因为要做KBQA,最近会看一些知识图谱相关的论文,这篇论文是network embeddings类看的第一篇,理解难免有误,望大佬指正。
原文链接:https://arxiv.org/abs/1809.05124?context=physics.soc-ph
摘要
Network Embedding 的工作就是学习得到低维度的向量来表示网络中的结点,低维度的向量包含了结点之间边的复杂信息。这些学习得到的向量可以用来结点分类,结点与结点之间的关系预测。当前的工作将结点间的关系示为二值的(即两结点间有无边),而忽略了边中丰富的语意信息。本文同时保护网络结构和结点间的丰富关系,进而学习network embedding。
引言
network embedding(网络嵌入)算法旨在学习网络结点的低维潜在表达 ,学到的embedding可用来结点分类、网络重建(network reconstrution)、链接预测(link prediction)。
在真实的social network中,结点间的social relations是非常复杂的。将Facebook看作一个线上social network,把人看做结点,因此,我们在学习network embedding时,应该获取人之间的关系,还应该获取关系类型。
相关工作
network embedding 的算法包括两种:非监督的和半监督的。
非监督的算法中的典型示例为DeepWalk,该算法主要分为两步,第一步,通过随机游走算法构建类似文本上下文的结点邻域,然后采用Skip-gram算法学习结点向量。后续一些工作遵循这种两步走的策略,在此基础上进行改进。
半监督的算法的算法采用label信息加强network embedding,这类算法通常假设每个结点都有一个相关的特征向量,输入网络中的结点部分被标记。典型算法有Planetoid、GCN、GraphSAGE。
算法
本文算法的主要思想是同事最小化结构损失(structural loss)和关系损失(relational loss),结构损失用于预测结点邻域,关系损失用于预测边的label。
所以整个算法的损失函数表示为:
其中
是结构损失,
是关系损失,
为控制两者权重的超参数。
结构损失
图的表示为
,
是所有结点的集合,
是所有边的集合。假设给定一个中心结点
,该结构损失的目标是在给定
的情况下最大化观察到其领域
的概率,目标函数为最小化以下公式:
文章采用skip-gram目标来计算
,在skip-gram模型中,每个结点
有两个不同的嵌入式向量
和
,
计算如下:
以上解决了基本的公式问题,还有一个未知的定义是领域
,最直接的方法就是采用在
与结点
相邻的结点,即与结点
有边链接的结点则作为其邻域。但是真实的网络往往是稀疏的,为了避免数据的稀疏问题,本文采用随机游走的策略,从每一个结点开始
个长度为
的随机步。在每个随机游走序列
,迭代每个
,采用窗口为
的结点作为其邻域
。
关系损失
给定
,本文通过将结点embedding进行concat表示为边的embedding,即
然后将
丢到前向神经网络中预测边的label。
假设
的ground-truth标签向量为
,
表示标签的数目,神经网络最后一层的输出为
,关系损失为:
模型优化
如以下所示

实验
数据
- ArnetMiner
- AmazonReviews
Baseline
- DeepWalk: 非监督
- LINE:
- node2vec
- GCN:半监督
超参数设置
,batchsize 都为400,embedding的维度为128, 随机游走中, 。评价指标为Macro score
对比实验结果

参数敏感度分析
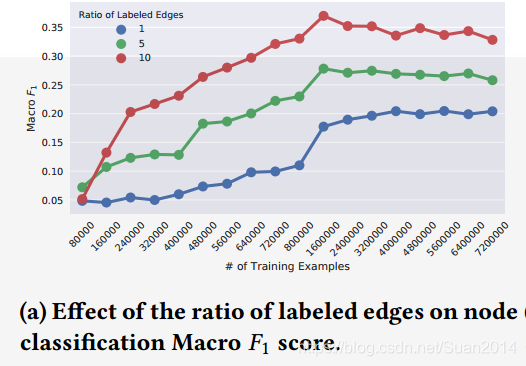
该图说明标记的边越多,Macro
score越好,说明本文算法能够利用边间丰富的语音信息。
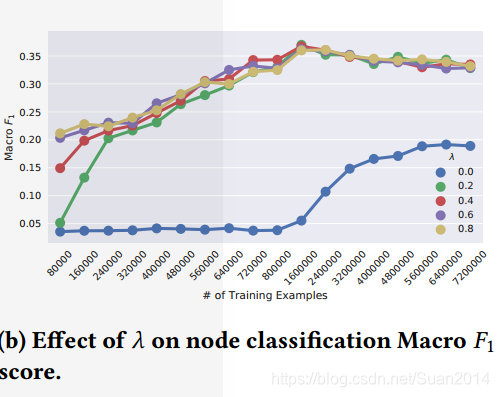
上图主要是评价
的影响,
时,性能明显上升,说明关系损失引入是必要的,另外可以看出本文算法对
不敏感。
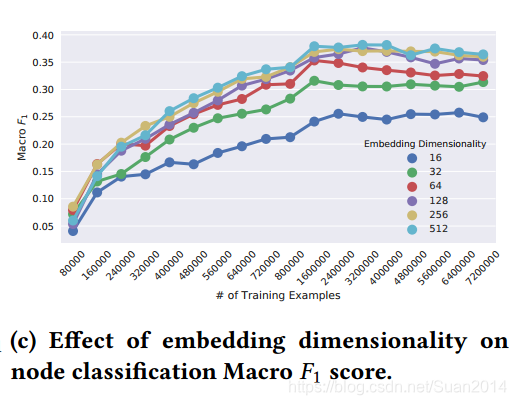
上图是分析embedding维度的影响,可以看出在维度达到128或者更高时,效果是最好的。