报错信息:
| 2016-06-02 23:56:26 [com.thinkive.server.logger.TradeLogger]-[ERROR] java.io.IOException: No space left on device at java.io.FileOutputStream.writeBytes(Native Method) at java.io.FileOutputStream.write(FileOutputStream.java:282) at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:202) at sun.nio.cs.StreamEncoder.implFlushBuffer(StreamEncoder.java:272) at sun.nio.cs.StreamEncoder.implFlush(StreamEncoder.java:276) at sun.nio.cs.StreamEncoder.flush(StreamEncoder.java:122) at java.io.OutputStreamWriter.flush(OutputStreamWriter.java:212) at com.thinkive.server.logger.TradeLogger$LoggerThread.flushLogFile(TradeLogger.java:404) at com.thinkive.server.logger.TradeLogger$LoggerThread.run(TradeLogger.java:322) |
服务器磁盘不足,df -h 一下,var下正常,还有剩余,发现问题没有,到后来显示大量的No space left on device:
/var明明还有很大的空间,为什么就提示“没有足够的空间”了呢?结果用到了df -i命令查看磁盘的节点发现如下图:
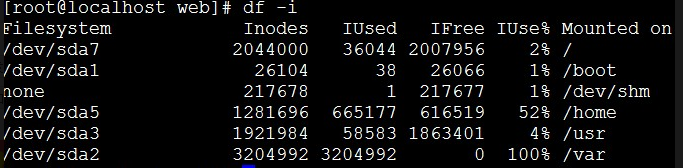
节点100%了.
这个时候用户可以先看下日志文件是否太多,如果是日志文件占用大量的inodes可以临时释放清理下过期的日志。
以下是检查inodes满的某一种情况,仅供参考:
查看原来是crontab里面定时执行的句子里没有加 > /dev/null 2>&1,系统中cron执行的程序有输出内容,输出内容会以邮件形式发给cron的用户,而sendmail没有启动所以就产生了很大零碎的文件:

cd /var/spool/clientmqueue/ 进入这个目录,删掉这些没用的文件,用ls 查看一下,结果是没有反应,文件太多,于是就用到了这个命令:ls |xargs rm -rf 可以分批的处理删除文件
操作到该步骤,可以根据较大目录的文件占用情况,临时转移部分文件到占用磁盘较小的目录中。
最近这两天登陆服务器,发现用 wget 下载文件的时候提示“No space left on device”,而且连使用 tab 键进行补全时也会提示该错误。
之前遇到过一次这种问题,是由于磁盘空间被占满了,导致无法创建新文件。正常情况下,删除一些文件来释放空间,即可解决该问题。
当我使用 df 命令查看分区情况时,结果如下:
| 1 2 3 4 5 6 7 |
|
看到这里,我以为磁盘真的被 100% 占用了,于是就查看了各目录的占用情况:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
很明显,总共的磁盘占用完全不到 10G,磁盘理论上并未被占满。
这种情况下,很可能是小文件过多,导致 inode 急剧增加,消耗完 inode 区域的空间。
如果真是如此,那么即使磁盘空间有剩余,但由于无法创建新的 inode 来存储文件的元信息,也就无法创建新文件。
因此,我用 df 命令进行验证:
| 1 2 3 4 5 6 7 |
|
可以看到,inode 区域只被占用了一小部分,还有大量的空间未使用,所以也不是 inode 区域被占满的问题。
到了这里,我的内心是非常郁闷的。这个问题直接导致了Apache、MySql以及其它的一些服务均无法启动,服务器已经基本没法使用了,然而原因却扑朔迷离。
最后,服务器提供商告诉我另一种可能的情况,就是有些文件删除时还被其它进程占用,此时文件并未真正删除,只是标记为 deleted,只有进程结束后才会将文件真正从磁盘中清除。
于是我通过 lsop 命令查看了被进程占用中的文件:
| 1 2 3 4 5 6 7 8 |
|
终于找到了罪魁祸首,原来是在后台运行的 Python 脚本,源源不断地将输出保存到 /var/log/nohup.out 文件中,文件大小居然达到了20G+!
前阶段在后台运行脚本之后,就没再管过它。估计是我在 Python 运行过程中删掉了 nothup.out 文件,由于该文件被占用,所以只能先标记为 deleted,而未真正删除,最后导致磁盘爆满。
这次的教训提醒了我,不能将任务简单放到后台就放任不管,特别是使用 nohup 命令时,所有的输出都会被不断地添加到同一个文件中,如果该进程不会自己终止,就可能导致输出文件占满整个磁盘。