#include<iostream>
#include<emmintrin.h>
#include<time.h>
#include<Windows.h>
using namespace std;
void interAddSimd(const unsigned char* p1, const unsigned char* p2, unsigned char* result, int num)
{
__m128i m1 = _mm_loadu_si128((__m128i*)p1);
__m128i m2 = _mm_loadu_si128((__m128i*)p2);
__m128i m3 = _mm_adds_epi8(m1, m2);
_mm_storeu_si128((__m128i*)result, m3);
}
void interAdd(const unsigned char* p1, const unsigned char* p2, unsigned char* result, int num)
{
for (int i = 0; i < num; i++)
{
result[i] = p1[i] + p2[i];
}
}
void main()
{
LARGE_INTEGER timeStart;
LARGE_INTEGER timeEnd;
LARGE_INTEGER frequency;
double quadpart;
QueryPerformanceFrequency(&frequency);
quadpart = (double)frequency.QuadPart;
unsigned char p1[16] = { 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8 };
unsigned char p2[16] = { 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9 };
unsigned char p3c[16] = { 0 };
unsigned char p3simd[16] = { 0 };
int cycNum = 1<<25;
int timeAdd_c, timeAdd_simd = 0;
// test for c
QueryPerformanceCounter(&timeStart);
for (int i = 0; i < cycNum; i++)
{
interAdd(p1, p2, p3c, 16);
}
QueryPerformanceCounter(&timeEnd);
timeAdd_c = 1000 * (timeEnd.QuadPart - timeStart.QuadPart) / quadpart; // ms
// test for sse2
QueryPerformanceCounter(&timeStart);
for (int i = 0; i < cycNum; i++)
{
interAddSimd(p1, p2, p3simd, 16);
}
QueryPerformanceCounter(&timeEnd);
timeAdd_simd = 1000 * (timeEnd.QuadPart - timeStart.QuadPart) / quadpart; // ms
for (int i = 0; i < 16; i++)
{
cout << (int)p3c[i] <<"--"<<(int)p3simd[i] << endl;
}
cout << "c time is:" << timeAdd_c << endl;
cout << "simd time is:" << timeAdd_simd << endl;
system("pause");
}结果如下:

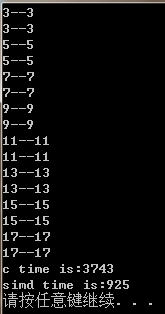
循环2^25次,release 模式下, C代码时间是144ms, SIMD 时间是28ms, simd理论上一次对16个数进行运算,应该是C版本的1/16, 但实际时间是其0.194倍,约1/5的时间,这可能是因为for循环本身的比较和加法运算的原因, 还有程序主体相对循环比较简单,当循环2^30次时, C代码时间是3743ms, SIMD时间是925ms,是C代码时间的0.25倍。