SET msg "hello world"就是一个字典形式的数据。
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}
struct dictEntry *next;
}
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privedata;
// 哈希表
dictht ht[2];
// rehash 索引
in trehashidx;
}
redis在满的时候采用链地址法,也会进行rehash让哈希结构在一个合理的负载因子上,哈希表需要进行压缩或者扩展操作。
渐进式rehash 的详细步骤:
a、为ht[1] 分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
b、在几点钟维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash 开始
c、在rehash 进行期间,每次对字典执行CRUD操作时,程序除了执行指定的操作以外,还会将ht[0]中的数据rehash 到ht[1]表中,并且将rehashidx加一
d、当ht[0]中所有数据转移到ht[1]中时,将rehashidx 设置成-1,表示rehash 结束
4.跳跃表(有序集合)
跳跃表通过在每个结点维持多个指向其他节点的指针,从而达到快速访问节点的目的。可以与平衡树的效率媲美。两个地方用到了跳跃表,一个是有续集合键,另一个是在集群节点中用做内部数据结构。
unordered_map也就是字典,unordered_set就是集合。
typedef struct zskiplistNode{
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
} level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
}
typedef struct zskiplist {
//表头节点和表尾节点
structz skiplistNode *header,*tail;
//表中节点数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;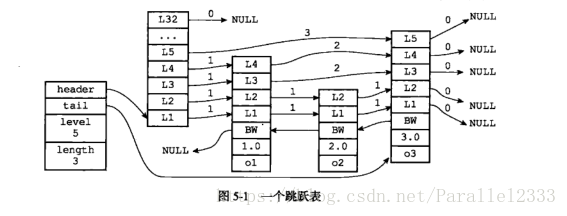
5.整数集合(集合)
就是一个数组,表示可以根据数据类型进行升级操作。里面只能存少量的数据。
6.压缩列表(列表和哈希)
相对应的是快速列表。可用于存数据以及短的字符串。
deque是由一个map中控器和一个数组组成的数据结构,它既有链表头尾插入便捷的优点,又有数组连续内存存储,支持下标访问的优点。deque属于分段连续,而不是内存连续,但它可以造成内存连续的假象。
redis是采用sdlist和ziplist一起实现的,与deque类似,因为双向链表在插入节点上复杂度很低,但它的内存开销很大,每个节点的地址不连续容易产生内存碎片。ziplist存储在连续内存上但不利于修改操作,插入删除复杂且都需要频繁的申请释放内存。
CSRF跨站请求伪造
XSS脚本攻击
唯一索引在该列中如果有重复值会报错