一.生成模型与判别模型
1.概念介绍
参考:https://blog.csdn.net/u012101561/article/details/52814571
参考:http://www.cnblogs.com/fanyabo/p/4067295.html
监督学习的任务是学习一个模型,对给定的输入预测相应的输出,监督学习模型可分为生成模型与判别模型。
直观来说,生成模型学习的是联合概率分布P(X,Y),然后根据条件概率公式计算P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类。
判别模型估计的是条件概率分布 p(y|x),是给定观测变量x和目标变量y的条件模型。模型学习的是类别之间的最优分隔面,反映的是不同类数据之间的差异。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
举个例子
假如你的任务是识别一个语音属于哪种语言。例如对面一个人走过来,和你说了一句话,你需要识别出她说的到底是汉语、英语还是法语等。那么你可以有两种方法达到这个目的:
(1)学习每一种语言,你花了大量精力把汉语、英语和法语等都学会了。然后再有人过来对你说,你就可以知道他说的是什么语言。
(2)不去学习每一种语言,你只学习这些语言模型之间的差别,然后再分类。意思是指我学会了汉语和英语等语言的发音是有差别的,我学会这种差别就好了。
那么第一种方法就是生成方法,第二种方法是判别方法。
2.优缺点
1.判别模型
(1)优点
直接面对预测,往往学习的准确率更高
由于直接学习 P(Y|X) 或 f(X),可以对数据进行各种程度的抽象,定义特征并使用特征,以简化学习过程
(2)缺点
不能反映训练数据本身的特性
2.生成模型
(1)优点
可以还原出联合概率分布 P(X,Y),判别方法不能
学习收敛速度更快——即当样本容量增加时,学到的模型可以更快地收敛到真实模型
当存在“隐变量”时,只能使用生成模型
(2)缺点
学习和计算过程比较复杂
3.常见模型
(1)判别模型
K 近邻、感知机(神经网络)、决策树、逻辑斯蒂回归、最大熵模型、SVM、提升方法、条件随机场
(2)生成模型
朴素贝叶斯、隐马尔可夫模型、混合高斯模型、贝叶斯网络、马尔可夫随机场
二.特征选择
参考:https://www.zhihu.com/question/29316149
1.去掉变化较小的特征
即使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征
2.根据相关系数的重要性筛选
3.递归特征消除法
参考:https://www.letiantian.me/2015-04-01-recursive-feature-elimination/
递归消除特征法使用一个基模型来进行多轮训练,预测模型在原始特征上训练,每项特征指定一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。
4.L1正则
Lasso回归
5.其他学习模型类似随机森林等选出的特征重要性
6.回归模型的前进法,后退法,逐步回归法
三.处理不平衡数据
1.欠采样:当数据量足够时就该使用此方法,通过减少丰富类的大小来平衡数据集。保存所有稀有类样本,并在丰富类别中随机选择与稀有类别样本相等数量的样本,可以检索平衡的新数据集以进一步建模;
2.过采样:当数据量不足时就应该使用过采样,它尝试通过增加稀有样本的数量来平衡数据集,而不是去除丰富类别的样本的数量。
3.通过设计一个代价函数来惩罚稀有类别的错误分类。
四.异常值
1.Cook距离
2、箱线图
3.孤立森林
一种适用于连续数据的无监督异常检测方法,即不需要有标记的样本来训练,但特征需要是连续的在孤立森林中,递归地随机分割数据集,直到所有的样本点都是孤立的。在这种随机分割的策略下,异常点通常具有较短的路径。
五.缺失值填充
1.直接删除高缺失的变量
2.均值填补或者中位数填补,有的时候要根据邻近数据进行填充
3.将缺失值作为想要预测的,去预测从而实现填补
六.降维
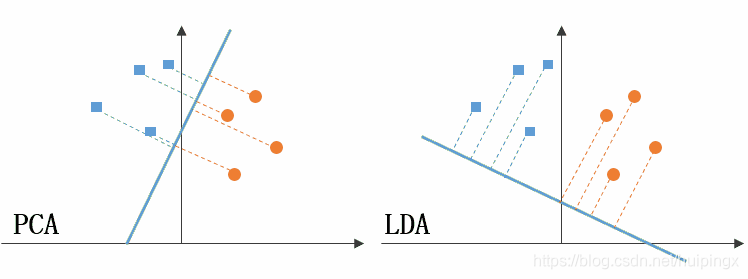
PCA:提取主成分从而描述原数据集波动的最大部分,利用贡献率来衡量
LDA:线性判别方法,降维过程中要尽可能去拉开不同标签的组的距离
七.项目一般步骤
1.数学抽象
根据数据明确任务目标,是分类、还是回归,或者是聚类。
2.数据获取
对于分类问题,数据偏斜不能过于严重(平衡),不同类别的数据数量不要有数个数量级的差距。
3.特征工程
归一化、独热、缺失值处理、异常值处理、去除共线性等
特征选择
降维
4.模型训练,调优
多参数调参方法
网格化搜索: 对于多个参数,首先根据经验确定大致的参数范围。然后选择较大的步长进行控制变量的方法进行搜索,找到最优解后;然后逐步缩小步长,使用同样的方法在更小的区间内寻找更精确的最优解
5.模型诊断误差分析
过拟合、欠拟合判断。常见的方法如交叉验证等。
误差分析也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题。
6. 模型融合/集成
7.上线运行
–未完待续