Andrew Zhang
May 7, 2016
EM算法是一个求解极大似然估计问题的迭代算法。EM算法对于给定的初始值都能够保证收敛,但不能保证全局收敛,对初始值敏感。
一、EM算法引入
如果现在有一批服从于一个高斯分布的采样样本,想根据样本推测高斯分布的均值,我们知道只需要写出似然函数进行求导即可求解,并且这个高斯分布均值的极大似然估计就是所有采样样本的均值。
现在,让问题稍微复杂点,如果这批样本采样于一个混合高斯分布,这样该怎么算呢?一个有趣的思路就是大胆运用上面所说的简单情况,对每一个高斯核计算所有样本对于这个核的加权均值,这里的权取该样本属于该核的概率,然后根据各个高斯核,更新各个样本属于每个高斯核的概率。迭代。。。直到收敛。这个想法很大胆,但是到底这样做有没有理论依据呢?这就是本文要解决的问题。
二、Jensen不等式
在
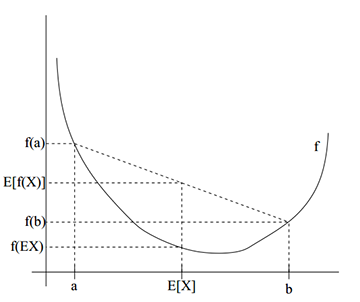
条件更严格一点,要求
上凸函数结论有此类似的性质。
三、EM算法
假设有m个相互独立的训练样本
并且往往为了计算方便一般采用公式(3-1)所示的对数形式。
公式(3-2)可以解决大多数的极大似然估计问题,但是有一些问题用公式(3-2)求解会变得特别麻烦,甚至无法求解,明显的例子就是包含隐变量的极大似然估计问题。
由于(3-3)里面含有对数函数,并且对数函数里面包含关于参数
为了利用Jensen不等式,公式(3-4)对每个
定义一个新的变量
注:其实
这样公式(3-4)说的就是对于任意的参数
由于
也即
又因为
综上可得,在当前参数
接下来,只需要利用前面确定的
四、EM算法流程
EM算法流程为:
———————————————————————————————–
Repeat until convergence
(E-step) For each i, set
(M-step) Set
———————————————————————————————–
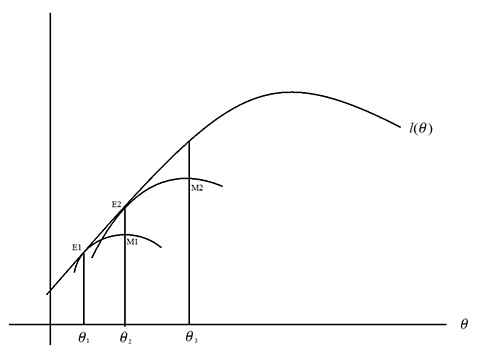
EM算法的迭代图示见下图,可见EM算法是通过对隐变量参数和模型参数之间的逐步迭代来逐步提高公式(1-2)的似然性。

注:EM算法主要分两步迭代—E-step:利用现有的模型参数
关于EM算法的另一个有助于理解迭代过程的图片如下
五、EM算法的收敛性分析
对于EM算法的迭代过程是否会收敛,由于EM每次迭代提升的是似然函数的下界
设第t次算法迭代的M-step以后
对于符号
因此只需要证明
根据第t+1步迭代的M-step显然有
其中,
由EM算法的E-step部分得到的公式(3-1)可得
综上,已证EM迭代的收敛性。
五、EM算法其它应用
利用EM迭代求解极大似然估计问题的还有很多,例如混合高斯模型,隐马尔科夫模型,混合贝叶斯模型,因子分析等。最近也看到一篇将EM应用于社交网络拓扑结构参数求解的论文。