本文测试环境:MySQL5.7,Engine=InnoDB,charset=utf8。
【1】简解
先看一段官方的话:很多表都包含可为null(空值)的列,即使应用程序并不需要保存null也是如此,这是因为可为null是列的默认属性。通常情况下最好指定为Not null,除非真的需要存储null值。
如果查询中包含可为null的列,对MySQL来说更难优化,因为可为null的列使得索引、索引统计和值比较都更复杂。可为null的列会使用更多的存储空间,在MySQL里也需要特殊处理。当可为null的列被索引时,每个索引记录需要一个额外的字节。在MyISAM里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
通常把可为null的列改为not null带来的性能提升比较小,所以调优时没有必要首先在现有schema中查找并修改掉这种情况,除非确定这会导致问题。但是如果计划在列上建索引,就应该尽量避免设计为可为null的列。
当然也有例外,值得一提的是,InnoDB使用单独的位(bit)存储null值,所以对于稀疏数据有很好的空间效率。但这一点不适用于MyISAM。
【2】实验
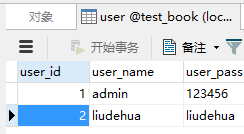
本地创建两个表,user 和user2,表字段一样,但是user中字段user_name不允许为null,user2中user_name default null,都为user_name添加上普通索引。
user表数据:
user2表数据:
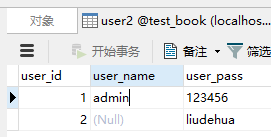
① NOT IN、!= 等负向条件查询在有 NULL 值的情况下返回的结果集有问题
如下所示:
select* from user2 where user_name !='admin'
查询结果如下:

无记录,拿不到user_id为2的行记录。
user2再增加一行数据:
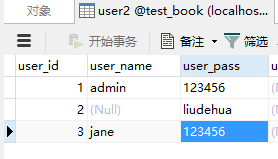
再次使用上述SQL查询:
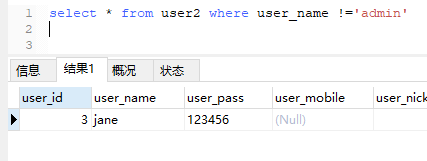
user_id 为2 的行记录拿不到!
使用not in测试同上:
select * from user2 where user_name not in
(select user_name from user2 where user_id != 1)
② 在使用null作为条件判断时,应该使用is null/is not null ,而不要使用= / !=
select * from user2 where user_name is null;
select * from user2 where user_name is NOT null;
③ 使用 concat 函数拼接时,首先要对各个字段进行非 NULL 判断,否则只要任何一个字段为空都会造成拼接的结果为 NULL。
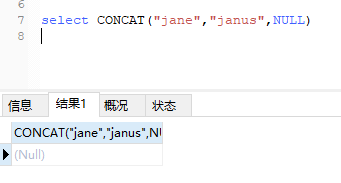
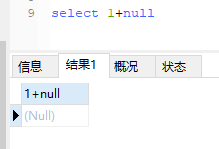
null同样不能用于算数运算:
④ 行记录统计中null的区别
select count(2) from user2;--2
select count(*) from user2;--2
select count(user_name) from user2;--1
如上所示,在使用count(列名)进行统计时,null不会计入统计。
count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
⑤ NULL 列需要更多的存储空间,一般需要一个额外的字节作为判断是否为 NULL 的标志位。
如果你仔细观察 user 和user2表的 key_len,会发现 user2 比user 多了一个字节。
explain select * from user where user_name ='admin'

explain select * from user2 where user_name ='admin';

key_len 的长度一般跟这三个因素有关,分别是数据类型,字符编码,是否为 NULL。
因此,user2比 user1 多出的这一个字节,用于作为判断是否为 NULL 的标志位了。