top:系统整体性能的评估(抓内存快照)
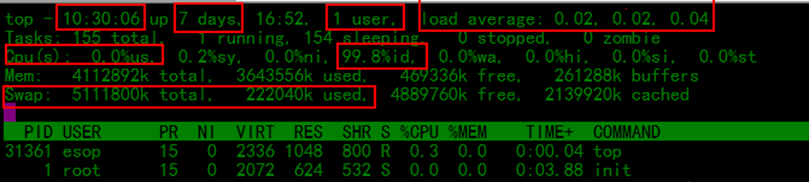
1 linux系统当前时间
2 从开机到目前运行了多久,
3 当前有几个用户连接到本台主机
4 load average: 负载均衡,当三个值相加后除以3结果大于0.6表示需要注意服务器负担。
5 Cpu使用率
6 99.8%id,该id是system idle process=处理器空闲时间百分比,越大越好
7 Swap,交换分区的值top实例
a) 根据top命令,发现PID为28555的Java进程占用CPU高达200%,出现故障。TIME:108 :表示108分钟

b) ps aux | grep 28555(PID) 命令,可以进一步确定是tomcat进程出现了问题。
ps -mp 28555(PID) -o THREAD,tid,time 找出该进程下的线程

c) 其次将线程的id转换为16进制格式 命令:printf "%x\n" (28802)tid
28802的16进制格式为7082
d) 最后打印线程的堆栈信息:jstack pid |grep tid(16进制) -A 30 : jstack 28555 |grep 7082 -A 30

e) 找到有问题的java代码,进行业务调整和编码修改
vmstat:CPU性能的评估
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数
vmstat -n 2 3 : 每隔2秒查一条记录 共查三条

Procs
r 列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
cpu
us列显示了用户进程消耗的CPU时间百分比。
us的值比较高时说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
sy列显示了内核进程消耗的CPU时间百分比。
Sy的值较高时,说明内核消耗的CPU资源很多。
据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。iostat:磁盘I/O性能的评估
[root@webserver ~]# iostat -d 2 3
Linux 2.6.9-42.ELsmp (webserver) 12/01/2008 _i686_ (8 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.87 2.58 114.12 6479462 286537372
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.00 0.00 12.00 0 24
对上面每项的输出解释如下:
Blk_read/s表示每秒读取的数据块数。
Blk_wrtn/s表示每秒写入的数据块数。
Blk_read表示读取的所有块数。
Blk_wrtn表示写入的所有块数。
可以通过Blk_read/s和Blk_wrtn/s的值对磁盘的读写性能有一个基本的了解,
如果Blk_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,
如果Blk_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。
对于这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值,
但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。free:内存性能的评估
free -m:以兆显示
[root@webserver ~]# free -m
total used free shared buffers cached
Mem: 8111 7185 926 0 243 6299
-/+ buffers/cache: 643 7468
Swap: 8189 0 8189
一般有这样一个经验公式:
应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能
应用程序可用内存/系统物理内存20%~70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能
应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存