Spark创始人Matei最近在spark submmit上做了一次演讲,看了内容会发现spark这是要一统江湖的架势,一起来看看都介绍了什么内容。
Spark一直以来想做的一个事情就是统一整个大数据分析引擎,高层易用的API是核心竞争力。
随着2.2版本出来,看起来又更进了一步。2.2版本重点搞了下面三件事:在这里我还是要推荐下我自己建的大数据学习交流qq裙:458345782, 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份2018最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴

1) CBO:争抢数据仓库市场,解决性能问题。
2) 流引擎:支持毫秒级流处理,解决了原来只能通过mini batch方式支持流,直接PK flink。
3) 支持python api:python易上手的特点,在很多领域一直有应用,最新的机器学习领域用的最多的也是这个。
在spark的规划中,Spark未来会在两个地方发力:深度学习和流处理。


深度学习还处在很初级的阶段,主要是想在tensorflow、keras、bigdl等机器学习引擎的基础上提供更易用和高层的API。

为了可以处理深度学习,提供了一个深度学习库。https://github.com/databricks/spark-deep-learning


流处理相对成熟,已经具备生成环境的能力,在2.2会正式商用。

Event-time processing(flink是通过watermark机制来搞定)和支持Exactly once很有意思,回头看下具体是怎么实现的。
下图是spark的流API和kafka流代码对比,明显spark要比kafka好用。
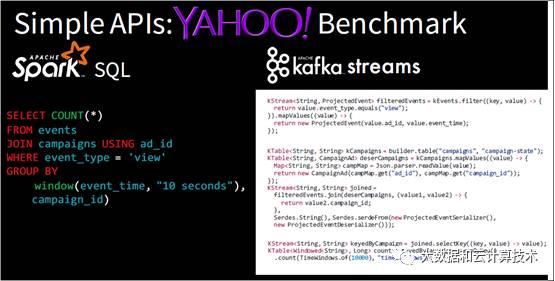
在演进最后吹了个牛逼,这个牛逼吹的响:“最早的现在也是最快的”。终于脱掉了流处理不行的帽子了。

Spark还是相当有前途,好好学吧。
在这里我还是要推荐下我自己建的大数据学习交流qq裙:458345782, 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份2018最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴