Webmagic设计思想
1. 一个框架,一个领域
一个好的框架必然凝聚了领域知识。WebMagic的设计参考了业界最优秀的爬虫Scrapy,而实现则应用了HttpClient、Jsoup等Java世界最成熟的工具,目标就是做一个Java语言Web爬虫的教科书般的实现。
2. 微内核和高可扩展性
WebMagic由四个组件(Downloader、PageProcessor、Scheduler、Pipeline)构成,核心代码非常简单,主要是将这些组件结合并完成多线程的任务。这意味着,在WebMagic中,你基本上可以对爬虫的功能做任何定制。
3. 注重实用性
基于注解模式的爬虫开发,以及扩展了XPath语法的Xsoup这些功能在WebMagic中是可选的,它们的开发目标,就是让使用者开发爬虫尽可能的简单,尽可能的易维护。
架构设计
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。
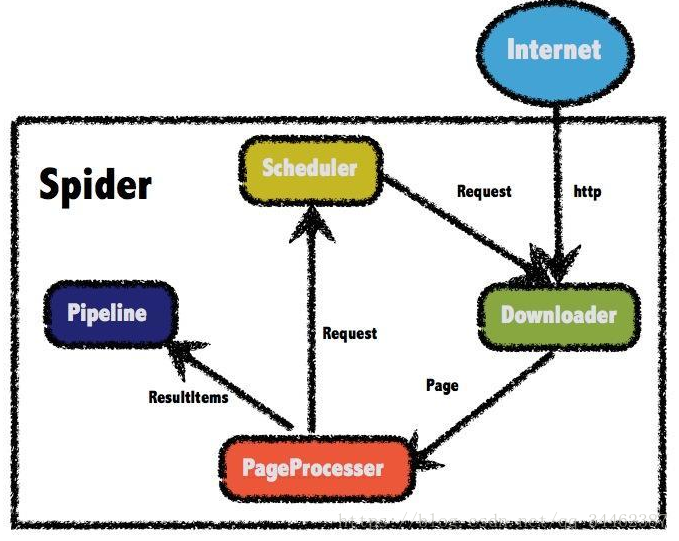
WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
Spider--控制爬虫运转的引擎
Spider是WebMagic内部流程的核心。Downloader、PageProcessor、Scheduler、Pipeline都是Spider的一个属性,这些属性是可以自由设置的,通过设置这个属性可以实现不同的功能。Spider也是WebMagic操作的入口,它封装了爬虫的创建、启动、停止、多线程等功能。
案例分析
该案例分析了从搜狐汽车网抓取日产品牌汽车最新几个月销量的过程。
package com.amber.demo.crawler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author amber E-mail: [email protected]
* @version 创建时间: 2018/8/8 下午2:57
*/
public class CrawlerPractice implements PageProcessor {
public static Logger LOGGER = LoggerFactory.getLogger(CrawlerPractice.class);
//列表链接
public static final String URL_LIST="http://db\\.auto\\.sohu\\.com/dongfengnissan/\\d+$";
//详情页链接
public static final String URL_POST="http://db\\.auto\\.sohu\\.com/dongfengnissan/\\d+/salescar\\.html";
//标志位
public static boolean flag = true;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static AtomicInteger count =new AtomicInteger(0);
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
if (flag == true) {
List<String> l_list = page.getHtml().links().regex(URL_LIST).all();
page.addTargetRequests(l_list);
flag = false;
}else{
if(page.getUrl().regex(URL_LIST).match()){
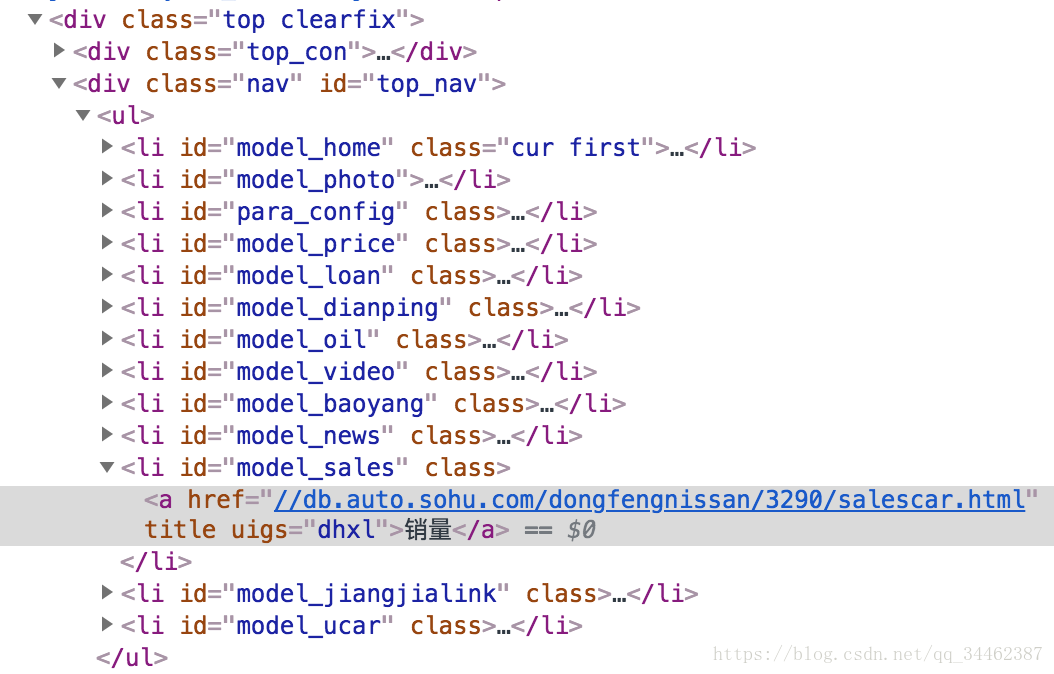
List<String> l_post = page.getHtml().xpath("//div[@class=\"top clearfix\"]/div[2]").links().regex(URL_POST).all(); //目标详情
System.out.println("目标详情记录为"+l_post.size());
page.addTargetRequests(l_post);
}else{
String carSale = page.getHtml().xpath("//*[@id=\"wh\"]/div[2]/div[2]/table/tbody/tr[2]/td[1]/text()").get();
page.putField("车系id", Arrays.asList(page.getUrl().toString().split("/")).get(4));
if (carSale.contains("销量")) {
page.putField(page.getHtml().xpath("//*[@id=\"wh\"]/div[2]/div[2]/table/tbody/tr[1]/td[1]/text()").get(),
carSale);
for (int i = 1; i < 4; i++) {
page.putField(page.getHtml().xpath("//*[@id=\"wh\"]/div[2]/div[2]/table/tbody/tr[1]/th[" + i + "]/text()").get(),
page.getHtml().xpath("//*[@id=\"wh\"]/div[2]/div[2]/table/tbody/tr[2]/td[" + (i + 1) + "]/text()").get());
}
} else {
page.putField(page.getHtml().xpath("//*[@id=\"wh\"]/div[2]/div[2]/table/tbody/tr[1]/td[1]/text()").get(),
"此车型近几月销量信息不存在");
}
count.incrementAndGet();
}
}
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new CrawlerPractice()).addUrl("http://db.auto.sohu.com/brand_205/home.shtml").thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count.get()+"条记录");
}
}
案例总结
案例十分简单,实际项目远不止这么简单,从刚开始的爬虫链接过滤,代理服务器爬取数据,数据的保存与处理,数据的完整性检查都需要与实际项目需求相结合,望大家一起与我共勉。