上街课程回顾:
上节课主要讲了外部数据源,它的好出事可以加载不同文件系统上的,不同格式的数据(text不行,因为这个数据没有schema),以及外部数据源那几个关系的调用(熟练掌握这个,主要是为了实现自己定义修改数据源,这个可以尝试尝试的)
1.如何自定义外部数据源实现可插拔的方式?
2.PvUv
(1)Pv:url被用户访问的次数
(2)Uv:url被不同用户访问的次数(多了一次去重)
package SparkReview
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.execution.LogicalRDD
object SQL4 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().master("local[2]").getOrCreate()
val log=Array(
"2018-12-3,G302",
"2018-12-3,G303",
"2018-12-21,G301",
"2018-12-23,G301",
"2018-12-2,G301",
"2018-12-2,G311",
"2018-12-1,G301",
"2018-12-2,G302",
"2018-12-21,G301",
"2018-12-1,G301"
)
import spark.implicits._
val logRDD=spark.sparkContext.parallelize(log)
val logDF=logRDD.map(_.split(",")).map(x=>{Log(x(0),x(1))}).toDF
logDF.show(false)
//每天每个用户观看的视频次数 select date,count(1) from xx group by date
import org.apache.spark.sql.functions._
logDF.groupBy("date","user").agg(count("user").as("pv"))
.sort($"pv".desc)
.select("date","user","pv").show(false)
spark.stop()
}
case class Log(date:String,user:String)
}

(3)由下图可知,即使一点点数据也用了202个task,而且很多都是空的, 这是由上图的spark,sql,shuffle.partitions默认200决定的,很明显这是不合理的,如果数据量很大,200个可能导致资源不够,OOM或者跑的很慢,需要调整,但是手工调整是很难的,所以需要自动适配,再通过参数配置,找老大要,很复杂!!!

参数有没有生效直接到UI界面的环境里面看看就行了。
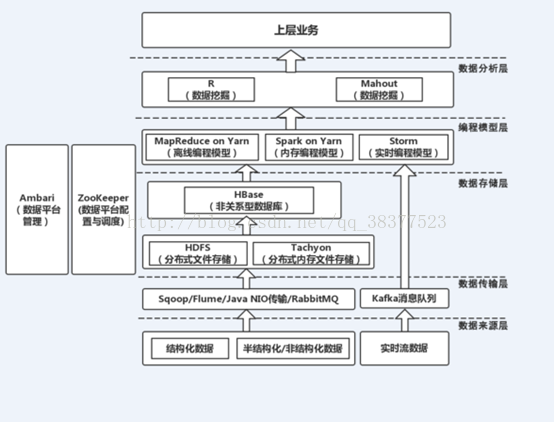
3.大数据整体架构图
4.spark自定义函数
(1)这个东西很有用,因为在SQL处理数据的时候肯定会有许多SQL自带函数解决不了的,所以这时候就需要自定义一些函数来
import org.apache.spark.sql.functions._
logdf.groupBy("IP","user").agg(count("user").as("PV")).sort('PV.desc).select("IP","user","PV").show(false)
val hobbyRDD=spark.sparkContext.textFile("E:\\若泽数据\\零基础大数据篇第三期\\Hadoop综合编程\\hobbies.txt")
val hobbyDF=hobbyRDD.map(_.split(" ")).map(x=>hobby(x(0),x(1))).toDF()
spark.udf.register("hobby_count",(x:String)=>x.split(",").size)
hobbyDF.createOrReplaceTempView("hobby_tmp")
spark.sql("select name as name2,hobbies,hobby_count(hobbies) as count from hobby_tmp").show(false)
//size返回数组的长度5.Spark SQL的愿景
(1)三点:
1)write less code
2)read less data
3)Let the optimizer do the hard work(复杂工作交给底层)
(2)外部数据源:比如当你的json数据格式很多的时候,spark是能自动推倒读取schema进来的。
(3)在大公司面试中,很少问你Spark SQL如何写都是问你RDD如何实现,因为这个十分考验基本功,你需要了解RDD的每个环节,如何去优化。
//TODO...只要name,salary>30000俩列,使用RDD实现。
val empRDD=spark.sparkContext.textFile("E:\\若泽数据\\零基础大数据篇第三期\\Hadoop综合编程\\person.txt")
.map(x=>{
val Array(name,age,salay)=x.split(",")
emp(name,age.toInt,salay.toDouble)
}).map({
case emp(name,_,salary)=>(name,salary)
}).filter(_._2 >30000).map(_._1).foreach(println)6.Spark 2.x里面的一些东西
(1)ds
(2)Catalog:在1.x的时候读取外部数据源只能用hive jdbc 那一套,但是有catalog就不用了,这个在你需要访问元数据的时候就用的上

(3)
SQL DF DS
Syntax Errors runtime Compile Compile
Analysis Errors runtime Runtime Compile
seletc name from xx
df.seletc("name")
df.select("nname")
ds.seletc("name")
ds.map(_.nname)
Analysis Errors reported before a distributed job starts.
val ds=spark.read.format("csv").option("inferSchema","true")
.option("header","true").load("F:\\BaiduNetdiskDownload\\Scala\\23-Spark SQL04\\资料\\sales.csv").as[sales]
ds.map(_.amountPaid).show(false)
spark.stop()
}
case class sales(transactionId:Int, customerId:Int, itemId:Int, amountPaid:Double)
优化:.set("spark.sql.files.maxPartitionBytes","256")。。。。。
1.并行度的优化,这要根据自己集群的配置来调节,默认情况下是200
spark.sql.shuffle.partitions=200
2.调节每个partition大小,默认 128M,可以适当调大点
spark.sql.files.maxPartitionBytes=256
3.小文件合并,默认是4M,可以调大点,不然每个小文件就是一个Task
spark.sql.files.openCostInBytes=4M
4.两个表shuffle,如join。这个最有用,经常使用的。
spark.sql.autoBroadcastJoinThreshold 默认是10M,调成100M,甚至是1G。