正则表达式:
我们先从一个需求的实现做起;
现在我们有这样一个需求:校验qq号码.它的要求是必须是5 - 15 位数字并且0不能开头;
那以我们平时的想法,一定是先获取qq号码的字符串,
1.然后用if语句判断,先判断它的长度,即qqnum.length<=15&&qqnum.length>=5;
2.然后用字符串的特有方法startWith(),判断首字符是否为0;
3.然后for循环判断每个字符是否为0-9的数字;
4.同时设置标志位,以上三点,有那点不满足,就flag = false;
我们发现上面的方法是可以达到目的的,但是显然很费劲,我们if判断有三层,同时用for循环,增加了时间复杂度和代码复杂度;而且这只是很简单的两个需求,那我们这么做是很没有必要的,由此我们引入正则表达式;
- 正则表达式:通俗来说正则表达式就是一种正确规则的表达式,用作校验数据是否符合我们给定的规则;是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。其实就是一种规则。
那么就上面的例子来说,我们只需要三行代码就可达到目的;
private static boolean checkQQNumber2(String qqNum) {
String regx="[1-9][0-9]{4,14}";
boolean b = qqNum.matches(regx); //字符串中匹配正则表达式的方法 matches(regx)
return b;
}
上面的代码最主要的部分就是正则表达式的 =="[1-9][0-9]{4,14}"==这句正则就满足了上面我们所说的两个需求,是不是很简洁?
上面的正则我们可以将他分成两部分:
1.[1-9]即校验第一个字符是否是1-9之内的字符,这样就达到了首字符不为0的需求;
2. [0-9]{4,14}即检验后面的4-14个字符是否为从0-9的数字,这样达到了5-15位数字的需求;
以下是一些简单正则表达式规则:
A:字符
x 字符 x。举例:‘a’表示字符a
\ 反斜线字符。
\n 新行(换行)符 (’\u000A’)
\r 回车符 (’\u000D’)
B:字符类
[abc] a、b 或 c(简单类)
[^abc] 任何字符,除了 a、b 或 c(否定)
[a-zA-Z] a到 z 或 A到 Z,两头的字母包括在内(范围)
[0-9] 0到9的字符都包括
C:预定义字符类
‘ . ’ 任何字符。我的就是‘ . ’字符本身,怎么表示呢? \.
\d 数字:[0-9]
\w 单词字符:[a-zA-Z_0-9]
在正则表达式里面组成单词的东西必须有这些东西组成
D:边界匹配器
^ 行的开头
$ 行的结尾
\b 单词边界
就是不是单词字符的地方。
举例:hello world?haha;xixi
E:Greedy 数量词
X? X,一次或一次也没有 比如""空串 就是没有
X* X,零次或多次 大于等于1次 都算多次
X+ X,一次或多次
X{n} X,恰好 n 次
X{n,} X,至少 n 次
X{n,m} X,至少 n 次,但是不超过 m 次
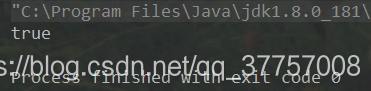
例如:判断手机号码是否满足规则;
public class MyDemo3 {
public static void main(String[] args) {
String phoneRgex="[1][35789][0-9]{9}";
boolean b = "15896871245".matches(phoneRgex);
System.out.println(b);
}
}
Java为我们封装了两个有关正则的方法;
Pattern是代表模式器,它用来封装我们定义好的正则表达式;
Matcher是代表匹配其,它封装要匹配的数据, 能够去匹配 等一系列操作;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MyDemo4 {
public static void main(String[] args) {
//用模式器 封装一个正则表达式
Pattern p = Pattern.compile("a*b+");
//通过模式器获取到了一个匹配器
Matcher m = p.matcher("aaaaabb");
//调用匹配器中的匹配的方法,去匹配匹配器中的字符串数据
boolean b = m.matches(); //调用Matcher中的matches方法,返回能否成功匹配的布尔值
System.out.println(b);
}
}
显然上面的结果是true。
正则表达式除了有匹配的功能以外还有许多实用的方法:
- 1.正则表达式的分割功能 split () 方法
split():按照某正则分割str,会返回分割后的字符串数组 ;它一般用来我们获取字符串中的有用数据,而去掉一些规则的连接符等字符;
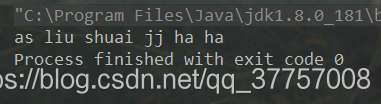
public class Test1 {
public static void main(String[] args) {
String s = "as--liu----shuai--jj-ha-ha";
//按照正则 -+ 分割字符串,结果存到一个字符数组中
String[] split = s.split("-+");
for (int i = 0; i < split.length; i++) {
System.out.print(split[i]+" ");
}
}
}
- 2.正则表达式的替换功能replaceAll()方法:
String类的功能:public String replaceAll (String regex, String replacement)
String str2="asdfasdfasdf11332111asfdadsfasdf45555544asfadfadsf";
String s1 = str2.replaceAll("[0-9]+", "");
System.out.println(s1);
上面就是将字符串中所有数字替换为空串,达到消除所有数字的目的;
- 3.获取匹配到的字符find(),group():
之前的例子我们都是正则匹配到,然后返回了能否匹配成功的布尔值,然而我们有时候会想要获取到所有匹配到的字符,而java也给我们提供了这样的配套方法,find()+group();
这两个方法都在Matcher类中有封装,它帮我们先找到(find)然获取出来(group)
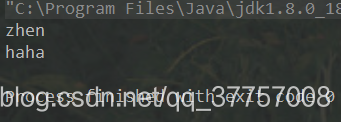
public class Test1 {
public static void main(String[] args) {
String s = "wo shi zhen de shuai,haha";
//匹配字符串中的四个字符组成的单词;
Pattern com = Pattern.compile("\\b[a-z]{4}\\b");//模式器封装
Matcher m = com.matcher(s);//获取匹配器
while (m.find()){ //匹配器寻找符合正则的单词
String group = m.group();
System.out.println(group);
}
}
}
注:先要find() 然后再去group ();直接group是无法获取到的!!