Softmax Regression简介
处理多分类任务时,通常使用Softmax Regression模型。
在神经网络中,如果问题是分类模型(即使是CNN或者RNN),一般最后一层是Softmax Regression。
它的工作原理是将可以判定为某类的特征相加,然后将这些特征转化为判定是这一类的概率。
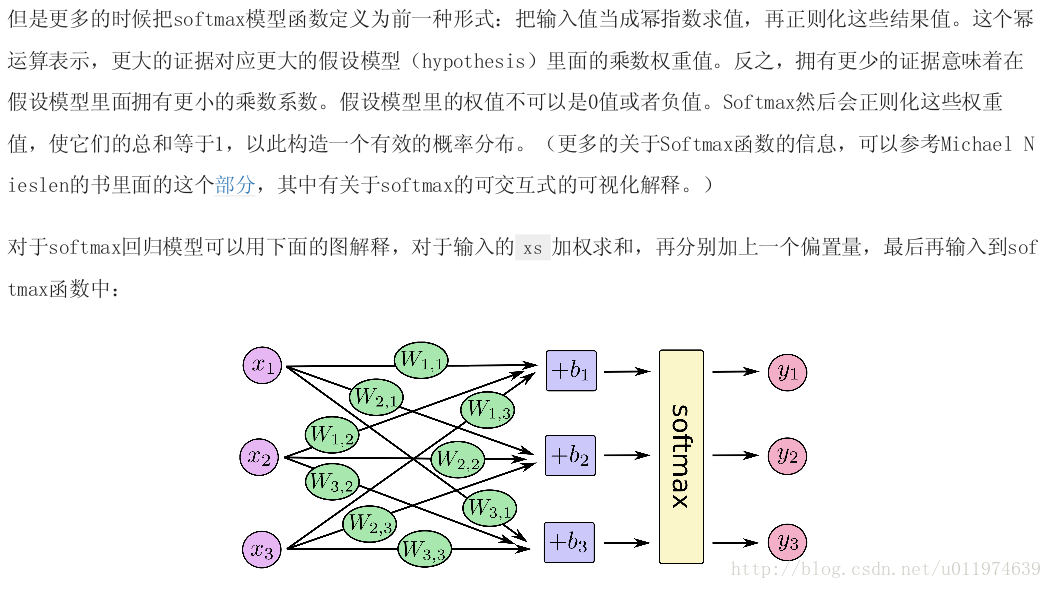
实现Softmax Regression
创建一个神经网络模型步骤如下:
- 定义网络结构(即网络前向算法)
- 定义loss function,确定Optimizer
- 迭代训练
- 在测试集/验证集上测评
1. 定义网络结构
import tensorflow as tf
sess = tf.InteractiveSession() #注册默认Session
#输入数据占位符,None代表输入条数不限制(取决训练的batch_size)
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784,10])) #权重张量,weights无隐藏层
b = tf.Variable(tf.zeros([10])) #偏置biases
#实现softmax Regression y=softmax(Wx+b)
y = tf.nn.softmax(tf.matmul(x,W) + b) 2. 定义loss function,确定Optimizer
#y_为标签值
y_ = tf.placeholder("float", [None,10])
#交叉熵损失函数定义
cross_entropy = -tf.reduce_mean(tf.reduce_sum(y_*tf.log(y)))
#学习率定义
learn_rate = 0.001
#优化器选择
train_step = tf.train.GradientDescentOptimizer(learn_rate).minimize(cross_entropy)3. 迭代训练
with Session() as sess:
#初始化所有变量
init_op = tf.global_variables_initializer()
sess.run(init_op)
#迭代次数
STEPS = 1000
for i in range(STEPS):
#使用mnist.train.next_batch随机选取batch
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})4. 在测试集/验证集上测评
#tf.argmax函数可以在一个张量里沿着某条轴的最高条目的索引值
#tf.argmax(y,1) 是模型认为每个输入最有可能对应的那些标签
#而 tf.argmax(y_,1) 代表正确的标签
#我们可以用 tf.equal 来检测我们的预测是否真实标签匹配
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
#这行代码会给我们一组布尔值。
#为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如, [True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#我们计算所学习到的模型在测试数据集上面的正确率
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})下面给出一个完整的TensorFlow训练神经网络
这里会用到激活函数去线性化,使用更深层网络,使用带指数衰减的学习率设置,同时使用正则化避免过拟合,以及使用滑动平均模型来使最终模型更加健壮。
# coding=utf-8
# 在MNIST 数据集上实现神经网络
# 包含一个隐层
# 5种优化方案:激活函数,多层隐层,指数衰减的学习率,正则化损失,滑动平均模型
import tensorflow as tf
import tensorflow.contrib.layers as tflayers
from tensorflow.examples.tutorials.mnist import input_data
#MNIST数据集相关参数
INPUT_NODE = 784 #输入节点数
OUTPUT_NODE = 10 #输出节点数
LAYER1_NODE = 500 #选择一个隐藏层,节点数为500
BATCH_SIZE = 100 #一个batch大小
'''
指数衰减学习率
函数定义exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None):
计算公式:decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
learning_rate = LEARNING_RATE_BASE;
decay_rate = LEARNING_RATE_DECAY
global_step=TRAINING_STEPS;
decay_steps = mnist.train.num_examples/batch_size
'''
LEARNING_RATE_BASE = 0.8 # 基础的学习率,使用指数衰减设置学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的初始衰减率
# 正则化损失的系数
LAMADA = 0.0001
# 训练轮数
TRAINING_STEPS = 30000
# 滑动平均衰减率
MOVING_AVERAGE_DECAY = 0.99
def get_weight(shape, llamada):
'''
function:生成权重变量,并加入L2正则化损失到losses集合里
:param shape: 权重张量维度
:param llamada: 正则参数
:return: 权重张量(所有权重都添加在losses集合中,简化计算loss操作)
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从截断的正态分布中输出随机值
生成的值服从具有指定平均值和标准偏差的正态分布,如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。
:shape: 一维的张量,也是输出的张量
:mean: 正态分布的均值。
:stddev: 正态分布的标准差。
:dtype: 输出的类型。
:seed: 一个整数,当设置之后,每次生成的随机数都一样。
:name: 操作的名字。
'''
weights = tf.Variable(tf.truncated_normal(shape, stddev=0.1))
if llamada != None:
tf.add_to_collection('losses', tflayers.l2_regularizer(llamada)(weights))
return weights
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
'''
对神经网络进行前向计算,如果avg_class为空计算普通的前向传播,否则计算包含滑动平均的前向传播
使用了RELU激活函数实现了去线性化
:param input_tensor: 输入张量
:param avg_class: 平均滑动类
:param weights1: 一级层权重
:param biases1: 一级层偏置
:param weights2: 二级层权重
:param biases2: 二级层权重
:return: 前向传播的计算结果(默认隐藏层一层,所以输出层没有ReLU)
计算输出层的前向传播结果。
因为在计算损失函数的时候会一并计算softmax函数,因此这里不加入softmax函数
同时,这里不加入softmax层不会影响最后的结果。
因为,预测时使用的是不同类别对应节点输出值的相对大小,因此有无softmax层对最后的结果没有影响。
'''
if avg_class == None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
else:
# 首先需要使用avg_class.average函数计算变量的滑动平均值,然后再计算相应的神经网络前向传播结果
layer1 = tf.nn.relu(
tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 训练模型的过程
def train(mnist):
'''
训练函数过程:
1.定义网络结构,计算前向传播结果
2.定义loss和优化器
3.迭代训练
4.评估训练模型
:param mnist: 数据集合
:return:
'''
x = tf.placeholder(tf.float32, shape=(None, INPUT_NODE), name='x_input')
y_ = tf.placeholder(tf.float32, shape=(None, OUTPUT_NODE), name='y_input')
# 生成隐藏层(使用get_weight带L2正则化)
weights1 = get_weight([INPUT_NODE, LAYER1_NODE], LAMADA)
biaes1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成输出层的参数
weights2 = get_weight([LAYER1_NODE, OUTPUT_NODE], LAMADA)
biaes2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 计算神经网络的前向传播结果,注意滑动平均的类函数为None
y = inference(x, None, weights1, biaes1, weights2, biaes2)
# 定义存储模型训练轮数的变量,并指明为不可训练的参数
global_step = tf.Variable(0, trainable=False)
'''
使用平均滑动模型
1.初始化滑动平均的函数类,加入训练轮数的变量可以加快需年早期变量的更新速度
2.对神经网络里所有可训练参数(列表)应用滑动平均模型,每次进行这个操作,列表里的元素都会得到更新
3.计算使用了滑动平均的网络前向传播结果,滑动是维护影子变量来记录其滑动平均值,需要使用时要明确调用average函数
'''
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
average_y = inference(x, variable_averages, weights1, biaes1, weights2, biaes2)
'''
定义loss
当只有一个标准答案的时候,使用sprase_softmax_cross_entropy_with_logits计算损失,可以加速计算
参数:不包含softma层的前向传播结果,训练数据的正确答案
因为标准答案是一个长度为10的一维数组,而该函数需要提供一个正确答案的数字
因此需要使用tf.argmax函数得到正确答案的对应类别编号
'''
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
# 计算在当前batch里所有样例的交叉熵平均值,并加入损失集合
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.add_to_collection('losses', cross_entropy_mean)
# get_collection返回一个列表,列表是所有这个集合的所有元素(在本例中,元素代表了其他部分的损失,加起来就得到了所有的损失)
loss = tf.add_n(tf.get_collection('losses'))
'''
设置指数衰减的学习率
使用GradientDescentOptimizer()优化算法的损失函数
'''
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, # 基础的学习率,在此基础上进行递减
global_step, # 迭代的轮数
mnist.train.num_examples / BATCH_SIZE, # 所有的数据得到训练所需要的轮数
LEARNING_RATE_DECAY) # 学习率衰减速度
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
'''
在训练神经网络模型的时候,每过一次数据既需要BP更新参数又要更新参数的滑动平均值。
为了一次完成多种操作,tensroflow提供了两种机制:tf.control_dependencies和tf.group
下面的两行程序和:train_op = tf.group(train_step,variables_average_op)等价
tf.group(*inputs, **kwargs )
Create an op that groups multiple operations.
When this op finishes, all ops in input have finished. This op has no output.
control_dependencies(control_inputs)
Use with the with keyword to specify that all operations constructed within
the context should have control dependencies on control_inputs.
For example:
with g.control_dependencies([a, b, c]):
# `d` and `e` will only run after `a`, `b`, and `c` have executed.
d = ...
e = ...
'''
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
'''
进行验证集上的准确率计算,这时需要使用滑动平均模型
判断两个张量的每一维是否相等,如果相等就返回True,否则返回False
这个运算先将布尔型的数值转为实数型,然后计算平均值,平均值就是准确率
'''
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
# init_op = tf.global_variables_initializer() sess.run(init_op) 这种写法可视化更加清晰
tf.global_variables_initializer().run()
# 准备验证数据,一般在神经网络的训练过程中会通过验证数据来判断大致停止的条件和评判训练的效果
validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
# 准备测试数据,在实际中,这部分数据在训练时是不可见的,这个数据只是作为模型优劣的最后评价标准
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
# 迭代的训练神经网络
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print "After %d training step(s),validation accuracy using average model is %g " % (step, validate_acc)
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d training step(s) testing accuracy using average model is %g" % (step, test_acc))
#TensorFlow主程序入口
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
train(mnist)
#TensorFlow提供了一个主程序入口,tf.app.run会调用上面定义的main函数
if __name__ == '__main__':
tf.app.run()输出
After 1 training step(s), loss on training batch is 3.30849.
After 1 training step(s),validation accuracy using average model is 0.1098
After 1 training step(s) testing accuracy using average model is 0.1132
After 1001 training step(s), loss on training batch is 0.19373.
After 1001 training step(s),validation accuracy using average model is 0.9772
After 1001 training step(s) testing accuracy using average model is 0.9738
After 2001 training step(s), loss on training batch is 0.169665.
After 2001 training step(s),validation accuracy using average model is 0.9794
After 2001 training step(s) testing accuracy using average model is 0.9796
After 3001 training step(s), loss on training batch is 0.147636.
After 3001 training step(s),validation accuracy using average model is 0.9818
After 3001 training step(s) testing accuracy using average model is 0.9813
After 4001 training step(s), loss on training batch is 0.129015.
After 4001 training step(s),validation accuracy using average model is 0.9808
After 4001 training step(s) testing accuracy using average model is 0.9825
After 5001 training step(s), loss on training batch is 0.109033.
After 5001 training step(s),validation accuracy using average model is 0.982
After 5001 training step(s) testing accuracy using average model is 0.982
After 6001 training step(s), loss on training batch is 0.108935.
After 6001 training step(s),validation accuracy using average model is 0.9818
After 6001 training step(s) testing accuracy using average model is 0.982
.......
.......
.......
After 27001 training step(s), loss on training batch is 0.0393247.
After 27001 training step(s),validation accuracy using average model is 0.9828
After 27001 training step(s) testing accuracy using average model is 0.9827
After 28001 training step(s), loss on training batch is 0.0422536.
After 28001 training step(s),validation accuracy using average model is 0.984
After 28001 training step(s) testing accuracy using average model is 0.9822
After 29001 training step(s), loss on training batch is 0.0512684.
After 29001 training step(s),validation accuracy using average model is 0.9832
After 29001 training step(s) testing accuracy using average model is 0.9831
判断模型效果
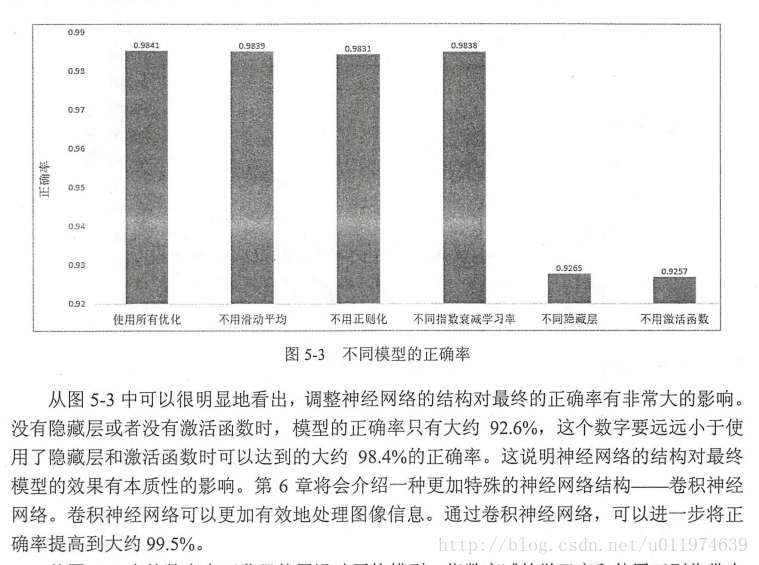
tensorflow实战