Java-JVM-编译原理
转载声明:
本文大量内容系转载自以下文章,并参考其他文档资料加入了一些内容:
- JVM系列第4讲:从源代码到机器码,发生了什么?
作者:陈树义
来源:博客园 - 深入分析Java的编译原理
来源:Hollis
转载仅为方便学习查看,一切权利属于原作者,本人只是做了整理和排版,如果带来不便请联系我删除。
摘要
我们可以通过javac命令将Java程序的源代码编译成Java字节码,即我们常说的class文件。这是我们通常意义上理解的编译。但是,字节码并不是机器语言,要想让机器能够执行,还需要把字节码翻译成机器指令。这个过程是Java虚拟机做的,这个过程也叫编译。是更深层次的编译。在编译原理中,把源代码翻译成机器指令,一般要经过以下几个重要步骤:
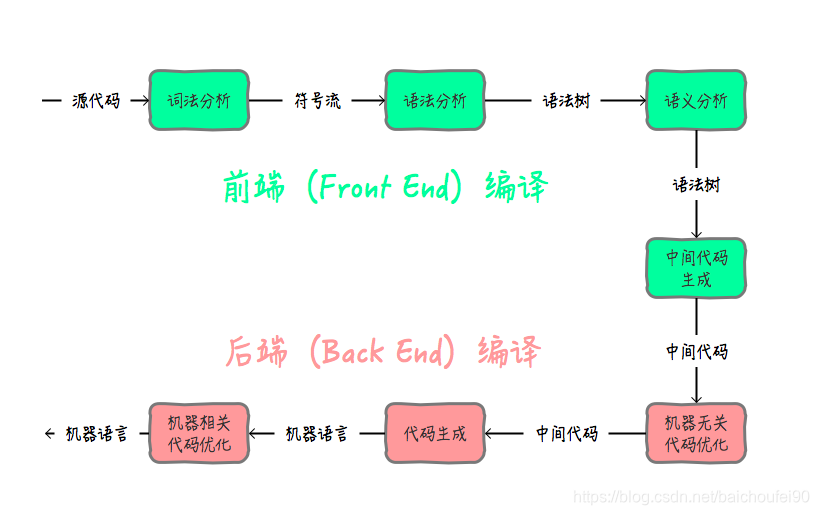
根据完成任务不同,可以将编译器的组成部分划分为前端(Front End)与后端(Back End):
- 前端编译主要指与源语言有关但与目标机无关的部分,包括词法分析、语法分析、语义分析与中间代码生成。将.java文件编译成.class的编译过程称之为前端编译。
- 后端编译主要指与目标机有关的部分,包括代码优化和目标代码生成等。将.class文件翻译成机器指令的编译过程称之为后端编译。
如下图所示,编译器可以分为:前端编译器、JIT 编译器和AOT编译器。下面我们逐个讲解。

0x01 前端编译器:源代码到字节码
1.1 基本概念
对于 Java 虚拟机来说,其实际输入的是字节码文件,而不是 Java 文件。JDK 的安装目录里有 javac 工具,就是它将 Java 代码翻译成字节码。相对于后面要讲的其他编译器,因为Javac处于编译的前期,因此又被成为前端编译器。
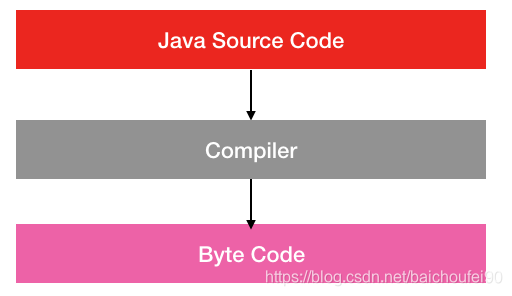
1.2 例子
通过 javac 编译器,我们可以很方便地将 java 源文件翻译成字节码文件。就拿我们最熟悉的 Hello World 作为例子:
public class Demo{
public static void main(String args[]){
System.out.println("Hello World!");
}
}
我们使用 javac 命令编译上面这个类,便会生成一个 Demo.class 文件:
javac Demo.java
我们使用纯文本编辑器打开 Demo.class 文件,我们会发现是一连串的 16 进制二进制流。

1.3 javac流程
运行 javac 命令的过程,其实就是 javac 编译器解析 Java 源代码,并生成字节码文件的过程,可以分为下面四个阶段:
- 词法、语法分析
JVM 对源代码的字符进行一次扫描,经过词法分析(源码CharStream转为Tokens),语法分析,最终生成一个抽象的语法树。语法树每一个节点都代表代码中一个语法结构,如包、类型、运算符。

- 填充符号表
符号表由一组符号地址和符号信息构成,在编译不同阶段都需使用。语义分析中,符号表所登记的内容用于语义检查和生成中间代码。
我们知道类之间是会互相引用的,但在编译阶段,我们无法确定其具体的地址,所以我们会使用一个符号来替代。在这个阶段做的就是类似的事情,即对抽象的类或接口进行符号填充。等到类加载阶段,JVM 会将符号替换成具体的内存地址(解析阶段,符号引用转直接引用)。 - 注解处理
在这个阶段会对注解进行分析,根据注解的作用将其还原成具体的指令集。
JDK1.6之前注解是在运行期起作用,JDK1.6提供了插入式注解处理器在编译期处理注解,相当于编译器插件,会按需修改抽象语法树,所以一旦修改了AST,会回到第一步重复前三步,直到注解处理不再修改AST。 - 语义分析
语义分析(包括标注检查和数据及控制流分析、解语法糖(泛型、自动装拆箱等)等)。主要是对结构上正确的源码(语法分析阶段确认)进行上下文检查,如类型检查(比如boolean b=false;char c=2;int d=b+c就有问题了)。最终得到标注了属性的AST。 - 字节码生成
javac 编译的最后阶段是字节码生成,JVM 便会根据上面几个阶段分析出来的结果(AST, 符号表等)转换为字节码写入磁盘,还会新增(如clinit和init(不包括已在填充符号表时已执行的默认构造方法)在这时被添加到AST中)和转换(如将String的加转为StringBuilder.append)少量代码。
我们一般称 javac 编译器为前端编译器,因为其发生在整个编译的前期。常见的前端编译器有 Sun 的 javac,Eclipse JDT 的增量式编译器(ECJ)。
0x02 JIT 编译器:从字节码到机器码
2.1 基本概念
2.1.1 两种运行模式
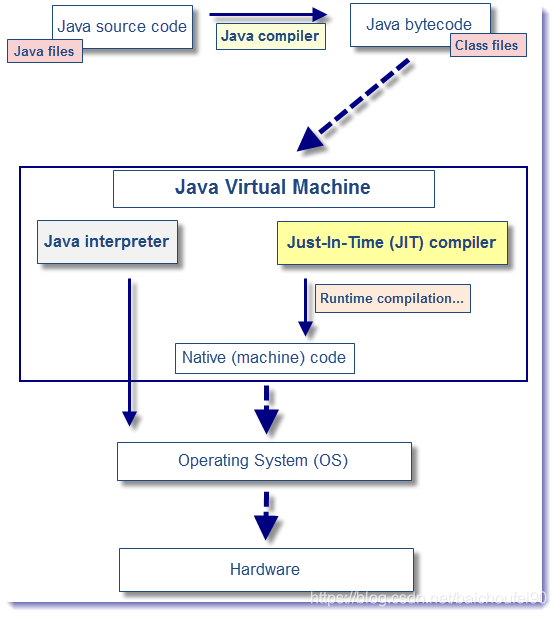
当源代码转化为字节码之后,要运行程序有两种选择:
- 使用 Java 解释器来直接解释执行字节码(基于栈的指令集)。
首先java源代码编译(javac)称为.class文件,JVM的类加载器加载字节码到方法区后,JVM内置的解析器会解释执行,一行一行到把字节码转换为机器语言再运行 - 使用 JIT 编译器将字节码转化为本地机器代码执行
由于大部分程序都表现出“小部分热点代码消耗大部分的资源”,这里的热点代码就是高频率调用的代码块,类似“二八定律”,于是引入了JIT(方法级),也就是动态编译器,利用了在运行时进行热点代码编译的技术,直接将字节码编译为本地机器码,JIT会缓存编译过的代码到Code Cache里(HotSpot在启动时,会为所有字节码创建在目标平台上运行的解释运行的机器码,并存放在CodeCache中,在解释执行字节码的过程中,就会从CodeCache中取出这些本地机器码并执行。),且之后无需重复解释。且在此过程中,会有大量优化策略!
这两种方式的区别在于,前者启动速度快但运行速度慢(指令较多、基于内存是瓶颈速度慢于寄存器),而后者启动速度慢但运行速度快。因为解释器不需要像 JIT 编译器一样,将所有字节码都转化为机器码,自然就省去了优化的时间。而当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。且在JIT编译过程中,会有大量优化策略!
2.1.2 解释器和编译器配合
- 当程序需要迅速启动和执行的时候,解析器首先发挥作用,省去编译的时间,立即执行。随着时间的推移,编译器发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。
- 当机器内存限制比较大,可以用解析方式节约内存,反之可以用编译提升效率。
- 解析器还可以作为编译器的“逃生门”。当例如加载了新类后类型结构发生变化,可以采用逆优化,退回到解析状态继续执行。
2.1.3 混合模式
所以在实际情况中,为了运行速度以及效率,我们通常采用解释器和JIT相结合的方式(即混合模式)进行 Java 代码的编译执行。
2.2 C1与C2
2.2.1 简介
在 HotSpot 虚拟机内置了两个即时编译器,分别称为 Client Compiler 和Server Compiler。这两种不同的编译器衍生出两种不同的编译模式,我们分别称之为:C1 编译模式,C2 编译模式。
注意:现在许多人习惯上将 Client Compiler 称为 C1 编译器,将 Server Compiler 称为 C2 编译器,但在 Oracle 官方文档中将其描述为 compiler mode(编译模式)。所以说 C1 编译器、C2 编译器只是我们自己的习惯性称呼,并不是官方的说法。这点需要特别注意。

2.2.2 C1 和 C2 对比
- C1 编译模式会将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。针对启动性能有要求的客户端GUI程序。
- C2 编译模式,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。针对性能峰值。且在JDK1.7后,为了均衡启动速度和运行效率,Server模式JVM采用了分层编译为默认编译策略,会根据编译器编译、优化的规模和耗时,划分不同的编译层次:
- 0层:程序直接解释执行,
- 1层,即C1编译。将字节码编译为本地机器代码,
- 2层或2层以上:C2编译。
在分层编译中,C0不需要再搜集性能监控信息。C1(更高编译速度)和 C2同时工作(更好的编译质量),代码可能多次编译。
2.3 热点代码
2.3.1 热点代码分类
前面提到的会被JIT编译的热点代码有两类:
- 被多次调用的方法
JIT会以整个方法作为编译对象,该方式是JVM中标准的JIT编译方式。 - 被多次执行的循环体
JIT会以整个方法而不是循环体作为编译对象
2.3.2 探测方法分类
目前主要的热点代码识别方式是热点探测(Hot Spot Detection),有以下两种:
- 基于采样的方式探测(Sample Based Hot Spot Detection) :周期性检测各个线程的栈顶,发现某个方法经常出险在栈顶,就认为是热点方法。
好处就是简单;缺点就是无法精确确认一个方法的热度。容易受线程阻塞或别的原因干扰热点探测。 - 基于计数器的热点探测(Counter Based Hot Spot Detection)。采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,某个方法超过阀值就认为是热点方法,触发JIT编译。
好处是统计结果精确;缺点是这种方式需为每个方法维护一个计数器,且无法直接获取方法间调用关系
2.3.3 热点探测计数器
HotSpot使用基于计数器的热点探测方法,为每个方法准备两个计数器。他们都会先查看是否存在已编译版本,如果有就优先执行已编译的本地代码。否则计数器加一,然后判断两个计数器之和超过阈值就触发JIT编译,否则以解释方式继续执行:
-
方法计数器。记录方法被调用次数。
-
回边计数器。是记录方法中的for或者while的运行次数的计数器。
-
关于OSR栈上替换
在回边计数器中,编译动作由循环体触发,编译器会以整个方法作为编译对象,也就是说会在方法执行过程中进行编译。那么就会发生方法栈帧还在栈内,方法就被替换了,即所谓OSR栈上替换。
2.3.4 解释、编译和阻塞
在触发编译时,执行引擎不会等待编译完成而是再继续解释执行字节码,直到编译完成,将方法的调用入口地址直接替换为新的编译后的代码地址。以后调用就可以都用已编译版本。
2.4 JIT编译优化
JIT除了具有缓存的功能外,还会对代码做各种优化。典型的有:
逃逸分析、 公共子表达式消除、方法内联、 数组边界检查消除、锁消除、锁粗化等
0x03 AOT 编译器:源代码直接到机器码
AOT 编译器的基本思想是:在程序执行前将源码直接生成 Java 方法的本地代码,以便在程序运行时直接使用本地代码。
但是 Java 语言本身的动态特性带来了额外的复杂性,影响了 Java 程序静态编译代码的质量。例如 Java 语言中的动态类加载,因为 AOT 是在程序运行前编译的,所以无法获知这一信息,所以会导致一些问题的产生。类似的问题还有很多,这里就不一一举例了。
总的来说,AOT 编译器从编译质量上来看,肯定比不上 JIT 编译器。其存在的目的在于避免 JIT 编译器的运行时性能消耗或内存消耗,或者避免解释程序的早期性能开销。
在运行速度上来说,AOT 编译器编译出来的代码比 JIT 编译出来的慢,但是比解释执行的快。而编译时间上,AOT 也是一个中等的速度。所以说,AOT 编译器的存在是 JVM 牺牲质量换取性能的一种策略。就如 JVM 其运行模式中选择 Mixed 混合模式一样,使用 C1 编译模式只进行简单的优化,而 C2 编译模式则进行较为激进的优化。充分利用两种模式的优点,从而达到最优的运行效率。
0x04 思考
- 为什么Java不直接解释执行源码?
- 使用字节码,可以避免每次执行时词法、语法、语义分析之类的重复性工作。
- 字节码更便于虚拟机读取,不用在解析字符串,所以运行速度比直接解析源代码快。
- 语法是会变的,而源代码中没有版本信息,而字节码中不但有版本信息,还可以经由编译过程抹平一些语言层面的变化(即语言语法虽然有变化,但字节码依然遵照原来的规则即可)。
- 字节码也可以由其他语言生成,如Groovy,Clojure,Scala。需要注意的事,既然这些语言可以编译成字节码,也就可以被Java或其他JVM语言调用。
- 字节码比源码更加紧凑,文件尺寸更小,方便网络传输。
- 有些嵌入设备,不够资源跑起完整的编译器,这些设备只需要嵌入一个小巧的JVM就行了,在额外的平台上编译源码。
0x05 解释器FAQ
- 解释器是一个转换高级语言源码到机器编码的程序?
错误。
这是编译器干的事。解释器用来解释执行非本地代码(如Java的字节码) - Java解释器的输入是二进制代码(前端编译中由java编译器将源码编译为二进制字节码)?
正确 - Java解释器是JVM的一部分,他运行在JVM中,所以解释器将生成由JVM运行的代码?
错误
字节码解释器是JVM的一部分,但是并不运行在JVM中。而且字节码解释器不产出任何东西,而是直接解释执行字节码 - 解释器用字节码生成中间代码和目标机器代码,并提交给JVM?
错误
以上工作是JVM做的事情 - JVM轮流在实现或运行JVM的OS平台上执行该代码?
错误
JVM使用字节码、优化后的用户代码、包含java lib和本地代码的java内库,以及OS调用来执行java应用程序。
0x06 总结
使用解释器实现的编程语言实现里,通常:
- 至少会在解释执行前做完语法分析,然后通过树解释器来实现解释执行;
- 兼顾易于实现、跨平台、执行效率这几点,会选择使用字节码解释器实现解释执行
在 JVM 中有三个非常重要的编译器,它们分别是:前端编译器、JIT 编译器、AOT 编译器。
-
前端编译器,最常见的就是我们的 javac 编译器,其将 Java 源代码编译为 Java 字节码文件。
-
JIT 即时编译器,最常见的是 HotSpot 虚拟机中的 Client Compiler 和 Server Compiler,其将 Java 字节码编译为本地机器代码。
-
而 AOT 编译器则能将源代码直接编译为本地机器码。
-
这三种编译器的编译速度和编译质量如下:
-
编译速度上,解释执行 > AOT 编译器 > JIT 编译器。
-
编译质量上,JIT 编译器 > AOT 编译器 > 解释执行。
-
而在 JVM 中,通过这几种不同方式的配合,使得 JVM 的编译质量和运行速度达到最优的状态。
参考文档
《深入理解Java虚拟机》
虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
How exactly does the Java interpreter or any interpreter work?