字符编码
python解释器在加载.py文件中的代码时,会对内容进行编码(默认ASCII)
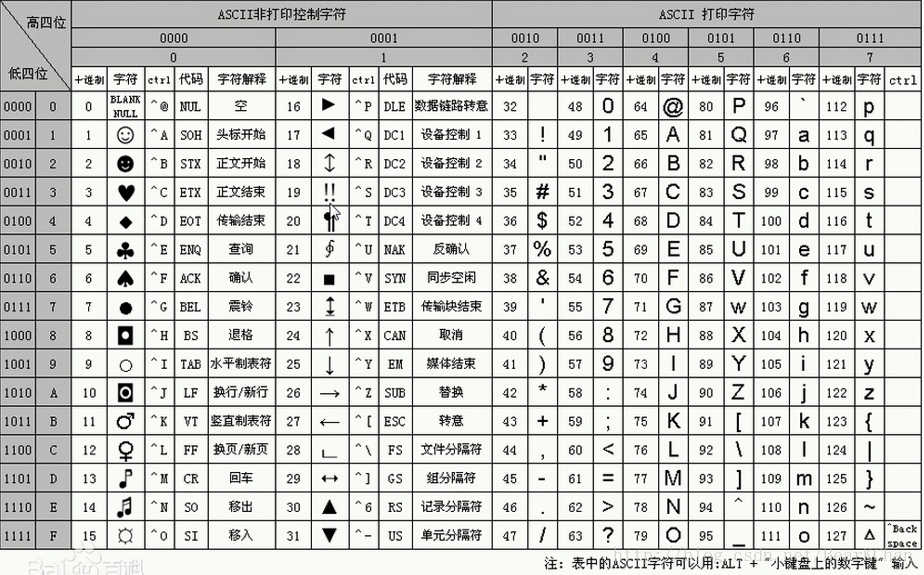
ASCII码
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用8位来表示(一个字节),ASCII码最多只能表示255个字符。
中文的处理
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
基本集共收入汉字6763个和非汉字图形字符682个。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。
把换算成十六进制的区位码加上2020H,就得到国标码。国标码加上8080H,就得到常用的计算机机内码。1995年又颁布了《汉字编码扩展规范》(GBK)。GBK与GB 2312—1980国家标准所对应的内码标准兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。
Unicode的出现
统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
UTF-8编码格式
utf-8编码格式规定中文统一占三个字节。
如何获取当前系统的默认代码格式?
import sys
print(sys.getdefaultencoding())字符转码
在Python3 中默认所有的字符都是Unicode,因此只需要encode不需要decode成Unicode了
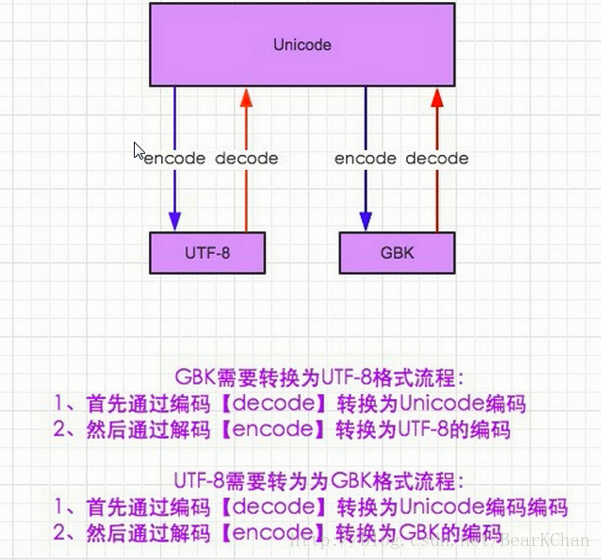
- 如果将字符串转换成gbk编码的话:
s = "unicode字符串"
s_gbk = s.encode("gbk")
如果将字符串转换成utf-8编码的话:
s_utf8 = s.encode("utf-8")如果将gbk格式的字符串转换为utf-8格式的话,需要先将gbk格式转换为Unicode格式再将Unicode转换为utf-8格式的编码:
gbk_to_utf8 = s_gbk.decode("gbk").encode("utf-8")
需要注意的是,encode之后的字符串会默认转换为bytes类型。