1.windows下安装sbt及scala的IDE:https://blog.csdn.net/weixin_42247685/article/details/80390858
2.新建scala_sbt工程
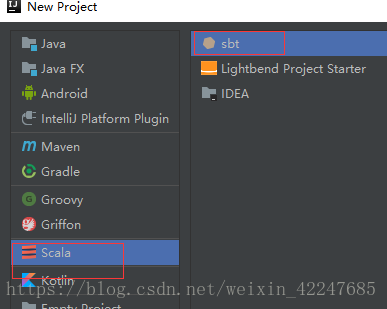
3.新建实例scala脚本:

脚本内容:
import java.io.File
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
object helloWorld {
def main(args:Array[String]): Unit = {
//val warehouseLocation = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
//.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
import spark.sql
sql("SELECT count(*) FROM dwb.dwb_trde_cfm_ordr_goods_i_d where pt = '2018-07-15'").show()
}
}上面内容复制后会一堆报错,不用管,因为依赖还没有添加。
4.IDE中sbt相关的设置修改下:
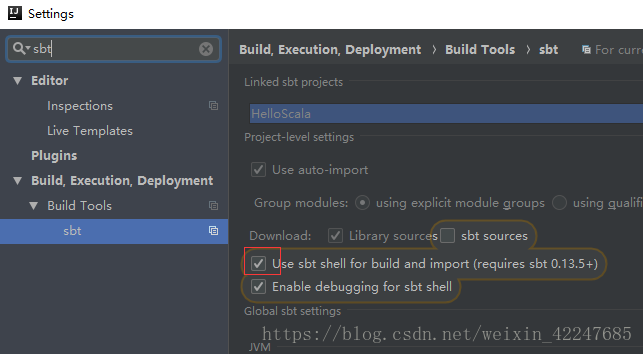
5.在build.sbt文件中添加下面的代码:

name := "Graph"
version := "0.1"
scalaVersion := "2.11.9"
updateOptions := updateOptions.value.withCachedResolution(true)
fullResolvers := Seq(
"Pdd" at "http://maven-pdd.corp.yiran.com:8081/repository/maven-public/",
"Local Maven" at Path.userHome.asFile.toURI.toURL + ".m2/repository",
"Ali" at "http://maven.aliyun.com/nexus/content/groups/public/",
"Repo1" at "http://repo1.maven.org/maven2/"
)
libraryDependencies += "org.rogach" %% "scallop" % "3.1.1"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-hive" % "2.1.1" % "provided"
//libraryDependencies += "org.apache.httpcomponents" % "httpclient" % "4.5.6"
//libraryDependencies += "net.liftweb" %% "lift-json" % "3.3.0"
libraryDependencies += "org.testng" % "testng" % "6.14.3" % Test
libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % Test
test in assembly := {}
//mainClass in assembly := Some("com.pdd.bigdata.risk.rimo.feature.Application")
assemblyMergeStrategy in assembly := {
case PathList(ps@_*) if ps.last endsWith "Log$Logger.class" => MergeStrategy.first
case PathList(ps@_*) if ps.last endsWith "Log.class" => MergeStrategy.first
case PathList("org", "jfree", xs@_*) => MergeStrategy.first
case PathList("jfree", xs@_*) => MergeStrategy.first
case "application.conf" => MergeStrategy.concat
case x =>
val oldStrategy = (assemblyMergeStrategy in assembly).value
oldStrategy(x)
}
上面代码中注释的地方改成自己的类名和工程名。
这是右下角会弹出是否import的提示,选择自动import,等待加载完毕。
6.在project下添加红框处的file文件
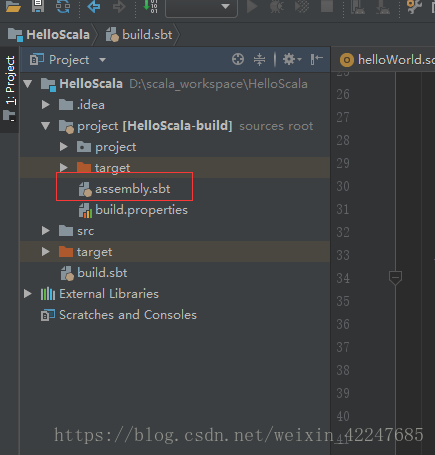
文件内容:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.7")完毕后所有报错会消失

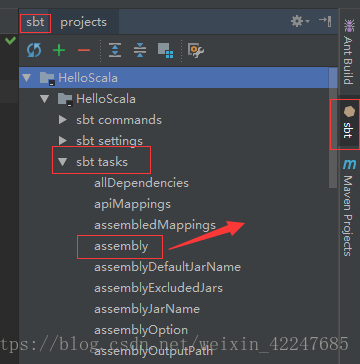
7.让IDE显示Tool Buttons(左图),在IDE右侧双击箭头处的assembly自动打包(右图),打包完成后在sbt_shell中会提示打包路径。
8.将打包的jar包上传至spark集群,然后运行下面命令:
spark-submit \
--class work._01_Graph_mallid_buyerid.step01_buildGraph \
--master yarn \
--deploy-mode cluster \
--files /etc/bigdata/conf/spark/hive-site.xml \
/home/buming/work/spark_scala/HelloScala-assembly-0.1.jar
注意:1.class后面是自己的类名。2.最后一行是jar包在spark上的路径(pwd可以查看)3.--deploy-mode 指定运行模式。