文章目录
初始化,涉及到使用的变量:
# =============================================================================
# 计算信息量的相关算法
# =============================================================================
import math
import numpy as np
class Cluster:
def __init__(self,x,y,sample_weight=None,base=2):
# 记录数据集的变量为numpy数组
self._x,self._y = x.T,y
# 利用样本权重对类别向量计数,self._counters样本各个类别的计数
if sample_weight is None:
self._counters = np.bincount(self._y)
else:
self._counters = np.bincount(self._y,weights = sample_weight*len(sample_weight))
# 记录样本权重的属性
self._sample_weight = sample_weight
# 记录中间结果的属性
self._con_chaos_cache = self._ent_cache = self._gini_cache = None
# 记录对数的底的属性
self._base = base
信息熵
定义公式,经验公式
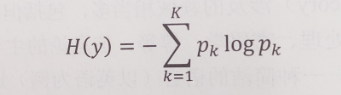
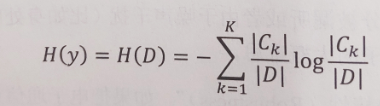
代码:
# 定义计算信息熵的函数,默认计算整个样本信息熵,self._ent_cache就是样本信息熵
# 子样本信息熵需要给出每个类别的数量
def ent(self,ent=None,eps = 1e-12):
# 如果已经计算过,且调用时没有额外给各类别样本的个数,就直接返回调用结果
if self._ent_cache is not None and ent is None:
return self._ent_cache
_len = len(self._y)
# 如果没有给出各类别样本的个数,就是用结构本身的计数器来获取相应的个数
if ent is None:
ent = self._counters
# eps使算法的稳定性更好
_ent_cache = max(eps,-sum(
[_c / _len*math.log(_c / _len,self._base) if _c !=0 else 0 for _c in ent]))
# 如果调用时没有给出各个类别样本数量,就将计算的信息熵保存下来
if ent is None:
self._ent_cache = _ent_cache
return _ent_cache
基尼系数
定义公式,经验公式
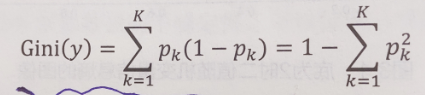
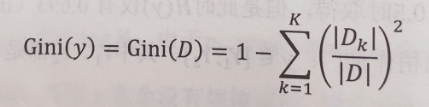
代码:
# 计算基尼系数,p为各个分类数量
def gini(self,p=None):
if self._gini_cache is not None and p is None:
return self._gini_cache
_len = len(self._y)
# 如果没有给出各类别样本的个数,就是用结构本身的计数器来获取相应的个数
if p is None:
p = self._counters
_gini_cache = 1-np.sum((p/_len)**2)
if p is None:
self._gini_cache = _gini_cache
return _gini_cache
条件熵,条件基尼系数
条件熵定义公式,经验公式
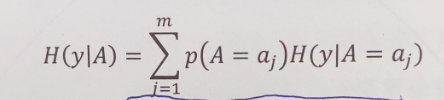
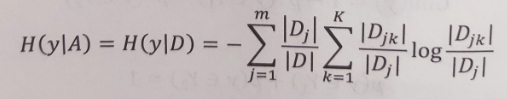
条件基尼系数定义公式,经验公式
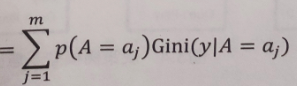
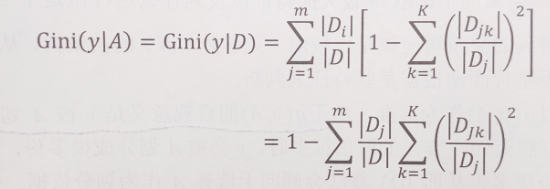
代码:
# =============================================================================
# 定义计算H(y|A)和 Gini(y|A)
# =============================================================================
def con_chaos(self,idx,criterion="ent",features=None):
# 根据不同的准则调用不同的方法, lambda input:output
if criterion == "ent":
_meghod = lambda Cluster: Cluster.ent()
elif criterion == "gini":
_meghod = lambda Cluster: Cluster.gini()
# 获取相应纬度的向量,也就是feathure A ,是一个[N]的行向量
# data为feature = idx的N个数据的feathureValue
data = self._x[idx]
# 如果没有给出该feathure的取值空间,就调用set函数自己算出来
# 调用set比较耗时,决策实现尽量传入features
# features为该feature的取值空间
if features is None:
features = set(data)
# 获取这个feature下的各个featureValue在data中的位置
# 返回的是[featureValue,对应的mask]
tmp_labels = [data == feature for feature in features]
# 在这个函数里没有使用,记录下来后面会用
# [featureValue,对应的它的样本数量]
self._con_chaos_cache =[np.sum(_label) for _label in tmp_labels]
# 利用mask获取每个featureValue对应的y样本
# [featureValue,对应他的y样本]
label_lst = [self._y[label] for label in tmp_labels]
# 上面的操作就是为了获取mask,从而获取:在feature=idx,取m个不同featureValue
# 时,这个时候的x样本和y样本,利用这些样本求信息增益的后半部分
# 记录H(y|A)最后计算结果
rs =0
# 记录每一个featureValue对应的信息增益的后半部分,
# 也就是条件不确定度,后面决策树生成会用到
chaos_lst =[]
for data_label,tar_label in zip(tmp_labels,label_lst):
# 获取对应的x样本,mask使用条件row=column,所以需要转置,
# 匹配的y样本就是tar_label,名字取得有点问题,应该叫tar_data
tmp_data = self._x.T[data_label]
if self._sample_weight is None:
# 恕我直言这个地方没必要用_meghod,有点炫耀技术,应该可以直接调用吧
_chaos = _meghod(Cluster(tmp_data,tar_label,base=self._base))
else:
_new_weights = self._sample_weight[data_label]
_chaos = _meghod(Cluster(tmp_data,tar_label,_new_weights/np.sum(
_new_weights),base=self._base))
# 计算信息增益外面的那个求和,注意负号在里面计算互信息里计算过了
# 把m个featureValue遍历完毕,就计算出了H(y|A)
rs +=len(tmp_data)/len(data)*_chaos
# 记录各部分条件不确定度,后面决策树生成会用到
chaos_lst.append(_chaos)
return rs,chaos_lst
信息增益,信息增益比,基尼增益
信息增益
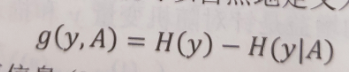
信息增益比
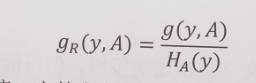
的定义和经验求法:
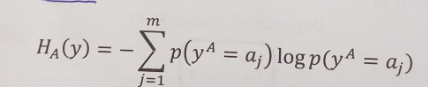
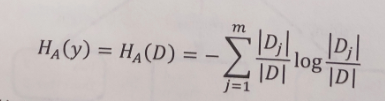
可以看出也可以使用熵的函数求解。
基尼增益
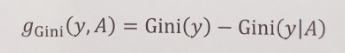
代码:
# =============================================================================
# 计算信息增益
# =============================================================================
# get_chaos_lst用于控制输出
def info_gain(self,idx,criterion="ent",get_chaos_lst=False,features=None):
# 依据不同的准则,获取相应的条件不确定度
if criterion in ("ent","ratio"):
_con_chaos,_chaos_lst =self.con_chaos(idx,"ent",features)
_gain = self.ent() - _con_chaos
# 我们知道g_ratio(y,A) = g(y,A)/H_A(y)
# self._con_chaos_cache :[featureValue,对应的它的样本数量]
# H_A(y)如何求?根据他的经验熵公式,只要把[featureValue,对应的它的样本数量]
# 带入计算就可以了
if criterion == "ratio":
_gain /= self.ent(self._con_chaos_cache)
elif criterion == "gini":
_con_chaos,_chaos_lst =self.con_chaos(idx,"gini",features)
_gain = self.gini() - _con_chaos
return (_gain,_chaos_lst) if get_chaos_lst else _gain