最近,听很多朋友都在说人工智能越来越火,想要了解其中究竟,于是我就推荐了几本书,但结果却是,除了工程师朋友能够勉强看下去外,其余大部分人到最后都不得放弃了,原因是太多数学公式,太难理解了。
比如,《深度学习》这本书,算得上一本科普书了,是专门写给一般人看的,其中也包含了大量的数学和公式。
我倒是认为,并不是因为看不懂,而是其中的数学很容激发大部分一般人的学校噩梦,想到好不容易毕业上班不用看数学了,结果又被唤起,自然读不下去。
可数学是学习机器学习绕不开的一道关卡,必然要去解决,搞技术的人多多少少也要接触数学,可还是很多人不想看数学。
不过,以我的经验来看,不是没有办法,但要换个思路来切入,就是从学习python开始,上一篇文章《机器学习折腾记0:开启从Scikit-Learn入门机器学习算法之旅》,我介绍了机器学习python环境的安装,提到了《机器学习系统设计》这本书,并不是因为这本书好理解,而是因为他没有像很多常规的机器学习书或文章那样,一上来就介绍很多基础知识,把人搞晕,而是提供了一个另类的不错的切入思路,我们就从这本书开始。
提个好问题
作者说,机器学习 (ML)就是教机器自己来完成任务。这和我们以为的机器是不是应该具备了生物智能是不同的。
换句话说,机器学习就是一种计算机能够运行的算法,让机器能够模仿人类一样学习知识。
既然是算法,作者一开始还提出了几个很好的问题:在无数的算法中应该选择哪一个呢?所有的设置都正确吗?你得到最优的结果了吗?怎么知道有没有更好的算法?或者,你的数据是否就是“正确的”?
数据就是机器学习的养料,如果你认识做数据挖掘或数据分析的人,他们一定能够清晰的给你解释什么是机器学习,以及人工智能的本质到底是什么。
所以提一个好问题很重要!
核心三步法
多说一句,这本书本身就是一本是实战书,每个小结都是一个操作步骤,你可以按部就班的看。
不过,如果你不动手去敲代码,只是想用随书的代码的话,那很遗憾,很多时候都运行不了,可能是新版本不兼容老版本,或者各种环境编译的问题,总之,我们的目标是学到有用的东西,而不是看上去好像懂了。
对于机器学习的流程来说,就是简单的三步法——
1、读取数据
2、预处理和清洗数据
3、选择正确的模型和学习算法
很多时候,我们都把问题搞复杂了,特别是对于计算机相关书籍,常常都容易陷入实现细节中去,这也是为什么很多人看着看着就昏了的原因,因为一开始没有抓住最重要的核心脉络,要是再加上数学公式,就更难看下去了。
我的建议是,先放下里面难懂的数学解释,包括每一节的说明,先运行起来一个程序,从感性上去感受一下,机器学习在运行中是什么样子,就够了。
我曾经及时一直抓住要解决实际问题这条主线而出发去学习理解算法时,效率是非常高的,而如果从所谓的基础学起,可能早都放弃了,先来看一下最终效果图。
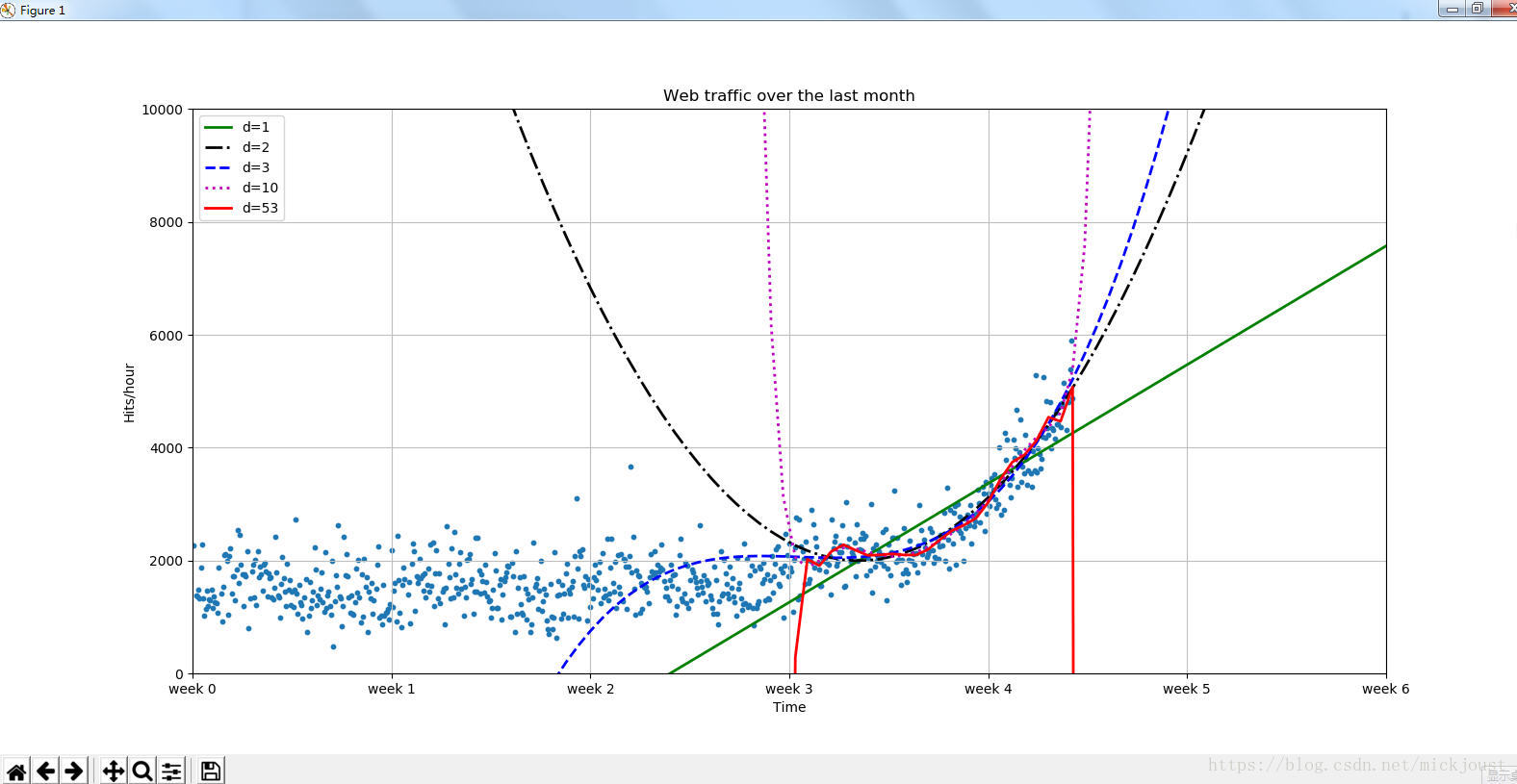
回答最初的问题
得到上面的图是需要经过一番折腾的,我之所以省略了抄书的步骤,是因为实战就是要你去动手敲代码,也是检验你python基础的时候了,我们最终就会得到了一个模型,我们认为它可以最好地代表数据生成过程。
而这个模型就是机器学习的最终结果,而我们拿着这个模型就可以预测未来的数据走向发展,但可惜的时,现实中有一种叫做突变的因素存在。
还是那几个问题:在无数的算法中应该选择哪一个呢?所有的设置都正确吗?你得到最优的结果了吗?怎么知道有没有更好的算法?或者,你的数据是否就是“正确的”?
如果你依然有兴趣看下去,那就一直不要忘记这几个问题,以及你为什么而开始去学习机器学习。
实现代码
如果你认真按照前一篇文章《机器学习折腾记0:开启从Scikit-Learn入门机器学习算法之旅》的步骤做了,下面的代码是一定能运行的,里面有很多注释代码,在看书时也可以一段一段的跟着试试。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import scipy as sp
import matplotlib.pyplot as plt
# 画图的一些颜色和线条形状
colors = ['g', 'k', 'b', 'm', 'r']
linestyles = ['-', '-.', '--', ':', '-']
# 定义一个画图的类
def plot_models(x, y, models, fname=None, mx=None, ymax=None, xmin=None):
plt.clf()
plt.scatter(x, y, s=10)
plt.title("Web traffic over the last month")
plt.xlabel("Time")
plt.ylabel("Hits/hour")
plt.xticks(
[w * 7 * 24 for w in range(10)], ['week %i' % w for w in range(10)])
if models:
if mx is None:
mx = sp.linspace(0, x[-1], 1000)
for model, style, color in zip(models, linestyles, colors):
# print "Model:",model
# print "Coeffs:",model.coeffs
plt.plot(mx, model(mx), linestyle=style, linewidth=2, c=color)
plt.legend(["d=%i" % m.order for m in models], loc="upper left")
plt.autoscale(tight=True)
plt.ylim(ymin=0)
if ymax:
plt.ylim(ymax=ymax)
if xmin:
plt.xlim(xmin=xmin)
plt.grid(True, linestyle='-', color='0.75')
# plt.show() # 这个是会阻塞的,看最后一个,就在代码最后加
# plt.savefig(fname)
def error(f, x, y):
return sp.sum((f(x)-y)**2)
data = sp.genfromtxt("web_traffic.tsv", delimiter="\t")
print(data[:10]) #打印前10个数据
print(data.shape)
# 预处理和清洗数据
x = data[:,0] #对应第1列
y = data[:,1] #对应第2列
isnan_num = sp.sum(sp.isnan(y))
print(isnan_num)
x = x[~sp.isnan(y)] #这里是取反操作,y值为空则不取
y = y[~sp.isnan(y)]
# import matplotlib.pyplot as plt
# plt.scatter(x,y)
# plt.title("Web traffic over the last month")
# plt.xlabel("Time")
# plt.ylabel("Hits/hour")
# plt.xticks([w*7*24 for w in range(10)],['week %i'%w for w in range(10)])
# plt.autoscale(tight=True)
# plt.grid()
# plt.show()
fp1, residuals, rank, sv, rcond = sp.polyfit(x, y, 1, full=True)
print("Model parameters: %s" % fp1)
# print(res)
#f(x) = 2.59619213 * x + 989.02487106
f1 = sp.poly1d(fp1)
print(error(f1, x, y))
fx = sp.linspace(0,x[-1], 1000) # 生成X值用来作图
# plt.plot(fx, f1(fx), linewidth=4,color='green')
# plt.legend(["d=%i" % f1.order], loc="upper left")
# plt.grid()
# plt.show() #
plot_models(x, y, None)
# d=2
f2p = sp.polyfit(x, y, 2)
print(f2p)
f2 = sp.poly1d(f2p)
print(error(f2, x, y))
# plt.plot(fx, f2(fx), linewidth=3, color='red')
# plt.legend(["d=%i" % f2.order], loc="upper left")
#d=3
f3p = sp.polyfit(x, y, 3)
print(f3p)
f3 = sp.poly1d(f3p)
print(error(f3, x, y))
# plt.plot(fx, f3(fx), linewidth=3, color='black')
# plt.legend(["d=%i" % f3.order], loc="upper left")
#d=10
f10p = sp.polyfit(x, y, 10)
print(f10p)
f10 = sp.poly1d(f10p)
print(error(f10, x, y))
# plt.plot(fx, f10(fx), linewidth=3, color='gray')
# plt.legend(["d=%i" % f10.order], loc="upper left")
#d=100
f100p = sp.polyfit(x, y, 100)
print(f100p)
f100 = sp.poly1d(f100p)
print(error(f100, x, y))
# plt.plot(fx, f100(fx), linewidth=3, color='yellow')
# plt.legend(["d=%i" % f100.order], loc="upper left")
plot_models(
x, y, [f1, f2, f3, f10, f100])
inflection = 3*7*24 # 计算拐点的小时数,书中3.5要报错,改为3
xa = x[:inflection] # 拐点之前的数据
ya = y[:inflection]
xb = x[inflection:] # 之后的数据
yb = y[inflection:]
fa = sp.poly1d(sp.polyfit(xa, ya, 1))
fb = sp.poly1d(sp.polyfit(xb, yb, 1))
fa_error = error(fa, xa, ya)
fb_error = error(fb, xb, yb)
# print("Error inflection=%f" % (fa + fb_error))
# plot_models(x, y, [fa, fb])
# plt.plot(fx, fa(fx), linewidth=3, color='c')
# plt.legend(["d=%i" % fa.order], loc="upper left")
# plt.plot(fx, fb(fx), linewidth=3, color='c')
# plt.legend(["d=%i" % fb.order], loc="upper left")
plot_models(x, y, [f1, f2, f3, f10, f100], None,
mx=sp.linspace(0 * 7 * 24, 6 * 7 * 24, 100),
ymax=10000, xmin=0 * 7 * 24)
frac = 0.3
split_idx = int(frac * len(xb))
shuffled = sp.random.permutation(list(range(len(xb))))
test = sorted(shuffled[:split_idx])
train = sorted(shuffled[split_idx:])
fbt1 = sp.poly1d(sp.polyfit(xb[train], yb[train], 1))
fbt2 = sp.poly1d(sp.polyfit(xb[train], yb[train], 2))
fbt3 = sp.poly1d(sp.polyfit(xb[train], yb[train], 3))
fbt10 = sp.poly1d(sp.polyfit(xb[train], yb[train], 10))
fbt100 = sp.poly1d(sp.polyfit(xb[train], yb[train], 100))
plot_models(
x, y, [fbt1, fbt2, fbt3, fbt10, fbt100], None,
mx=sp.linspace(0 * 7 * 24, 6 * 7 * 24, 100),
ymax=10000, xmin=0 * 7 * 24)
from scipy.optimize import fsolve
print(fbt2)
print(fbt2 - 100000)
reached_max = fsolve(fbt2 - 100000, 800) / (7 * 24)
print("100,000 hits/hour expected at week %f" % reached_max[0])
plt.show() # 只看最后一个时打开小结
你可能也发现了,不管是使用现成的机器学习库,还是自己重复造轮子实现算法,最终花更多精力的是在数据上,更重要的是理解数据和提炼数据。
换句话说,最重要的是的对数据的分析,就像我们学习知识一样,理解知识,提炼知识才是更重要的。
而我们要学习的就是不同的算法在对数据的处理,以及如何优化这些算法,同时还要结合自己的应用场景来具体分析,不要让“更多看上去很厉害的算法”分散了你的注意力。
参考资源
1、《机器学习系统设计》
2、《Python语言指南》