Hadoop系列之-Hbase数据设计问题
Hbase是一个基于HDFS,可通过MapReduce计算的分布式列式数据库,每行数据都有一个rowKey作为当前数据的唯一Sign,当然,也可通过Column Family将列进行分组。
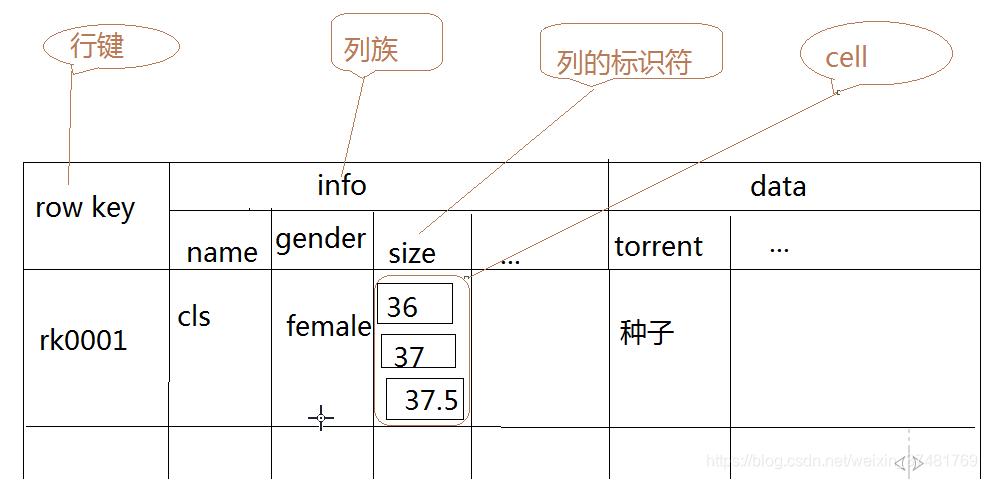
那么既然是一个分布式数据库,Hbase的表可以进行分区,Table在行的方向上可分割为多个Region,一个Region由[startkey,endkey]标识,每个HRegion分散在不同的RegionServer中。

- Hbase的分区方式有两种,热分区和预分区
- 热分区,热分区就是当一个RegionServer认为某张表数据量过大不得不分区时,会寻找一个midkey将region一分为二,这个过程称为分裂(region-split)
- 预分区,在建表是提前将Region的规则明确,那么数据添加时会直接根据rowkey和预定义的规则将数据插入到不同的Region中
很显然,热分区会造成数据倾斜、热点写、分裂频率随数据迅速增长等缺陷,那么预分区非常完美的解决了以上问题,但是这也引发了一个很严重的问题,就是数据不连贯。
- 笔者在开发中的一个非常棘手的问题:
- rowkey设计为 3050:650212#9852315625256(列号:车号:时间戳)
- 这种设计的结果就是预分区时根据列号进行分割,即每一个列车的数据都有独立的分区,那么假如我们需要通过对时间排序进行数据查询,就只能在同一列号下的数据进行查询。或者建立二级索引,但通过二级索引的查询网络IO是个问题,其实就是HDFS block的切换问题。