前言
在RMQ中为了提高commitlog文件的读写效率,而采用了一个叫做内存映射的技术。按照我的理解,内存映射在处理大文件上有非常大的性能提升,所以这篇来记录一下我对内存映射的理解。
用户态和内核态
我们都知道操作系统分为用户态和内核态,内核态表示当前为内核程序执行时的状态,用户态是用户程序代码运行的状态。用户态是不能直接和物理设备打交道的,如果想把硬盘的一块区域读到用户态,则需要两次拷贝(硬盘->内核->用户)。看用户态和内核态在一次IO使用的情况:
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中,因为只有内核程序才可以和IO设备进行读写,所以这个过程就是内核态,内核程序将缓冲区复制到用户空间中,内核态就结束,用户态继续执行。
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,内核空间再讲数据刷到磁盘中。至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
那么为什么要分成用户态和内核态呢?
将它们分开主要是为了安全性考虑。即使用户的程序崩溃了,内核中的内核程序也不受影响。
虚拟内存
在早期的计算机中,是没有虚拟内存的概念的。我们要运行一个程序,会把程序全部装入内存,然后运行。当运行多个程序时,经常会出现进程地址空间不隔离,没有权限保护、内存使用效率低等问题。所以引入虚拟内存来避免上述的问题。
虚拟内存不只是“用磁盘空间来扩展物理内存”的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,虚拟内存通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。
Linux虚拟内存的大小为2^32(在32位机器上)刚好4G,内核将这4G字节的空间分为两部分。最高的1G字节(从虚地址0xC0000000到0xFFFFFFFF)供内核使用,称为“内核空间”。而较低的3G字节(从虚地址0x00000000 到0xBFFFFFFF),供各个进程使用,称为“用户空间”。因为每个进程可以通过系统调用进入内核,因此,Linux内核空间由系统内的所有进程共享。
用户空间不是进程共享的,而是进程隔离的。每个进程最大都可以有3GB的用户空间。一个进程对其中一个地址的访问,与其它进程对于同一地址的访问绝不冲突。比如,一个进程从其用户空间的地址0x1234ABCD处可以读出整数8,而另外一个进程从其用户空间的地址0x1234ABCD处可以读出整数20,这取决于进程自身的逻辑。
从上面我们知道,一个程序编译连接后形成的地址空间是一个虚拟地址空间,但是程序最终还是要运行在物理内存中。因此,应用程序所给出的任何虚地址最终必须被转化为物理地址,所以,虚拟地址空间必须被映射到物理内存空间中,这个映射关系需要通过硬件体系结构所规定的数据结构来建立。这就是我们所说的段描述符表和页表,Linux主要通过页表来进行映射。
于是,我们得出一个结论,如果给出的页表不同,那么CPU将某一虚拟地址空间中的地址转化成的物理地址就会不同。所以我们为每一个进程都建立其页表,将每个进程的虚拟地址空间根据自己的需要映射到物理地址空间上。既然某一时刻在某一CPU上只能有一个进程在运行,那么当进程发生切换的时候,将页表也更换为相应进程的页表,这就可以实现每个进程都有自己的虚拟地址空间而互不影响。所以,在任意时刻,对于一个CPU来说,只需要有当前进程的页表,就可以实现其虚拟地址到物理地址的转化。
内存映射
首先,“映射”这个词,就和数学课上说的“一一映射”是一个意思,就是建立一种一一对应关系,在这里主要是只 硬盘上文件的位置,与进程 **逻辑地址空间**中 一块大小相同的区域之间的一一对应,如下图中过程1所示。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在 的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构 (struct address_space),这个过程有系统调用mmap()实现,所以建立内存映射的效率很高。
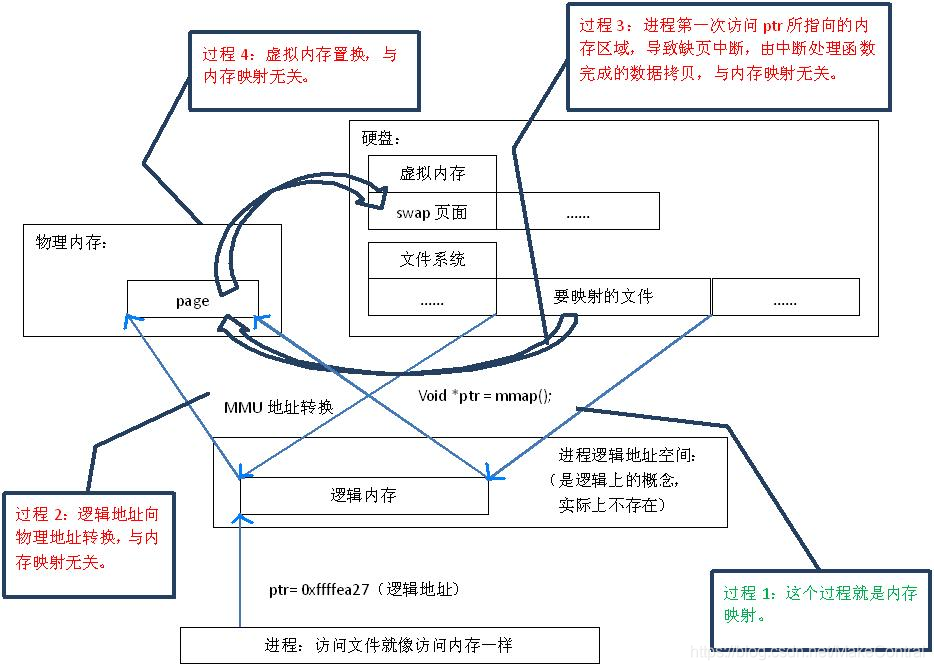
既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?
mmap()会 返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作 文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。这个过程与内存映射无关。
前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺 页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬 盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。
用文件映射的方法对文件进行操作,效率要比read和write系统调用高,这是为什么呢?
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一 样的。
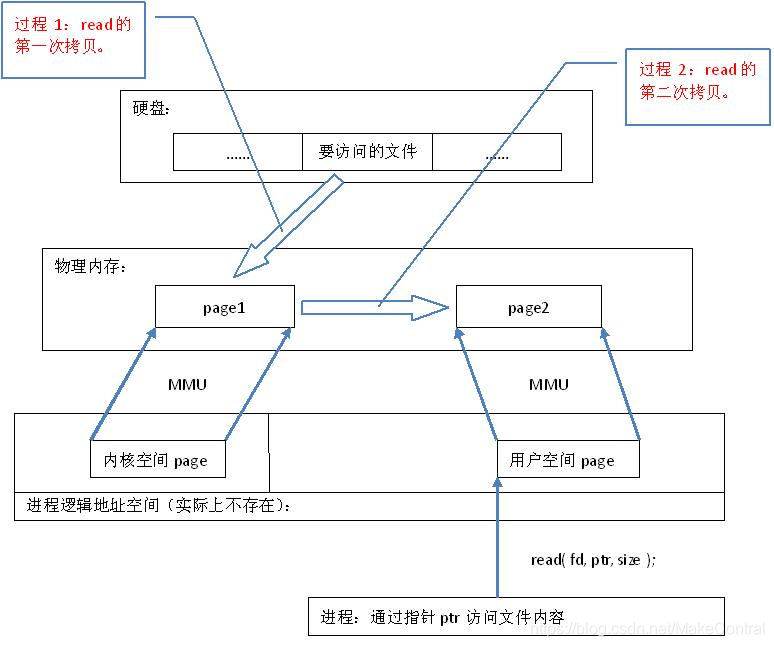
read()是系统调用,其中进行了数据 拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如下图中过程1,然后再将这些数据拷贝到用户空间,如下图中过程2,在这个过程中,实际上完成 了两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。
因此,内存映射的效率要比read/write效率高。
参考文章
https://www.cnblogs.com/volcao/p/8818199.html