可参考:Oracle高级查询之over(partition by…)
常用分析函数
row_number() over(partition by ... order by ...)
rank() over(partition by ... order by ...)
dense_rank() over(partition by ... order by ...)
count() over(partition by ... order by ...)
max() over(partition by ... order by ...)
min() over(partition by ... order by ...)
sum() over(partition by ... order by ...)
avg() over(partition by ... order by ...)
first_value() over(partition by ... order by ...)
last_value() over(partition by ... order by ...)
lag() over(partition by ... order by ...)
lead() over(partition by ... order by ...)
OVER(PARTITION BY)函数介绍
oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处在于
- 聚合函数对于每个组只返回一条数据
- 而分析函数对于每个组返回多条数据
over后的写法
over(order by salary)按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
over(partition by deptno order by salary)
函数理解
create table EMP
(
empno NUMBER(4) not null,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
)
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600, 300, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250, 500, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250, 1400, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500, 0, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300, null, 10);
1、rank()/dense_rank() over(partition by …order by …)
需求:查询每个部门工资最高的雇员信息
select * from (select ename, job, hiredate, e.sal, e.deptno
from emp e,
(select deptno, max(sal) sal from emp group by deptno) t
where e.deptno = t.deptno
and e.sal = t.sal)
order by deptno;
使用rank() over(partition by…)或dense_rank() over(partition by…)语法,SQL分别如下:
select empno, ename, job, hiredate, sal, deptno
from (select empno, ename, job, hiredate, sal, deptno, rank() over(partition by deptno order by sal desc) r from emp)
where r = 1;
select empno, ename, job, hiredate, sal, deptno
from (select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp)
where r = 1
语法讲解:
- over:基于条件之上
- partition by e.deptno:按部门编号划分(分组)
- order by e.sal desc:按工资从高到低排序(使用rank()/dense_rank() 时,必须要带order by否则非法)
- ank()/dense_rank(): 分级
整个语句的含义为:在部门分组的基础上,按工资从高到低对雇员进行排序,"级别"从1~N的数字表示(最小的为1)
那么rank()和dense_rank()有什么区别呢?
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
分解理解:
查看deptno = 20的记录
select empno, ename, job, hiredate, sal, deptno from emp where deptno = 20 order by sal;

dense_rank():
select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp where deptno = 20;
dense_rank() over(partition by deptno order by sal desc):基于在(部门分组的基础上,按工资从高到低对雇员进行排序)的基础上,通过dense_rank()对组内的记录进行分级
根据工资的不同从高到低进行分级,同等工资为同一级
rank():
select empno, ename, job, hiredate, sal, deptno, rank() over(partition by deptno order by sal desc) r from emp where deptno = 20;
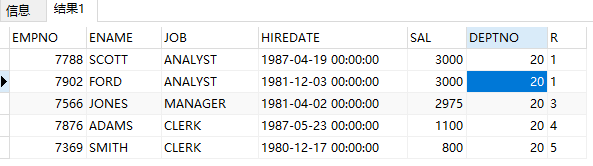
查询部门最低工资的雇员信息。
方法:改变分组后的,排序规则,从小到大排序(升序)
select empno, ename, job, hiredate, sal, deptno
from (select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal asc) r from emp)
where r = 1
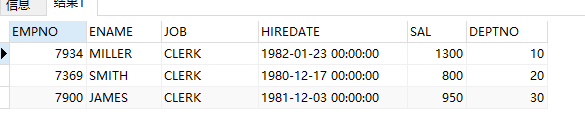
2、min()/max() over(partition by …)
现在我们已经查询得到了部门最高/最低工资,
需求2:查询每位雇员信息的同时算出雇员工资与所属部门最高/最低员工工资的差额
select e.ename as 姓名, e.job as 职业, e.hiredate as 入职日期, e.sal as 工资, e.deptno as 部门,
(e.sal - t.min_sal) as 最低差额, (t.max_sal - e.sal) as 最高差额
from emp e,
(select deptno, max(sal) as max_sal,min(sal) as min_sal from emp group by deptno) t
where e.deptno = t.deptno order by e.deptno, e.sal
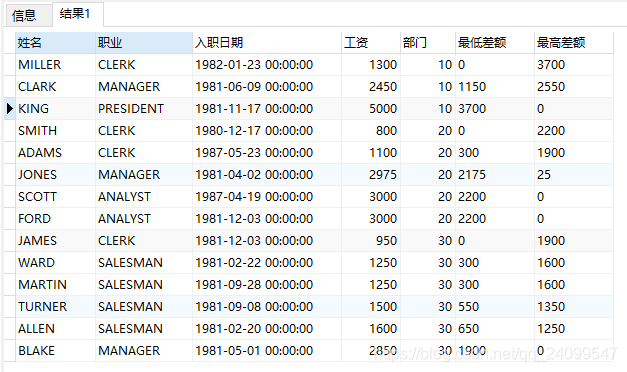
上面我们用到了min()和max(),前者求最小值,后者求最大值。如果这两个方法配合over(partition by …)使用会是什么效果呢?大家看看下面的SQL语句:
select ename 姓名, job 职业, hiredate 入职日期, deptno 部门,
min(sal) over(partition by deptno) 部门最低工资,
max(sal) over(partition by deptno) 部门最高工资
from emp order by deptno, sal;
select ename 姓名, job 职业, hiredate 入职日期, deptno 部门,
nvl(sal - min(sal) over(partition by deptno), 0) 部门最低工资差额,
nvl(max(sal) over(partition by deptno) - sal, 0) 部门最高工资差额
from emp order by deptno, sal;
min(sal) over(partition by deptno):基于在(部门分组)的基础上,通过min(sal)获取组内最小工资
这两个语句的查询结果是一样的,大家可以看到min()和max()实际上求的还是最小值和最大值,只不过是在partition by分区基础上的。
3、lead()/lag() over(partition by … order by …)
带order by子句的方法说明在使用该方法的时候必须要带order by
需求:计算在同一个部门中,个人工资与比自己高一位/低一位工资的差额。
select ename 姓名, job 职业, sal 工资, deptno 部门,
lead(sal, 1, 0) over(partition by deptno order by sal) 比自己工资高的部门前一个,
lag(sal, 1, 0) over(partition by deptno order by sal) 比自己工资低的部门后一个,
nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) 比自己工资高的部门前一个差额,
nvl(sal - lag(sal) over(partition by deptno order by sal), 0) 比自己工资高的部门后一个差额
from emp;
分解:
select ename 姓名, job 职业, sal 工资, deptno 部门 from emp where deptno = 10 ORDER BY sal;
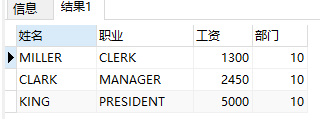
select ename 姓名, job 职业, sal 工资, deptno 部门,
lead(sal, 1, 0) over(partition by deptno order by sal) 上一个级别工资,
lag(sal, 1, 0) over(partition by deptno order by sal) 下一个级别工资
from emp where deptno = 10;
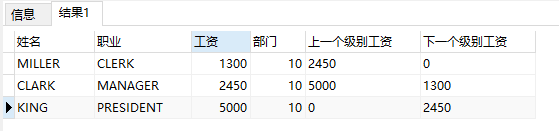
lead(列名,n,m): 当前记录后面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录后面第一行的记录<列名>的值,没有则默认值为null。
lag(列名,n,m): 当前记录前面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录前面第一行的记录<列名>的值,没有则默认值为null。
lead(sal, 1, 0) over(partition by deptno order by sal):基于在(部门分组的基础上,按工资从低到高对雇员进行排序)的基础上,通过lead(sal, 1, 0)函数获取当前记录后面第1条记录的sal的值,如果后面没有记录了,就显示为默认值0
4、其余高级查询
select ename 姓名, job 职业, sal 工资, deptno 部门,
first_value(sal) over(partition by deptno) first_sal,
last_value(sal) over(partition by deptno) last_sal,
sum(sal) over(partition by deptno) 部门总工资,
avg(sal) over(partition by deptno) 部门平均工资,
count(1) over(partition by deptno) 部门总数,
row_number() over(partition by deptno order by sal) 序号
from emp;

重要提示:大家在读完本片文章之后可能会有点误解,就是OVER (PARTITION BY …)比GROUP BY更好,实际并非如此,前者不可能替代后者,而且在执行效率上前者也没有后者高,只是前者提供了更多的功能而已,所以希望大家在使用中要根据需求情况进行选择。
row_number()浅析:
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
与rownum的区别在于:
使用rownum进行排序的时候是先对结果集加入伪列rownum然后再进行排序
而此ro
row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序)。
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。