此为《强化学习》第六章 Temporal-Difference Learning 。
时序差分学习 (Temporal-Difference Learning, TD) 是强化学习的核心。TD学习是蒙特卡洛MC法和动态规划DP法的综合,它可以像MC那样,不需要知道环境的全部信息,通过交互就能学习;同时,它也可以像DP那样,在(其他值函数)估计的基础上进行估计,从而不需要求解完整个事件(Episode)。
时序差分估计
在上一章的MC增量式实现一节,我们看到状态值函数的增量式更新表达式:
其中,
的部分为预测值和实际交互得到真实值之间的误差,而
则为误差的权重项。在Off-Policy的重要性采样中,权重项比较复杂;在On-Policy中,权重项只是
。本节中做的一个改进是,把权重项替换为一个常数
。从而状态值函数的更新式变成了:
(注意这里下标的变化,其实就是一回事。前面强调当个状态的更新,这里强调所有状态的更新)。上式的更新方法被称为常数
蒙特卡洛法 (Constant-
MC) 。但是,这种方法仍然需要求解
,因此需要等整个episode完成后才能完成每个状态的更新。因此我们提出时序差分的方法,用
来替代
,即
由于这里仅用了下一个状态
的值函数来估计,因此也被称为TD(0)方法。在下一章,我们将看到用更多步后的状态来估计值函数,就有了TD(n)方法。TD(0)方法的伪代码如下(比MC要简单很多):

下图为TD(0)的回溯图模型。可以看到,它使用了下一个状态的值函数来更新当前状态值函数。

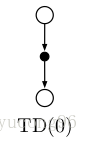
我们定义
为时序差分误差 (TD Error)
,因为
是一个更好的估计,它们和当前估计的差构成了
。如果一个算法在整个episode后再更新值函数(比如MC),那么有
如果算法在episode中更新值函数,但 步长不大,那么上述式子仍将近似满足(虽然我还不知道为什么要把它算出来)。
TD估计的优势
TD基于下一步的值函数来更新当前的值函数,但由于下一步也是估计出来的,因此可以说它在估计的基础上估计,这种方法被成为步步为营法( Bootstrap, 脱靴法) 。它比DP或者MC有什么优势呢?
首先,它比DP的优势是非常明显的,因为它不要求知道environment的概率模型,即 。其次,和MC相比,MC需要等一个episode完成后才能更新,而TD则可以在每个时刻更新,更适合于一些episode非常耗时或者可能没有结束状态的任务。一个可能的疑问是,在估计的基础上估计是否能收敛?书本中不加证明地给出了肯定的结论。既然TD和MC都能收敛,那么谁更快呢?书本中,这仍是一个未解之谜,但它提到,在实践中,通常TD比MC收敛得快。在书本的上一节和本节,一个例子可以用来说明这一点。
这是一个生活中的例子,小明从办公室下班开车回家,估计到家的时间。不同的事件会影响小明的估计,如下表。一开始,小明觉得30分钟可以到家,但由于下雨了,他延长了回家的预测时间;高速很顺利,小明又缩短了预测时间;等等。
| 状态或事件 | 已耗时间 | 预测剩下的时间 | 预测到家时间 |
|---|---|---|---|
| 离开办公室 | 0 | 30 | 30 |
| 开始开车,下雨了 | 5 | 35 | 40 |
| 驶离高速 | 20 | 15 | 35 |
| 二级公路被一辆大车挡道了 | 10 | 30 | 40 |
| 到了家门前的路 | 40 | 3 | 43 |
| 到家 | 43 | 0 | 43 |
按照MC的思路,最终确定的答案是43分钟,每一次预测都应该基于43分钟;但TD的思路是,每次都遇到了不同的情况,它只能根据当前临近的事件进行调整。这两种思路可以由下图表现。
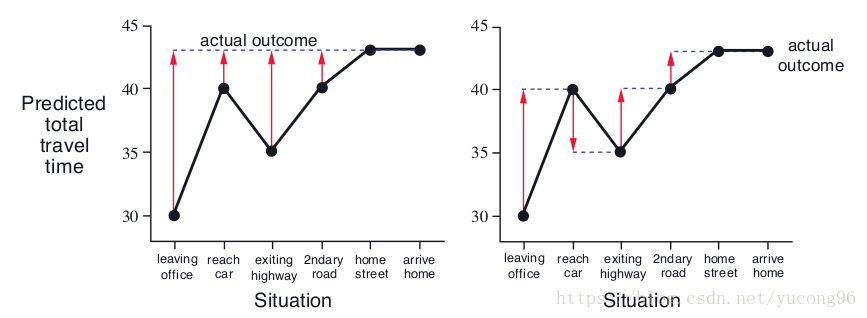
在这个例子中,似乎TD比MC更加有道理。但从中也能看到MC和TD的不同,它们在不同的场景中会有不同的收敛速度。
TD(0)的最优性
如果只存在有限的数量不多的experience,那么一个通常的做法是反复使用这些experience进行学习,直到结果收敛。我们不再在episode中间更新值函数,而是把它们的增量存下来,等这一批experience都执行完后再统一加上增量。这样的方法叫做批更新 (Batch Updating) 。在批更新下,如果步长 足够小,那么TD(0)可以收敛到一个确定的策略,常数 MC也能收敛到一个确定的策略,但这两个收敛的策略却是不同的。
同样用一个例子来说明这一点。比如我们根据一组experience来预测一个马尔科夫过程的值函数,这组经验为

对于状态 ,预测值函数是容易的,因为8个 有6个得到1,2个得到0,所以 ,因为 的概率得到1和 的概率得到0。但对于状态 ,就有两种思路。MC方法认为, 被访问了一次,结果为0,所以 ;TD方法认为, 被访问了一次且进入了 ,那么 。由于MC能够在训练集上提供一个最小二乘误差,因此在训练集上MC无疑是更好的,但我们认为整个模型是基于Markov的,因此对于未来的数据,我们倾向于TD的结果。
更一般的意义上,MC是在训练集上求解了最小二乘误差,而TD是基于Markov模型,求解了极大似然 (Maximum Likelihood) 。如果我们对模型一无所知,那么MC没有任何问题;但如果我们已知是一个Markov模型,基于这一确定性的模型无疑将提升收敛速度和收敛准确度。这被称为确定性等价估计 (Certainty-Equivalence Estimate) 。
对于非批更新的TD算法,我们不能证明它是确定性等价估计,但不难理解这是一种近似。因此它往往比MC更好。
(本节许多内容没有证明,只能宏观上理解)
Sarsa:On-Policy时序差分决策
Sarsa和TD(0)原理完全一致,只是把状态值函数替换成了行为值函数,因此它的回溯图为
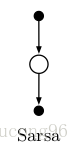
它迭代更新的表达式为:
有了行为值函数后,由于这是一个On-Policy方法,故在决策时应使用
-贪心算法。它的伪代码如下:

Q-Learning:Off-Policy时序差分决策
早期强化学习的一个突破是Q-Learning方法的发明。实际上,从迭代更新表达式上看,Q-Learning和Sarsa非常像:
但无疑,它是一个Off-Policy的算法,因为每次生成数据的是基于
的
-贪心,而真正决策的却是纯贪心。它的伪代码如下:

Q-Learning的回溯图如下(弧线代表取最大值):
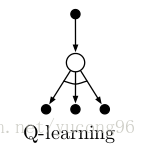
Q-Learning和Sarsa的区别其实也就是Off-Policy和On-Policy方法的区别。一个经典的例子是悬崖行走 (Cliff Walking) ,它实际上和上一章中我自己想出来的例子非常像。对于一些负奖励极大状态的临近状态,由于存在探索性,On-Policy会尽量选择远离这些负奖励(如Sarsa会选择远离悬崖的安全路线);但Off-Policy就能够很有信心地无视负奖励极大状态,只专注于最佳策略(如Q-Learning会选择悬崖边上的最近路线)。这也导致了Off-Policy中的行为策略往往劣于On-Policy的策略。
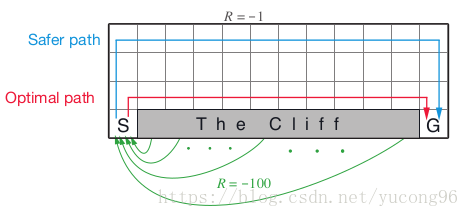
这里我的一个疑问是,为什么Q-Learning不需要重要性采样呢?我个人的观点是,采用重要性采样的根本原因是避免行为策略 做出一些非常差的行为,从而拉低了上一行为的值函数,而实际上目标策略 却根本不会考虑这样差的行为。比如在悬崖行走问题上,出于探索性, 在悬崖边上的时候时不时地会往下跳,但 由于从最优的角度出发,觉得 做了一个极其错误的行为,完全不会考虑往下跳。所以一般的MC方法用重要性采样的方法,认为 跳下来的行为对 是不可能的,因此 的这一探索完全不重要,不予考虑;而Q-Learning的方法通过比较跳和不跳的行为值函数,认为跳下来完全不值,也不予考虑。这样,Q-Learning就不需要重要性采样了。
Expected Sarsa
期望Sarsa其实只有策略评估部分,而没有策略改良部分。因此,不同的策略改良方法能够产生不同的Expected Sarsa,其中包括普通Sarsa(On-Policy)和Q-Learning(Off-Policy)。Expected Sarsa的策略评估部分表达式如下:
它的回溯图如下:

如果采用On-Policy的思路,使用 -贪心进行策略改良,那么Expected Sarsa将和普通Sarsa非常像,只是从一个确定性的 换成了期望;如果采用Off-Policy的思路,使用纯贪心进行决策,使用 -贪心生成数据,那么Expected Sarsa将和Q-Learning完全一样。当然,也可以Expected Sarsa套到其他策略改良上,比如softmax。
最大化的误差和Double Learning
目前为止所有在决策过程(策略改良)中使用了最大化的算法都面临一个很大的问题,即最大化带来的误差 (Maximization Bias) 。考虑一个如下图的例子。
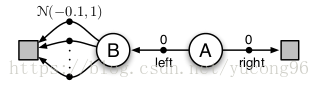
状态 有许多个行为供选择,每个行为都会终结,并得到一个符合 的奖励。状态 应该选择向右走(直接终结),还应该选择向左走(先到状态 再终结)?答案是显然的,由于状态 获得奖励的期望为负,因此状态 应该向右走。然而,按照最大化的方法,我们会尝试状态 中的每一个行为,然后选择一个最大的作为状态 的值函数。虽然每个行为得到的奖励都大概率得到负奖励,但所有行为得到的奖励都是负的概率却非常低,所以状态 的值函数大概率是一个正值。那么状态 就会做出向左走的错误决策。
如何避免Maximization Bias?一种方法是双重学习 (Double Learning) 。我们需要两组值函数,
和
。首先,
仍然按照最大化的方法估计得到,因此在上面的例子中,
。然后我们按照
贪心法选择策略
,因此
仍会向左走。以
得到的回报作为
,于是大概率就能得到
,再根据
贪心作为我们真正一轮迭代中的策略
,这时的
就会向右走了。下一轮迭代中,
和
互换,先更新
,得到
,然后再更新
和
。这一过程运用于Q-Learning的伪代码如下:

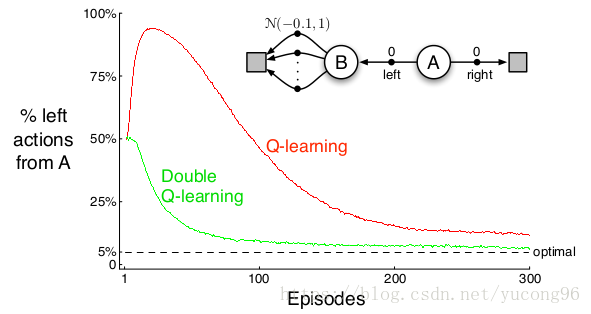
Double Learning将大大提升收敛性能,在上述例子中使用Q-Learning得到结果如下:
博弈、后状态和其他特殊情况
本节中主要提到的概念是后状态 (Afterstate) ,以及对应的后状态值函数 (Afterstate Value Function) 。以井字棋 (tic-tac-toe) 为例子,传统的状态应该是每次对方下完棋后的棋局,这样我方可以有多个选择;但由于我方即使选择完落子位置,由于接下来是对方的回合,我方也得不到下一个状态。因此,这时往往会选择我方下完棋后的棋局作为(后)状态,并以此列出后状态值函数(没太看明白)。
其他特殊情况书本也没讲。
参考文献
《Reinforcement Learning: An Introduction (second edition)》Richard S. Sutton and Andrew G. Barto
上一篇:《强化学习Sutton》读书笔记(四)——蒙特卡洛方法(Monte Carlo Methods)
下一篇:《强化学习Sutton》读书笔记(六)——n步Bootstrapping(n-step Bootstrapping)