播放器内核设计
1 背景
前几年负责过搜狐影音的播放器内核,这里主要记录、总结一下。
2 主要功能
- 播放在线mp4/flv;
- 叠加字幕/弹幕。
3 模块层次结构


- PlayerEngine.dll:主要提供对外接口,并进行音视频的同步;
- PlayerCodecs.dll:主要负责音视频分离、音视频解码,也就是Demux和Decoder;
- VADSDisplay.dll:主要调用DirectSound、DirectShow的Filter实现音视频的渲染;
- flyfoxDSFilter.dll:实现了一个自定义的Source Filter,用于将视频数据推送给DirectShow渲染器;
- flyfoxLocalPlayer.dll:实现了一个由DirectShow Filter组成的本地播放器。
4 线程模型/数据流
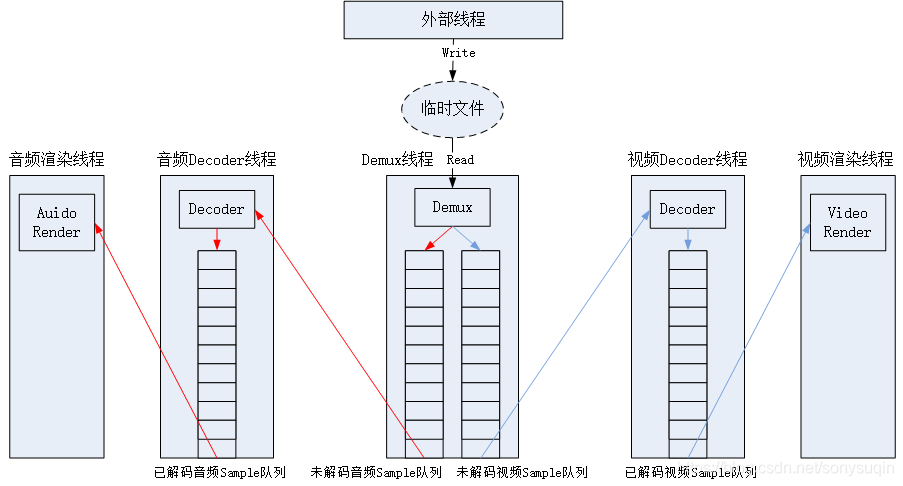
- 外部线程将视频数据写入临时文件;
- Demux线程将数据从临时文件读入,并解析成未解码的音频、视频Sample,放入各自的未解码Samle队列中;
- 音频解码线程、视频解码线程分别从未解码的音频、视频队列中获取Sample,进行解码,并放入各自的已解码Sample队列中;
- 音频渲染线程从已解码的音频Sample队列读取已经解码的PCM数据,放入DirectSound缓冲中进行播放;
- 视频渲染线程从已解码的视频Sample队列中读取已经解码的YUV图像帧,以音频当前的播放时间戳为准进行音视频同步,同步后视频数据交给视频渲染器进行渲染。
5 在线播放关键用例
5.1 Play mp4
5.1.1 单个分段
单个mp4分段是一个完整的mp4文件,为了播放一个mp4文件,需要:
- 解析mp4中的音、视频Sample;
- 解码这些音、视频Sample;
- 渲染这些音、视频Sample。
实际上播放任何一个文件都需要3个模块来分别提供这些能力: - Demux:分离器,将封装在一个文件中的音、视频Sample分离出来;
- Decoder:解码器,将未解码的音频Sample解码成PCM数据,将未解码的视频Sample解码成YUV数据,分为音频解码器和视频解码器;
- Render:渲染器,分为音频渲染和视频渲染,分别用于渲染音频、视频数据,在系统底层将这些数据送入指定的硬件,从而实现播放声音、视频的效果。

5.1.1.1 解封装
由Demux进行音、视频Sample的解析,这里启动一个Demux线程,读取文件中的音、视频Sample,分别放入待解码音、视频队列。
线程函数:flyfox_player_mov_demux_read_cb
这个线程首先要解析mp4头,只有解析完mp4头才能进行后续的音、视频Sample的读取。下面通过读取视频Sample来展示需要哪些mp4头中的信息。
在缓存数据足够的情况下,读取视频Sample的过程:
- 首先维护一个当前需要读取的视频Sample的索引,这个索引将会持续累加;
- 查询stsc box,得到视频Sample索引对应的Chunk索引,以及该Sample在Chunk内的偏移数;
- 查询stco box,得到该Chunk的偏移;
- 查询stsz,通过累加Chunk的偏移和在Chunk的各个Sample的大小,得到指定Sample的偏移以及大小;
- 从文件中的指定偏移读取指定大小的数据,得到一个视频Sample,但是该Sample在送入待解码视频Sample队列之前需要先做一些调整;
- 如果该Sample是文件第一个Sample,那么是IDR帧,需要重置解码器,传递一些解码参数。在第一个Sample前需要增加AVC Decoder Configuration Record,该信息位于moov->trak->mdia->minf->stbl->avc1->avcC中,主要包含sps、pps等数据,目的是将解码器需要的一些参数告诉解码器,否则解码器无法正常工作;
- 在Sample中包含若干个NALU,视频数据送入解码器之前需要将每个NALU前面的x个字节的NALU长度修改成分隔符“00 00 00 01”,x也是从 AVC Decoder Configuration Record中获得,一般是4,mp4中放x个字节的NALU长度是为了方便读取NALU,而解码器需要NALU之间通过“00 00 00 01”进行分隔,否则解码器无法正常解码;
- 经过上述步骤读取并处理后的Sample是一个解码器可以处理的Sample,可以放入待解码视频Sample队列。
根据上述描述可以知道,解析视频Sample需要用到的mp4 box如下:
| 序号 | Box | 字段 | 作用 |
|---|---|---|---|
| 1. | stsc | First Chunk、Sample Per Chunk | 可以从Sample索引获得Chunk索引,以及Sample在Chunk内的索引。 |
| 2. | stco | Chunk Offset | 每个Chunk的Offset。 |
| 3. | stsz | Sample Size | 每个Sample的大小。 |
| 4. | avcC | AVC Decoder Configuration Record | 获得NALU长度以及ssp、pps等解码参数。 |
对音频Sample的读取来说就比较简单,直接通过stsc、stco、stsz获取到指定的Sample的偏移、大小,然后从文件中读取Sample即可,也就是只需要实现读取视频Sample的1~5步对应的操作,然后将读到的音频Sample直接放入待解码音频Sample队列。
5.1.1.2 解码
这里使用ffmpeg进行音、视频的解码。
- 视频解码步骤
以H264解码为例:
a) 初始化:
//注册所有编解码器。
avcodec_register_all();
//初始化AVPacket,作为输入参数。
AVPacket packet; //声明AVPacket。
av_init_packet(&packet); //输入Sample将传入packet。
//创建AVFrame,作为解码输出参数。
AVFrame* pFlyfoxAVFrame = avcodec_alloc_frame();
//找到H264解码器
AVCodec *pAVCodec = avcodec_find_decoder(AV_CODEC_ID_H264);
//创建AVCodecContext
AVCodecContext* pAVCodecContext = avcodec_alloc_context3(pAVCodec);
//打开解码器
avcodec_open2(pAVCodecContext, pAVCodec,0);
b) 解码
//设置输入参数
packet.data = src;
packet.size = size;
//解码
int got_pic = false;
avcodec_decode_video2(&pAVCodecContext,pFlyfoxAVFrame,&got_pic,&packet);
c) 拷贝数据
解码出来的YUV数据存放在AVFrame结构中,Pixel Format默认为YUV420P(I420P)类型,拷贝数据用到的成员如下:
//拷贝Y分量
for(i = 0; i < pFlyfoxAVFrame->height; i++)
{
pSrc = pFlyfoxAVFrame->data[0] + i * pFlyfoxAVFrame->linesize[0];
memcpy(pDst, pSrc, pFlyfoxAVFrame->width);
pDst += pFlyfoxAVFrame->width;
}
//拷贝U分量
for(i = 0; i< pFlyfoxAVFrame ->height/2; i++) //行数减半
{
pSrc = pFlyfoxAVFrame->data[1] + i * pFlyfoxAVFrame->linesize[1];
memcpy(pDst, pSrc, pFlyfoxAVFrame->width/2);
pDst += pFlyfoxAVFrame->width/2; //列数减半
}
//拷贝V分量
for(i = 0; i < g_pFlyfoxAVFrame->height/2; i++) //行数减半
{
pSrc = pFlyfoxAVFrame->data[2] + i * pFlyfoxAVFrame->linesize[2];
memcpy(pDst, pSrc, pFlyfoxAVFrame->width/2);
pDst += pFlyfoxAVFrame->width/2; //列数减半
}
- 音频解码步骤:
音频解码过程跟视频解码基本相同,主要区别:
- 寻找的解码器是AAC的解码器;
- 在解码前,在输入的音频数据前要加一个AAC ADTS头;
- 要调用avcodec_decode_audio4解码;
- 解码后得到AV_SAMPLE_FMT_FLTP类型的数据,根据渲染器需要必须转换成AV_SAMPLE_FMT_S16类型,也就是浮点类型转换成16位整型。
其他步骤完全相同。
a) 初始化:
//注册所有编解码器。
avcodec_register_all();
//初始化AVPacket,作为输入参数。
AVPacket packet; //声明AVPacket。
av_init_packet(&packet); //输入Sample将传入packet。
//创建AVFrame,作为解码输出参数。
AVFrame* pFlyfoxAVFrame = avcodec_alloc_frame();
//找到AAC解码器
AVCodec *pAVCodec = avcodec_find_decoder(CODEC_ID_AAC);
//创建AVCodecContext
AVCodecContext* pAVCodecContext = avcodec_alloc_context3(pAVCodec);
//打开解码器
avcodec_open2(pAVCodecContext, pAVCodec,0);
b) 解码
//设置输入参数
packet.data = src;
packet.size = size;
//解码
int got_audio = false;
avcodec_decode_audio4 (&pAVCodecContext,pFlyfoxAVFrame,&got_audio,&packet);
//如果是AV_SAMPLE_FMT_FLTP类型需要转换成AV_SAMPLE_FMT_S16
SwrContext *swr = NULL;
swr = swr_alloc_set_opts(swr,AV_SAMPLE_FMT_S16);
swr_init(swr);
if (pAVCodecContext->sample_fmt == AV_SAMPLE_FMT_FLTP)
{
swr_convert(swr,dst_buffer);
}
5.1.1.3 渲染
这里采用的是DirectShow框架来播放视频,在DirectShow框架中,所有的功能被封装在各个Filter中。DirectShow中提供了一些Render Filer来渲染视频,例如evr、vmr7、vmr9等,可以充分利用显卡进行硬件加速,达到比较好的显示效果。为了将已经解码的视频数据交给Render Filer,需要建立一个Source Filer,通过管脚将Source Filer和Render Filer进行连接,类似一个管道,在Source Filer的输出管脚上PushFrame时,Render Filer将能通过输入管脚获得视频数据,交给显卡渲染播放。
flyfoxDSFilter.dll实现了一个视频的Source Filer,作为一个COM组件,其实现了COM组件的相关接口,并实现了一个IFlyfoxDirectSrc接口,用于向外部提供Source Filter的相关功能,PushFrame就是其中一个方法,用于推送视频数据。
在VADSDisplay.dll中,封装了音、视频Render Filer的相关接口,并将Render Filter与Source Filter连接,解码器在解码得到裸数据后,播放线程调用VADSDisplayer的接口,将解码后的视频数据分别送入各自的Render Filer。
注意这里没有使用DirectShow的音频DirectSound Filter,而是直接调用DirectSound的接口,这样可以不用实现音频的Source Filter,同时更灵活运用DirectSound的特性。
5.1.1.4 音视频同步
这里采用的时钟源是音频流的时钟,因为声卡基本都有自己的时钟源。
在打开文件后,从文件头中获得了音频的码率,从而得到了音频数据偏移跟音频播放时间戳的关系:音频播放时间戳=音频数据偏移/音频码率。
这个播放时间在DirectShow中称为流时间(Stream Time),是描述相对于某个参考位置(如开始播放时间)的时间差。
音频播放会调用DirectSound的接口,DirectSound维护了当前播放的音频数据缓冲的播放偏移,因此可以通过上述公式换算成音频时间戳。
视频渲染线程首先获得这个音频时间戳ta,然后检查当前准备播放的视频Sample的时间戳tv,如果ta≥tv,则该视频Sample没有提前到来,应该立刻播放,如果时间差过大,则考虑丢弃;如果ta<tv,说明还没有到该Sample的显示时间,应该等待tv-ta的时间。
5.1.2 多个分段
搜狐视频的单个剧一般由多个分段构成,每个分段一般是5分钟,在播放一个剧的多个分段的过程中需要面临的一个问题是不同分段之前的切换,如果分段切换的过程中出现卡顿,则会影响用户的观看体验,这里采用了预加载下一分段的办法来解决这个问题。

在flyfox_demux_decoder_filter中维护一个Demux demux[2]的数组,分别表示播放中的和预加载中的Demux,每个Demux将处理不同的分段文件。Decoder与Demux是解耦的,使用一个nSourceFilterIndex索引来表示当前正在使用的Demux,在需要切换的时候,关闭掉当前播放的Demux后,nSourceFilterIndex设置为正在预加载的Demux的索引,Decoder只需要从nSourceFilterIndex指定的Demux获取数据即可。
注意预加载启动的时机,如果太快启动预加载则可能会造成浪费。比如用户可能看到分段中间位置就Seek到文件的最后一个分段,而不是下一个分段。这里采取的策略是在当前分段播放到最后30秒的时候启动下一个分段的预加载,这个时候可以认为用户期望观看下一分段。
5.2 Seek MP4
5.2.1 Seek前的准备
在进行实际的mp4 seek之前有一些操作,因为seek的时间可能不在当前已经缓存的数据里面。

影音的seek是基于整剧时间的seek,由于一个剧是由多段文件组成,在进行实际的mp4文件seek前,需要将seek绝对时间换算成对应的分段i和分段内的时间偏移t,如果已经缓存了第i个分段mp4的完整数据,那么直接在这个分段内seek到时间t,否则需要下载第i个分段的数据。注意这里并不是下载整个分段的完整数据,而是下载seek到时间t后的分段mp4,对播控来说实际上是一个完整的mp4,但是并不是原始的完整分段,这样做可以减少mp4头的下载量,提高启播速度。播控需要维护这个偏移时间t,在下次seek的时候,如果定位到同一分段i的时间t1,并且t1>=t,那么可以直接在上次下载的mp4文件中seek到t1-t位置。下面需要判断数据是否足够,如果数据足够就直接在mp4文件内seek,如果不够的话,需要等待或者去请求t1开始的文件。
如果seek的时间被定位到预加载的分段里面,那么上述的时间判断可以省去,因为预加载的是完整的分段数据,这个时候只需要判断数据是否足够即可。
5.2.2 实际的seek
Seek的目标就是将时间换算成文件偏移offset,从offset开始的位置开始读取音、视频的Sample,达到修改播放时间的目的。
mp4文件内的seek跟mp4头关系紧密,需要解析mp4头中的若干box才能提供足够的信息。主要涉及的Box以及提供的信息如下:
| 序号 | Box | 字段 | 作用 |
|---|---|---|---|
| 1 | mdhd | time scale | 1秒的时间单位数,其倒数就是时间单位; |
| 2 | stts | Sample delta | 每个Sample的时间单位数,Sample的时间=Sample delta / time scale; |
| 3 | stss | Sample number | 这个表存放视频关键帧的索引,可以通过该表得到距离指定Sample最近的关键帧Sample索引。 |
| 4 | stsc | First Chunk、Sample Per Chunk | 可以从Sample索引获得Chunk索引,以及Sample在Chunk内的索引。 |
| 5 | stco | Chunk Offset | 每个Chunk的Offset |
| 6 | stsz | Sample Size | 每个Sample的大小 |
视频Seek的步骤:
- 通过视频trak->mdia->mdhd box得到Time Scale,也就是一秒有多少个时间单位;
- 查询stss box,这个box里面是一个表,每个记录包含:一个Sample包含的时间单位数,拥有相同时间单位数的Sample的个数,遍历这个表,累加访问到的每个Sample的时间,直到累积时间≥seek time,这个时候得到最接近seek time的Sample索引;
- 查询stss,这个box里面是一个表,里面有序地记录了每个关键帧的索引,通过二分查找,可以得到距离步骤2中的Sample索引最近的关键帧Sample索引,之所以寻找关键帧,是因为只有关键帧才能够独立解码,普通帧需要参考帧,仍然需要等待关键帧;
- 再次查询stss box,得到该关键帧对应的时间real seek time,也就是实际上能够seek到的时间;
- 查询stsc box,该box是一个表,里面的每个记录是一个Chunk组,组内的每个Chunk包含相同的Sample个数,每个记录包含:Chunk组的开始Chunk索引,每个Chunk的Sample数,从表开始遍历这个表,叠加Sample数,直到累加的Sample数=关键帧的Sample索引,这个时候可以得到其所处的Chunk索引以及在Chunk内的Sample偏移数;
- 查询stco,得到步骤5中的Chunk索引对应的偏移;
- 查询stsz,利用关键帧Sample索引和其在Chunk内的Sample偏移数,得到这个关键帧Sample相对于Chunk开始位置的偏移,这个偏移加上Chunk的偏移,就得到关键帧Sample的偏移。
音频Seek的步骤和视频Seek基本一样,但是比视频Seek简单,没有查找关键帧的过程,直接通过普通Sample查找其偏移即可。
5.3 Play flv
由于flv的音频、视频编码与mp4完全相同,所以复用解码的逻辑。实际上除了封装格式不同,flv播放的其他逻辑跟mp4播放基本相同(56的flv只有一个分段,比多段的mp4更好处理),因此只需要实现一个flv Demux来解析flv中的头、音频、视频数据。
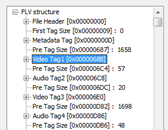
flv的解析包括解析flv头和数据tag,实际上,flv除了9个字节的没有多少信息的固定头之外,所有数据都是由tag组成。flv有3种tag,分为Metadata Tag(或者叫脚本tag)、Video Tag、Audio Tag。其前3个tag比较特殊,基本可以认为是flv头,解析了这3个头,就可以进行正常的flv播放、seek。这个3个tag分别是:
- 第1个Tag,Metadata Tag:包含了关键帧列表、视频宽高、时间长度、文件大小等;
- 第2个tag,Vidao Tag:主要包含AVC Decoder Configuration Record、视频的格式等;
- 第3个tag,Audio Tag主要包含Audio Specifig Config、音频的格式等。
后续的所有tag基本都是携带音频、视频数据的Tag,可以由前面的3个tag的信息进行解析。例如视频IDR帧需要的pps、sps来自第1个Video Tag的AVC Decoder Configuration Record,音频解码需要的一些ADTS信息来自第1个Audio Tag的Audio Specifig Config。
5.4 Seek flv
Flv的seek操作与mp4有所区别,mp4的seek基于时间,将seek的绝对时间换算成分段号和分段内的时间偏移之后,向服务器请求某个分段某个时间偏移的mp4文件。这个操作成立的前提是:CDN支持这样的接口。
但是对flv来说CDN并没有这样的接口,只有基于Http Range请求的接口,也就是基于文件偏移。因此,flv的Seek需要播放引擎先获得flv seek依赖的完整信息,最主要的是关键帧列表,注意这个关键帧列表可能位于Script Tag中,但它并不是标准。如果没有关键帧列表,那么flv的seek将会变得低效,必须按照码率计算seek时间对应的文件偏移,这个偏移并不是准确的tag偏移,只是估计tag偏移,必须下载这个位置之前的flv数据,累加tag的偏移,直达指针位置首次超过seek的估计tag偏移,并且需要继续寻找关键帧对应的tag,这个时候才能完成一次seek。
幸好,绝大多数flv都遵守这么一个规则,在Script Tag中按照时间顺序存放了关键帧列表,这个列表中,每个字段包含了关键帧的时间和偏移,这样flv的Seek就只有一个简单的二分查表的过程,比mp4的seek更简单。
Seek过程:
- 检查flv的头是否完整,如果不,则继续下载flv头;
- 如果flv头完整,则检查关键帧列表,如果没有,则返回失败;
- 二分查找flv关键帧列表,获得离目标时间最接近的关键帧位置和偏移;
- 从关键帧偏移位置开始读取tag和里面的Sample。
5.5 软字幕的实现
在Source Filter和Render Filer中间增加一个VsFilter,由VsFilter实现所有的字幕叠加操作,并向外提供相关的接口。其主要原理:VsFilter通过获取输出的文字路径点集合,转化成形状,并光栅化成Bitmap像素,然后与输入的图像进行Alpha混合,达到字幕叠加的目的,实际上是图像叠加。所有的操作都是使用CPU进行计算,所以会明显增加CPU的开销。
官方老版本的VsFilter性能较差,这里使用的是第3方优化后的XyVsFilter,与官方版本的主要区别是进行了大量的缓存,省去一些重复性的渲染以降低CPU使用率。
主要流程:
- 加载VsFilter.dll,创建VsFilter的com实例,并获取IID_IDirectVobSub接口,此时将创建文件监控线程;
- 连接Source Filter、VsFilter、Render Filter,此时将创建字幕图片生成线程;
- 调用IID_IDirectVobSub接口的put_FileName方法,设置字幕文件,VsFilter将加载该字幕文件,同时字幕图片生成线程将建立字幕图片缓存;
- Filter Graph开始工作后,CDirectVobSubFilter::Transform函数获得输入Sample以及时间戳,通过输入sample的时间戳查找SubPic缓存队列中的图片,如果查不到,则从Entry中查找并生成bitmap,然后将字幕bitmap与输入sample的surface进行叠加(alphablt),叠加完成进行适当的转换(转成YUY2),然后拷贝到输出Sample。SubPic缓存队列维持长度为10,每消耗一条,则补充一条。

5.6 缓存策略
上层的数据会写入一个临时文件,在加载完成后,该临时文件是一个完整的mp4分段文件,并在播放完成后删除。在Demux内部维护一个初始大小为2M的内存缓存,Demux从临时文件一次读64KB数据到这个缓存,每次解析mp4头、解析Sample的时候其数据源都直接来自这个内存缓存。
在播放DRM视频时,对缓存有了新的需求:
- 涉及版权安全,不能写文件;
- 单个文件可能比较大,mp4头可能会大于2M,内存缓存无法一次容纳一个mp4头;
因此在播放DRM视频时,虚拟了一个内存的文件缓存,与磁盘文件缓存提供一样的接口,用于为Demux提供数据。同时Demux的内存缓存大小可变,在缓存大小不够时进行扩展。

由于DRM mp4文件在内存中缓存,所以不能将整个mp4完全缓存在内存中,任何时刻,内存虚拟文件中只保留mp4连续的一部分数据。内存虚拟文件接收到Demux的读取请求后检查缓存内是否有指定偏移的数据,如果有则拷贝返回,如果没有则向传输层“拉”数据。每次内存虚拟文件的数据被读走,检查有效的可用数据大小如果不到一半的缓存总大小,则再次向传输层“拉”数据,期望填充满整个缓存。
5.7 VMR9和D3D的应用-全景视频播放
VMR9有3种模式:Window、Windowless、Renderless。
- Window模式:需要Render创建自己的播放窗口并设置为上层应用窗口的子窗口,为响应父窗口的消息,需要进行父窗口与子窗口的消息交互;
- Windowless模式:Render无需创建自己的播放窗口,直接在上层应用窗口上绘制,在应用窗口重绘、修改窗口时需要通知Render;
- Renderless模式:VMR不再内部渲染,需要在外部借助D3D等手段自行渲染。
在使用VMR9渲染的情况下,使用的策略是优先使用Renderless模式,如果无法使用Renderless模式,则使用Windowless模式。
在Renderless模式下,需要创建一个Presenter-Allocator,用于替代VMR9内部的渲染机制,并接受VMR9传递的图像数据,使用D3D进行渲染。

D3D对图像数据的处理流程:创建某个形状的顶点缓冲,并创建一个纹理,将图像数据拷贝到纹理上,然后将纹理贴图到顶点缓冲对应的形状,之后就是D3D内部的渲染过程。
CPlaneScene与CSphereScene的区别是CPlaneScene创建矩形顶点缓冲而CSphereScene创建球面顶点缓冲,分别对应普通视频播放和全景视频播放。
在全景视频播放时,图像一般是2:1的宽高比,可以完整覆盖在球面上,这样通过球面的扭曲可以将本身就扭曲的360°全景视频在视场内还原,另外通过响应鼠标、键盘等事件调整视点、透视矩阵,可以完整实现全景视频的播放以及旋转、拉近、拉远等交互。
6 本地播放
本地播放视频全部通过DirectShow的Filter实现。
在DirectShow内部,Filter的连接一般由GraphBuilder自动完成,称为智能连接。但是在这里自定义了类似智能连接的过程,使用策略是:先使用自定义的的连接策略,如果自定义连接策略失败则使用DirectShow的智能连接。
自定义连接流程:
- 定义一个FilterInfo.xml,描述了所有支持的Filter以及信息,初始化时将这些Filter的信息全部加载;
- 从Source Filter开始,先枚举这项Filter信息,找到所有Source Filter,检查该Filter是否支持传入的文件url和媒体类型,如果支持则设置其为使用的Source Filter并从该Source Filter开始渲染;
- 进入渲染Filter流程,不论是什么类型的Filter都走这个流程:
1) 枚举输出管脚,渲染该管脚:
1> 枚举该管脚上的所有媒体类型,渲染该媒体类型;
a) 枚举Filter Graph上的所有Filter,尝试用该媒体类型连接这些Filter;
b) 如果连接成功,则递归调用渲染Filter流程继续向下渲染该Filter。
用以上迭代+递归的办法直到连接到Render Filter,最后完成整个连接过程。一个典型的Filter连接图如下:
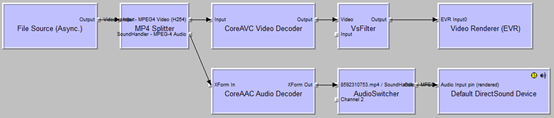
- File Source(Async.):Source Filter,实现文件的读取,属于“拉”模式;
- MP4 Splitter:Transform Filter,Demux,用于分离音、视频流;
- CoreAVC Video Decoder:Transform Filter,Decoder,用于视频解码;
- VsFilter:Transform Filter,字幕插件;
- Video Render(EVR):Render Filter,用于视频渲染;
- CoreAAC Audio Decoder,Transform Filter,Decoder,用于音频解码;
- AudioSwitcher:Transform Filter,用于切换声道;
- Default DirectSound Device:Render Filter,用于声音渲染。