第一章:自动化测试简介
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。通常,在设计了测试用例 并通过评审之后,由测试人员根据测试用例中描述的规程一步步执行测试,得到实际结果与期望结果的比较。
一 分层自动化测试
1:UI界面层(10%)前端
包括:(1)UI自动化测试;
(2)JS自动化测试
2:API层(业务逻辑层)service 20% 数据处理逻辑;
包括:(1)模块接口测试
(2)Web接口测试
3:数据处理层 unit70%;
包括:(1)单元测试;
(2)code Review
分层思想:每一层做自己该做的事,这样很早就可以暴露错误
二:常见单元测试框架
JAVA(junit testNG) C#(NUIT) python(unitest pytest) JS(Qunit)
UI(前端发起请求) Server(后端提供数据) response到前端然后由前端进行渲染展示
三:适合UI自动化测试场景(一般用于回归,频繁的回归过程)
1.任务测试明确,不会频繁变动;
2.回归测试比较频繁;
3.界面比较稳定;
4.有大量重复任务;
5.软件的维护周期较长;(快速迭代不适合UI自动化)
6.项目进度方面压力较少;
7.测试人员具备较强编程能力;
UI自动化用例来源于手工用例.功能用例
a;不适合UI自动化测试的如:音乐播放器,视频播放器
部分自动化测试:把一些核心的测试场景变为自动化形式
四:常用自动化测试工具
1:UTF=QTP+St 主要用于回归测试和同软件新版本测试,支持B/S和C/S架构;
2:Robot Framework(只知道关键字就行)基于关键字的自动化封装
python编写的功能自动化测试框架。具备良好的可扩展性,支持关键字驱动,可以同时测试多种类型的客户端或者接口,可以进行分布式测试执行。主要用于轮次很多的验收测试和验收测试驱动开发
3:selenium 一个用于Web应用程序测试的工具,支持多平台,多浏览器,多语言去实现自动化测试
五:Selenium1.0组成
1:selenium IDE
Firefox浏览器中的一个小插件,实现浏览器操作的录制与回放;
2:arid:分式的测试用例在多个环境中分布式执行
用来对测试脚本做分布式执行,即实现在多台机器上和异构环境中运行测试用例(分布式的概念是写好一条用例可以调用不同的平台执行,如 A电脑上有一个测试用例,可以调用B电脑(linux)的 Firefox浏览器来跑A电脑上的测试用例;也可以调用C电脑(windows)的 Chrome浏览器来跑A电脑上的测试用例,这是分布式的概念)
3:RC(核心)典型的CS架构
使用浏览器内置的JavaScript 翻译器来翻译和执行selenese命令(selenese 是 selenium 命令集合),支持多种不同的语言编写测试脚本,通过selenium RC的服务器作为代理服务器去访问应用,达到测试的目的。
(1)Lilent libraries(暴露调用API,发起请求到server)
(2)Selenium server(分析之前的规则,拦截请求,分析请求实现动作) 负责控制浏览器行为。
Selenium Server 主要包括3 个部分:Launcher、Http Proxy、Core
a:Launcher(启动浏览器) 用于启动浏览器,把selenium Core加载到浏览器页面当中,并把浏览器的代理设置为selenium server的HTTP Proxy
b:HTTP proxy(设置代理,拦截请求)
c: Core 加载JS(javascript的函数集合)解释成selenese命令,实现用程序对浏览器进行操作。
Selenium2.0=1.0+webdriver(核心),可直接操作控制浏览器,提供更出色的API,
更快更安全,将RC和webdriver合并。
Selenium3.0 Firefox独立化,对IE、Edge等浏览器有了更好的支持。彻底废弃了RC
六:Selenium环境搭建
1:在线安装
在python的pip路径下打开cmd,输入pip install selenium
Pip可以安装python的一些库,setuptools的所有包都在set-packages库下;
2:离线安装
1)文件下载后,windows+R+cmd, cd+路径,输入python setup.py install
3:Firefox中安装IDE
1)安装IDE,将下载好的IDE文件直接拖拽进Firefox浏览器中即可。
2)安装好之后在右上角打开IDE就可以开始录制与回放了
4:input(输入的标签)
#coding=utf-8 设置编码格式为UTF-8格式(作用是防止乱码)
七:
1:Selenium中定位元素:
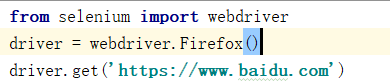
首先webdrive打开浏览器进入百度主页,
from selenium import webdriver 导入selenium的webdrive包
driver = webdriver.Firefox()初始化了一个Firefox的驱动,把webdriver的Firefox对象赋值给driver;
driver.get(‘https://www.baidu.com’)打开浏览器
2:通过ID定位输入框,input标签
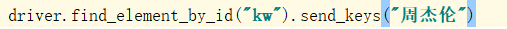
3:通过name定位输入框,
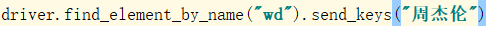
4:通过class定位输入框:但class属性值有空格一般不用此方法;

5: 通过patail_link定位输入框:通过部分文字去定位标签

6:通过link_text定位输入框(必须是全文字可点击的)

7:通过xpath定位输入框:定位框没有属性值时可用,绝对路径定位时用/,相对路径用//

8:通过CSS定位输入框:使用相对路径定位
使用ID定位:有ID属性用#号

使用class定位:有class属性用.号
八:webdrive 其他的一些常用的API
1:回退
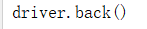
2:前进

3:刷新

4:设置窗口尺寸

5:最大化浏览器

6:清空

7:获取百度输入口尺寸
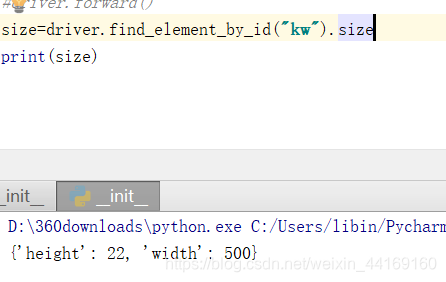
8:获取文本信息(可与预期文字进行对比)

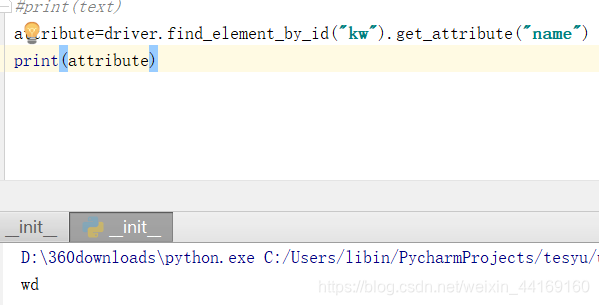
9:获取属性值
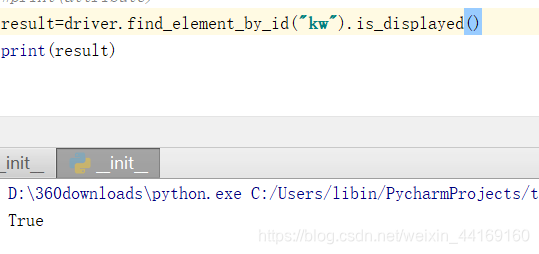
10:判断页面是否显示出来
11:(跳转型的需要有等待时间有加载过程)下面是等待5秒
