本文截取自《PyTorch 模型训练实用教程》,获取全文pdf请点击:https://github.com/tensor-yu/PyTorch_Tutorial
文章目录
在实际应用过程中,我们会在数据进入模型之前进行一些预处理,例如数据中心化(仅减均值),数据标准化(减均值,再除以标准差),随机裁剪,旋转一定角度,镜像等一系列操作。PyTorch有一系列数据增强方法供大家使用,下面将介绍这些方法。
在PyTorch中,这些数据增强方法放在了transforms.py文件中。这些数据处理可以满足我们大部分的需求,通过熟悉transforms.py,以及1.4节中的内容,我们也可以自定义数据处理函数,实现自己的数据增强。
在本小节,从宏观地介绍transform的使用,在下一小节,将会详细介绍transform的所有操作。
transform的使用
请查看/Code/main_trainingmain.py中代码:
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
normTransform = transforms.Normalize(normMean, normStd)
trainTransform = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
normTransform
])
validTransform = transforms.Compose([
transforms.ToTensor(),
normTransform
])
前三行设置均值,标准差,以及数据标准化:transforms.Normalize()函数,这里是以通道为单位进行计算均值,标准差。
然后用transforms.Compose将所需要进行的处理给compose起来,并且需要注意顺序!
在训练时,依次对图片进行以下操作:
1. 随机裁剪
2. Totensor
3. 数据标准化(减均值,除以标准差)
1. 随机裁剪
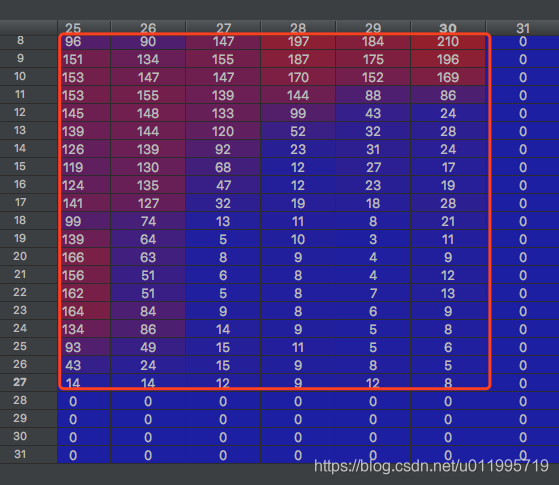
第一个处理是随机裁剪,在裁剪之前先对图片的上下左右均填充上4个pixel,值为0,即变成一个4040的数据,然后再随机进行3232的裁剪。
例如下图,是经过transforms.RandomCrop(32, padding=4),之后的图片,其中红色框是原始图片数据,31列是填充的0,28-31行也是填充的0.
2. Totensor
第二个处理是 transforms.ToTensor()
在这里会对数据进行transpose,原来是hwc,会经过img = img.transpose(0, 1).transpose(0, 2).contiguous(),变成chw再除以255,使得像素值归一化至[0-1]之间,来看看Red通道。

来看看27行,30列 原来是8的, 经过ToTensor之后变成:8/255= 0.03137255
3. 数据标准化(减均值,除以标准差)
第三个处理是对图像进行标准化,通过标准化之后,再来看看Red通道的数据:

至此,数据预处理完毕,最后转换成Variable类型,就是输入网络模型的数据了。
细心的朋友可能会发现,在进行Normalize时,需要设置均值和方差,在这里直接给出了,但在实际应用中是要去训练集中计算的,天下可没有免费的午餐。
这里给出计算训练集的均值和方差的脚本:
https://github.com/tensor-yu/PyTorch_Tutorial/blob/master/Code/1_data_prepare/1_5_compute_mean.py
转载请注明出处:https://blog.csdn.net/u011995719/article/details/85103712