在浏览器环境下,一些强大的xpath标准方法没有被支持(如正则匹配方法matches()),只能利用有限的方法做抽取,下面是列出我常用的一些查找技巧、经验;不定时更新。
常用
以下面的分页组件节点结构为例:
<div class="pageList">
<span data-span style="display:none">.</span>
<span class="disabled">‹</span>
<span class="current" data-span>1</span>
<a href="" style="display:none"></a>
<a href="/Program/n-d-2-a-2">2</a>
<a href="/Program/n-d-2-a-3">3</a>
<a href="/Program/n-d-2-a-4">4</a>
<a href="/Program/n-d-2-a-5">5</a>
<a href="/Program/n-d-2-a-2">›</a>
<a href="/Program/n-d-2-a-30" class="last">... 30</a>
</div>
<div class="ad">
<a href='xxx'></a>
<a href="xxx"><img src="xxx" /></a>
</div>
"或"条件
选取"上一页"、"下一页"节点:
//div[@class="pageList"]/span[@class="current" and @data-span]
"与"条件
选取"上一页"、"下一页"节点:
//div[@class="pageList"]/*[text()="‹" or text()="›" ]
"非"条件
选取不含href属性的a节点:
//div[@class="pageList"]/a[not(@href)]
包含
选取href属性包含‘Program’的a节点:
//div[@class="pageList"]/a[contains(@href,'Program')]
选取href属性不包含‘Program’的a节点:
//div[@class="pageList"]/a[not(contains(@href,'Program'))]
判断是否数字
选取文本是数字的a节点:
//div[@class="pageList"]/a[string(number(text())) != 'NaN'];
父节点
选取ad中的包含img的a节点:
//div[@class="ad"]/a/img/parent::a
相邻兄弟节点
选取第4页a节点前面的第一个相邻节点(即第3页a节点):
//div[@class="pageList"]/a[text()="4"]/preceding-sibling::a[1]
选取第4页a节点后面的第一个相邻节点(即第5页a节点):
//div[@class="pageList"]/a[text()="4"]/following-sibling::a[1]
以特定字符开头或结尾
选取href属性以“/Program”开头的a节点(结尾使用的方法是ends-with):
//div[@class="pageList"]/a[starts-with(@href,"/Program")]
上下文
选取前三个a:
//div[@class="pageList"]/a[position()<=3]
选取最后一个a:
//div[@class="pageList"]/a[last()]
js 实现Xpath方法
function getElementsByXpath(xpathToExecute, element) {
element = (element === undefined)? document:element;
var result = [];
var nodesSnapshot = document.evaluate(xpathToExecute, element, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
for (var i = 0; i < nodesSnapshot.snapshotLength; i++) {
result.push(nodesSnapshot.snapshotItem(i));
}
return result;
}
//调用示例
getElementsByXpath('//div')
getElementsByXpath('//div', document.body)
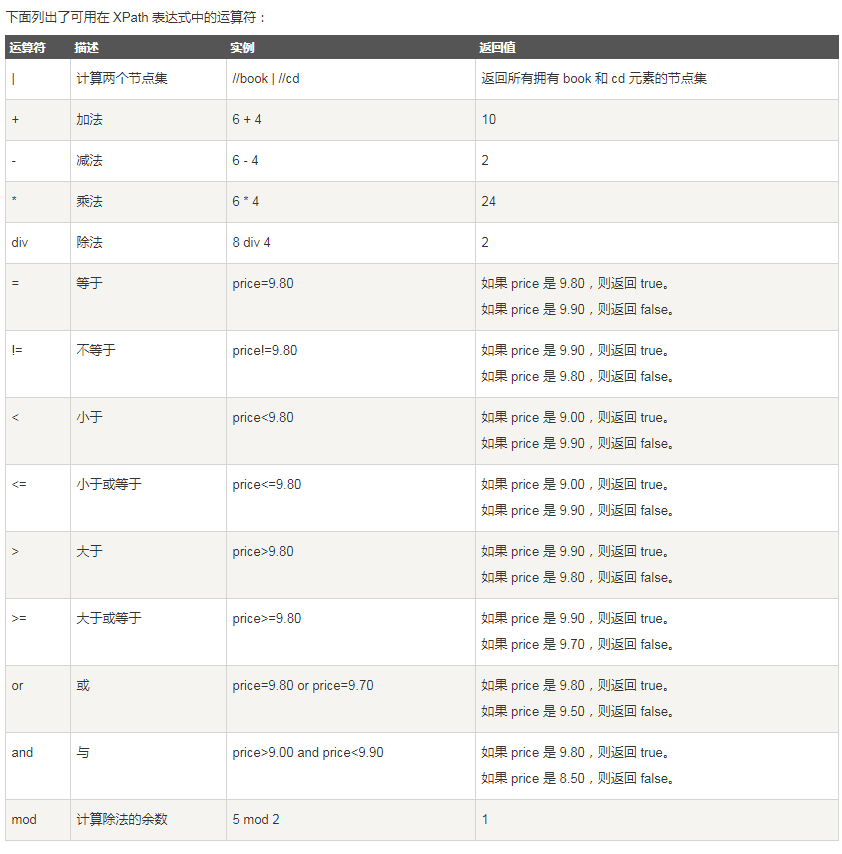
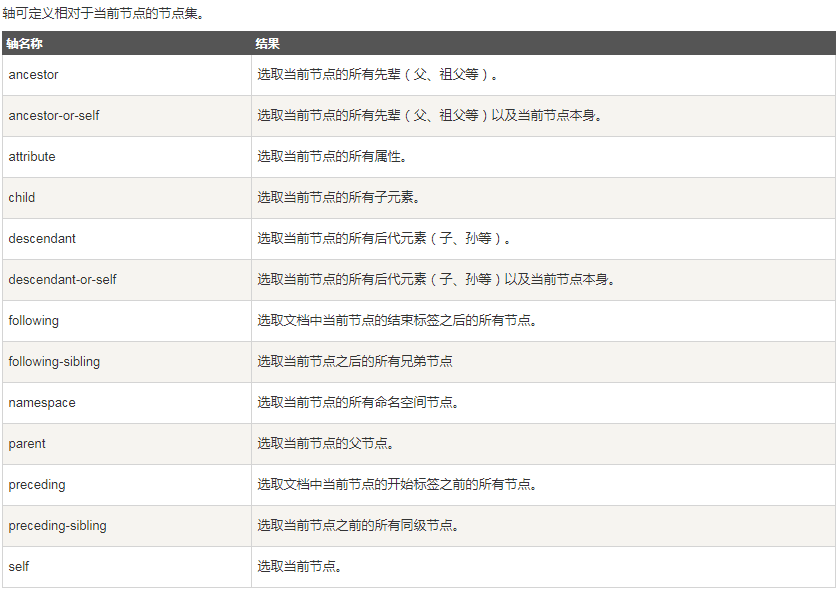
下面是标准轴和运算符,方便查看,这部分内容原文来自http://www.runoob.com/xpath/xpath-tutorial.html
XPath 运算符
XPath 表达式可返回节点集、字符串、逻辑值以及数字。