在之前学基本数据类型的时候知道了,在 python 中,字符串 是一个有序的字符的集合,用于存储和表示基本的文本信息,由一对 单引号 或 双引号 又或者是 三引号 包含着,但是 字符串 有两个特点:
1、有序
2、不可变
其实字符串有序,都很好理解,就是通过语言本身提供的方法来对字符串进行一些处理,不可变是因为 python 的运行机制,其实不单单只有 python 有,别的语言也是一样的。
不可变
关于不可变,其实我也是通过学习了才知道的,如:
a = '123456'
a = 'qwerty'
如上图,表面上其实变量 a 已经被改变了,重新赋值了,但其实他并没有被改变,或者说,一个字符串集合的变量一旦生成出来了,就再也不会改变了如:
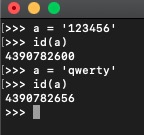
如上图,我给变量 a 先赋了个值为 '123456',然后我查询出他储存在内存中的地址为 4390782600 ,然后我给变量 a 重新赋了个值为 'qwerty' ,然后我在通过 id() 方法查询他的内存地址,发现变成了 4390782656 ,也就是说,相当于给变量 a 不仅把 变量值 更换了,还把变量值的 地址 给换了,也就是说 python 重新开辟了一块内存来存储这个变量,原来地址为 4390782600 的值相当于被隐藏了,等待一定的时间会被 python 解析器自动回收并将该内存给释放出来,所以这 字符串 的不可变的特性。
有序
有序其实就是语言本身给我们提供了许多的的操作方法,让字符串更加序列化一点,让我一个一个来演示,如:
capitalize() : 返回一串首字母大些其余小写的字符串
a = 'hello word'
print(a.capitalize())
>> Hello word
casefold() : 将字符串全部转为小写
a = 'HellO WoRd'
print(a.casefold())
>> hello word
center(字符串数量,填充字符) : 将字符串以任意可是填充至指定字符串左右两侧,让字符串数量满足为指定的第一个参数
a = 'HellO WoRd'
print(a.center(50,'*'))
>> ********************HellO WoRd********************
count(指定字符串,开始下标,结束下标) : 统计一个字符串集合里存在多少个指定的字符串,字母区分大小写,默认不写 开始下标 和 结束下标 两个参数,表示 全局匹配,写了 下标,表示在下标 内部匹配
a = 'HelLo Word'
print(a.count('o'))
print(a.count('l'))
print(a.count('o',0,5))
>> 2
>> 1
>> 1
endswith(指定字符串) : 判断是否以指定字符串结尾
a = 'Hello Word!'
print(a.endswith('!'))
print(a.endswith('Word!'))
print(a.endswith('Hello'))
>> True
>> True
>> False
expandtabs(数值) : 增加 tab按键 的长度,默认 tab键 是 4 个空格符,也就是首行缩进的长度
a = 'a\tb' # \t 就是tab键
print(a)
print(a.expandtabs(20))
>> a b >> a b
find(字符串,开始下标,结束下标) : 查找字符串的索引值,默认找到第一个就不会继续往下找了,第二和第三个参数不写,默认全局匹配,否则就是局部寻找,找到了返回真实下标,找不到返回 -1
a = 'Hello Word!'
print(a.find('o'))
print(a.find('o',5,-1))
print(a.find('z'))
>> 4
>> 7
>> -1
rfind(字符串,开始下标,结束下标) : 和 find() 方法一样,不过是从后往前开始查找字符串,而不是从左往右
a = 'Hello Word!'
print(a.rfind('o'))
print(a.rfind('o',5,-1))
print(a.rfind('z'))
>> 7
>> 7
>> -1
format() : 字符串传参,关于字符串传参,上次刚学的时候用百分号 % 尝试着做过一个小例子,但是这次的 format() 稍微又有点不同,如:
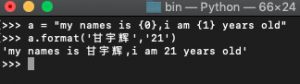
可以看到我通过在字符串里面加入 {} ,然后 花括号 里面写的是 format() 参数的先后顺序,然后依次传参最终的出了结果 'my names is 甘宇辉,i am 21 years old' ,其实还有其实参数还可以重复的利用,如:
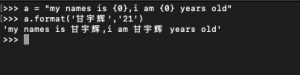
可以看到,我两个 {} 都传 0 实际上就变成了一值多享,当然还有一种特殊的值,可以这样传:
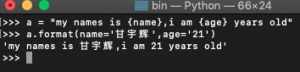
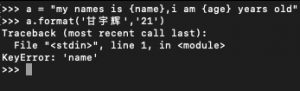
可以看到我这次没有通过下标索引去传值,而是通过指定的参数名赋值,如果引用的时候不把 参数= 写在前面的话,是一定会报错的,如:
index(字符串,开始值,结束值) : 和数组中一样运用,可以找到对应值的下标,但是如果有多个一样的值,index() 默认查找到第一个就不会往下继续查找了,如:
a = 'dahsudhuasdhuashui2139012831'
a.index('a')
>> 1
返回出来的值等于 1 ,之后他就不会往下继续匹配了,默认匹配到第一个值后就会停止,不会往下走了,后面两个参数一般用区域搜索,默认不写匹配全局,如果找不到则会报错。
isalnum() : 匹配整个字符串里面是否有 阿拉伯数字 的字符串,如果有阿拉伯数字则返回 True ,否则返回 False,( 前提条件是里面不能有空格或其他非字母和阿拉伯数字的的字符串不然也会返回 False )
'HelloWord123'.isalnum()
>> True
'HelloWord123 123'.isalnum()
>> False
'HelloWord123 ,;-='.isalnum()
>> False
'HelloWord'.isalnum()
>> False
isalpha() : 判断是否为纯字母的字符串,否则返回 False
'HelloWord123'.isalpha()
>> False
'HelloWord'.isalpha()
>> True
isdecimal() : 判断是否为纯整数数字的字符串,否则返回 False
'HelloWord123'.isdecimal()
>> False
'123'.isdecimal()
>> True
isdigit() : 和 isdecimal() 一样,判断是否为纯整数数字的字符串,否则返回 False
'HelloWord123'.isdigit()
>> False
'123'.isdigit()
>> True
isnumeric() : 和 isdecimal() 与 isdigit() 一样,判断是否为纯整数数字的字符串,否则返回 False
'HelloWord123'.isnumeric()
>> False
'123'.isnumeric()
>> True
isidentifier() : 判断 字符串 首字母 是否为数字,如果不是数字 返回 True 否则返回 False
'HelloWord123'.isidentifier()
>> True
'_HelloWord123'.isidentifier()
>> True
'123'.isidentifier()
>> False
islower() : 判断字符串里面是否有 大写字母,如果有大写字母,返回 False 没有返回 True
'ord123'.islower()
>> True
'HelloWord123'.islower()
>> False
isprintable() : 这个方法有点特殊,他是用来判断某个文件是否是 不可被打印 的,如果可以打印,返回 True ,否则返回 False 。因为在计算机中,除了有很多中类型的文件,纯文本 或者是 字节格式 或者是 数据格式 的都是可以被打印的,如果是 可执行文件 或者是 音频 视频 文件是打印不出来的,他们是纯二进制流的数据,
'ord123'.isprintable()
>> True
isspace() : 判断这个字符串是不是一个纯空格的字符串
' '.isspace()
>> True
'weqweop'.isspace()
>> False
istitle() : 判断这个一个字符串是否是 标题格式 的,也就是段落语句第一个字母是否为大写
'Hello'.istitle()
>> True
'Hello word'.istitle()
>> False
'Hello Word'.istitle()
>> True
isupper() : 判断字母是否都是大写
'Hello'.isupper()
>> False
'HELLO'.isupper()
>> True
''.join() : 将数组拼接成一个字符串,如:
a = ['123','qwe','123']
','.join(a)
>> '123,qwe,123'
'-'.join(a)
>> '123-qwe-123'
' '.join(a)
>> '123 qwe 123'
ljust(数字,字符) : 和 expandtabs() 方法类似,填充字符串数字,如果第二个不填写字符,则默认为空格,但是是从左往右添加而不是两边都添加
'hello word'.ljust(20,'*')
>> 'hello word**********'
'hello word'.ljust(20)
>> 'hello word '
'hello word'.ljust(20,'—')
>> 'hello word——————————'
rjust(数字,字符) : 和 ljust() 方法正好相反,他是往左添加的
'hello word'.rjust(20,'*')
>> '**********hello word'
'hello word'.rjust(20)
>> ' hello word'
'hello word'.rjust(20,'—')
>> '——————————hello word'
lower() : 将字符串全部转为小写
'HELLO WORD'.lower()
>> 'hello word'
upper() : 将字符串全部转为大写
'hello word'.upper()
>> 'HELLO WORD'
swapcase() : 和 upper() 方法一样都是小写转大写
'hello word'.swapcase()
>> 'HELLO WORD'
strip() : 去字符串首尾的换行和空格与tab键的格式
' \n hello word '.strip()
>> 'hello word'
lstrip() : 去字符串左边的换行和空格与tab键的格式
' \n hello word '.strip()
>> 'hello word '
rstrip() : 去字符串右边的换行和空格与tab键的格式
' \n hello word '.strip()
>> ' \n hello word'
str.maketrans() 与 translate() : 自定义秘文加密
Secretaries = 'abcdefg' # 自定义需要加密的字母
mapping = '!@#$%^&' # 将需要加密的字母一一对应上定义的符号
encryption = str.maketrans(Secretaries,mapping) # 通过 str 属性下面的 maketrans() 方法 将他们组合起来赋值给一个变量
test_str = 'hello word' # 需要加密的字符串
result = test_str.translate(encryption) # 通过 translate() 方法将 test_str 字符串将上面对应过的字母加密
print(result) # 打印出结果
>> h%llo wor$ # 第二个字母 e 对应上了 mapping 的第 5 个所以等于 % ,最后一个字母 d 对应上了 第四个加密的 $
partition() : 字符串切割
a = 'abcdefghddijklmn'
a.partition('d') # 从字符串左边开始查找找到第一个 d 开始切割
>> ('abc', 'd', 'efghddijklmn')
rpartition() : 从右边开始字符串切割
a = 'abcdefghddijklmn'
a.rpartition('d') # 从字符串右边开始查找找到第一个 d 开始切割
>> ('abcdefghd', 'd', 'ijklmn')
replace(被更新的,更新成,数量) : 字符串替换,数量不写默认为全局匹配
a = 'abbbcdefghijklmn'
a.replace('b','B')
>> 'aBBBcdefghijklmn'
a = 'abbbcdefghijklmn'
a.replace('b','B',1)
>> 'aBbbcdefghijklmn'
rindex() : 从右边开始查找匹配对应的索引值,匹配错误会报异常错误
a = 'abbbcdefghijklmn'
a.rindex('n')
>> 15
split() : 将字符串分割成列表,默认以空格区分
a = 'hello word'
a.split() # 默认以空格区分,也可以指定字符串(按那个指定的字符分,那个指定的字符就没了)
a.split('o') # 指定特定的字符串更换
a.split('o',1) # 第二个参数代表执行次数,默认全部匹配分割
>> ['hello', 'word']
>> ['hell', ' w', 'rd']
>> ['hell', ' word']
rsplit() : 和 split() 一样的用法,如果不传第二个参数,基本一直,如果传了第二个参数则是从右开始往左匹配次数
a = 'hello word'
a.rsplit() # 默认以空格区分,也可以指定字符串(按那个指定的字符分,那个指定的字符就没了)
a.rsplit('o') # 指定特定的字符串更换
a.rsplit('o',1) # 第二个参数代表执行次数,从右往左开始
>> ['hello', 'word']
>> ['hell', ' w', 'rd']
>> ['hello w', 'rd']
splitlines() : 以换行符来分割字符串,组合成一个新的列表数组
a = '\nh\nel\nlo\nword'
a.splitlines()
>> ['', 'h', 'el', 'lo', 'word']
startswith() : 以什么字符串开头
a = 'hello word'
a.startswith('hello')
a.startswith('h')
a.startswith('e')
>> True
>> True
>> Flase
endswith() : 以什么字符串结束
a = 'hello word'
a.endswith('d')
a.endswith('word')
a.endswith('r')
>> True
>> True
>> Flase
title() : 将字符串转化成 title 格式
a = 'hello word'
a.title()
>> 'Hello Word'
zfill() : 将字符串指定长度,不够的用零来补充,加在字符串前面
a = 'hello word'
a.zfill(30)
>> '00000000000000000000hello word'
关于 python 内置提供的方法全部了解完了