菜鸡刚学汇编,总结下。
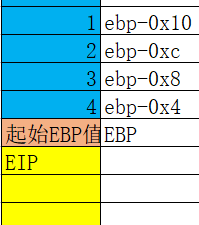
调用函数后,函数会开辟一块缓冲区,例如
push ebp
mov ebp,esp
sub esp,0x40
这个sub esp,0x40 就是开辟了缓冲区,不同编译器开辟的缓冲区的大小不同,不用在意这个大小。开辟的这块缓冲区用来存放局部变量。
堆栈中 单独存储的变量 ,每个都占4个字节的大小。并不是挨着存储的,这样虽然会造成空间浪费,但是可以减少寻址时间。这个是根据本机的位数定的,如果是32位的,占4个字节,如果是16位,就占两个字节。
小于32位的单个局部变量,分配内存时仍按32位分配,但使用时按实际的宽度使用,定义局部变量为char,short并不会节省空间
例如 c语言中
int main()
{
char a='a';
int b=1;
}
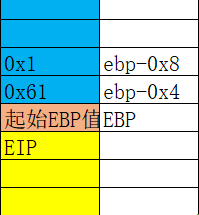
char类型 只占 EBP-4 这一格。

如果令 char a=12345678
则 a中实际的值是78(10进制)。
这样定义了两个局部变量,转化为汇编(debug版)即是
mov byte ptr ss:[ebp-0x4],0x61
mov dword pte ss:[ebp-0x8],0x1
每次都是减4,并不是挨着存储。
堆栈中的情况如下。
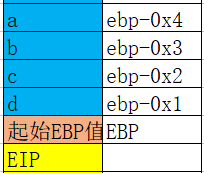
而数组的存储和单个局部变量不同。
数组的寻址公式是 :数组元素的首地址+数组元素类型所占字节数*n
数组中元素在栈中连续存储的,而且是数组的末尾先入栈。
例如 c语言
int main()
{
char a[4]={'a','b','c','d'};
}
···
堆栈图如下
int main()
{
int a[4]={1,2,3,4};
}
堆栈中的情况如下。