我们在开发的过程中,会经常遇到并发执行某个方法。在网上搜索答案的时候,都似乎Thread创建线程,或者就是先给你来一套JMM,线程之间内存,消息通信机制。
这种做法很好,巩固知识,如果现在就像要一个案例多线程执行方法,大批量的原理性介绍很费时费力,甚至会导致怀疑自己的水平。
现在有个业务需求是这样的:我要取story和joke两种类型里的数据。如果是串行操作就是
查询story,然后再查询joke。
如果数据量小没关系,如果数据量大,查询story要一个小时,查询joke也要一个小时,串行操作2小时,并发操作小于1小时(实测环境)。
首先创建一个线程池
private ExecutorService cacheExecutor = Executors.newCachedThreadPool();
查询story和查询joke,串行操作:
List<String> storySubTypeList = countStory("story");
List<String> jokeSubTypeList = countStory("joke");
那么我们不串行了,让他们并发执行。从直观来看速度就是很快了,可以提升一倍。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
//查询story然后操作数据
cacheExecutor.execute(new Runnable() {
@Override
public void run() {
List<String> storySubTypeList = countStory("story");
for(int i=1; i<=6; i++) {
//查询方法,为了显示直观,这行代码我换行了。
log.info("call "+this.getClass()+"."
+Thread.currentThread().getStackTrace()[1].getMethodName()
+"inputParam:"+storySubTypeList.get(i));
//查询方法,为了显示直观,这行代码我换行了。
List<String> ids =
storySearchDao.searchIds("story",
storySubTypeList.get(i), Common.STORY_ID_LIST_MAXNUM, 0);
storyTypeMap.put(storySubTypeList.get(i), ids);
}
}
});
//查询joke然后操作数据
cacheExecutor.execute(new Runnable() {
@Override
public void run() {
List<String> jokeSubTypeList = countStory("joke");
for(int i=1; i<=6; i++) {
//打印日志,为了显示直观,这行代码我换行了。
log.info("call "+this.getClass()+"."
+Thread.currentThread().getStackTrace()[1].getMethodName()
+"inputParam:"+jokeSubTypeList.get(i));
//查询方法,为了显示直观,这行代码我换行了。
List<String> ids =
storySearchDao.searchIds("story",
jokeSubTypeList.get(i), Common.STORY_ID_LIST_MAXNUM, 0);
storyTypeMap.put(jokeSubTypeList.get(i), ids);
}
}
});
代码里形如:storyTypeMap,storySearchDao,countStory,不用纠结其意思。我这里表达是如何快速实现线程池创建任务,然后使用线程。
在《Java并发编程艺术》一书中介绍到:
(下面的内容可以看,可以不看。建议看,我认为是这本书总结特别好的地方)
通过Executor框架的工具类Executors,可以创建3种类型的ThreadPoolExecutor
- FixedThreadPool
FixedThreadPool被称为可重用固定线程数的线程池。FixedThreadPool的corePoolSize和maximumPoolSize都被设置为创建FixedThreadPool时指定的参数nThreads
当线程池中的线程数大于corePoolSize时,keepAliveTime为多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。这里把keepAliveTime设置为0L,意味着多余的空闲线程会被立即终止
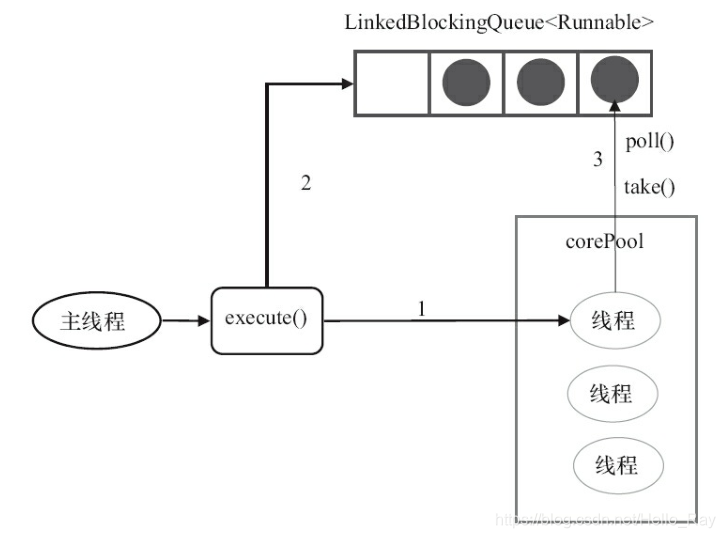
对于图中解释:
1)如果当前运行的线程数少于corePoolSize,则创建新线程来执行任务。
2)在线程池完成预热之后(当前运行的线程数等于corePoolSize),将任务加入
LinkedBlockingQueue。
3)线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue获取任务来执行。
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。使用无界队列作为工作队列会对线程池带来如下影响。
1)当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中
的线程数不会超过corePoolSize。
2)由于1,使用无界队列时maximumPoolSize将是一个无效参数。
3)由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
4)由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。
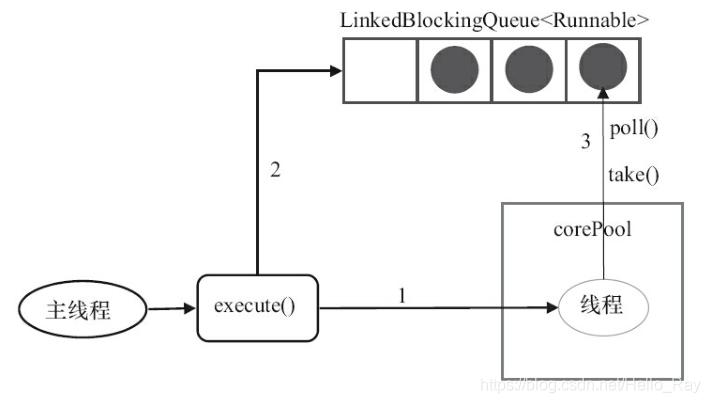
- SingleThreadExecutor
SingleThreadExecutor是使用单个worker线程的Executor。FixedThreadPool相同。SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。SingleThreadExecutor使用无界队列作为工作队列对线程池带来的影响与FixedThreadPool相同
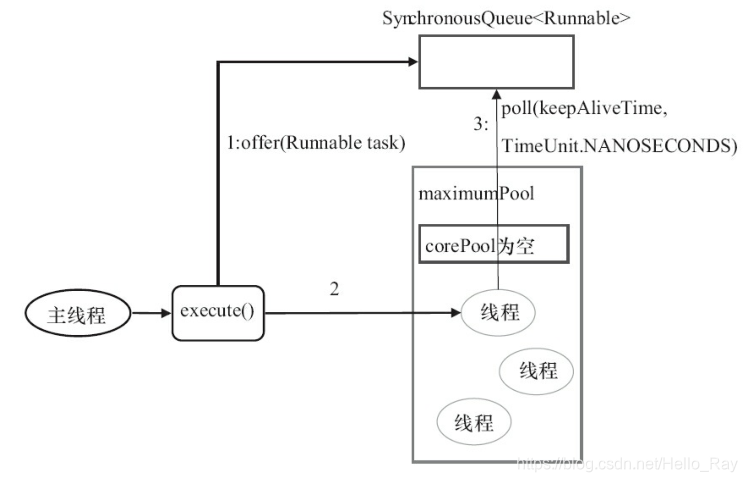
- CachedThreadPool
CachedThreadPool是一个会根据需要创建新线程的线程池。
CachedThreadPool的corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。这里把keepAliveTime设置为60L,意味着CachedThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
FixedThreadPool和SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列。CachedThreadPool使用没有容量的SynchronousQueue作为线程池的工作队
列,但CachedThreadPool的maximumPool是无界的。这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool会不断创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源。
水平原因,难免存在错误,希望指出或者联系我 [email protected]