1. 完整的容器分类法
下面是集合类库的完整图:

Java SE5新添加了:
- Queue接口(LinkedList已经为实现该接口做了修改)及其实现PriorityQueue和各种风格的BlockingQueue。
- ConcurrentMap接口及其实现ConcurrentHashMap,用于多线程机制
- CopyOnWriteArrayList和CopyOnWriteArraySet,用于多线程机制
- EnumSet和EnumMap,为使用enum而设计的set和map的特殊实现
- 在Collections类中的多个便利方法
虚线框表示abstract类,它们只是部分实现了特定接口的工具。例如,如果要创建自己的Set,那并不用从Set接口开始并实现其中全部方法,只需从AbstractSet继承,然后执行一些创建新类必须的工作。
2. 填充容器
Collections类也有一些实用的static方法,其中包括fill,同Arrays一样只复制同一对象引用来填充整个容器的,并且只对List对象有用,但是所产生的列表可以传递给构造器或addAll方法
- Collections.addAll() 将一些元素添加到一个Collection中
- Collections.nCopies() 复制一些元素到Collections中,返回一个List集合
- Collections.fill() 复制元素填充到集合当中
3. 使用Abstract类
每个java.util容器都有其自己的Abstract类,它们提供了该容器的部分实现,因此必须做的只是去实现那些产生想要的容器所必需的方法。
享元模式:可在普通解决方案需要过多对象,或者产生普通对象太占用空间时使用享元。享元模式使得对象的一部分可以被具体化,因此,与对象中的所有事物都包含在对象内部不同,可以在更加高效的外部表中查找对象的一部分或整体。
- AbstractList 实现了List接口
- AbstractMap 实现了Map接口
- AbstractSet 实现了Set接口
4.Collection的功能方法(Collection是一个接口)
下面表格列出了可以通过Collection执行的所有操作。它们也可以是通过Set或者List执行的所有操作。

Iterator迭代器接口方法:
- hasNext(); 判断是否存在下一个对象元素
- next(); 获取下一个元素
- remove(); 移除元素
4. 可选操作
执行各种不同的添加和移除的方法在Collection接口中都是可选操作。这意味着实现类并不需要为这些方法提供功能定义。
可选操作声明调用某些方法将不会执行有意义的行为,相反,它们会抛出异常。如果一个操作是可选的,编译器仍旧会严格要求你只能调用该接口中的方法。
- UnsupportedOperationException必须是一种罕见的事件。即,对于大多数类来说,所有的操作都应该是可以工作的,只有在特例中才会有未获得支持的操作。在Java容器类库中确实如此,因为只有99%的时间里面使用的所有的容器类,如ArrayList、LinkedList、HashSet和HashMap,以及其他具体的实现,都支持所有的操作。
- 如果一个操作是为获得支持的,那么在实现接口的时候就可能会导致UnsupportedOperationException异常。
4.1 未获支持的操作
最常见的未获支持的操作,源于背后由固定尺寸的数据结构支持的容器。当使用Arrays.asList将数组转换为List时,就会得到这样的容器。还可以通过使用Collections类中不可修改的方法,选择创建任何会抛出UnsupportedOperationException的容器:
因为Arrays.asList会生成一个List,它基于一个固定大小的数组,仅支持那些不会改变数组大小的操作。任何会引起对底层数据结构的尺寸进行修改的方法都会产生一个UnsupportedOperationException异常,以表示对未获支持操作的调用。
Arrays.asList产生固定尺寸的List,而Collections.unmodifiableList产生不可修改的列表。set方法可以在二者产生的对象之间有粒度上的变化。Arrays.asList可以修改元素,没有违反尺寸固定的特性。
5. List的功能方法
List接口:
- get(int); 获取指定索引位置的列表元素
- set(int,E); 设置指定索引位置的列表元素
- add(int,E); 将指定的元素添加到此列表的索引位置。
- remove(int); 移除指定索引位置的元素;
- indexOf(Object); 从列表头部查找Object对象元素
- lastIndexOf(Objcet); 从列表尾部查找Object对象元素
- listIterator(); 返回列表迭代器
- listIterator(int); 返回指定索引位置的列表迭代器
- subList(int,int); 该方法返回的是父list一个视图,从fromIndex(包含),到toIndex(不包含)
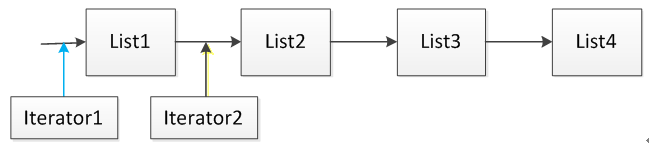
ListIterator迭代器接口方法:
- hasPrevious(); 如果以逆向遍历列表,列表迭代器前面还有元素,则返回 true,否则返回false
- previous(); 返回列表中ListIterator指向位置前面的元素
- set(E); 从列表中将next()或previous()返回的最后一个元素返回的最后一个元素更改为指定元素e
- add(E); 将指定的元素插入列表,插入位置为迭代器当前位置之前
- nextIndex(); 返回列表中ListIterator所需位置后面元素的索引
- previousIndex(); 返回列表中ListIterator所需位置前面元素的索引
basicTest包含每个list都可以执行的操作;iterMotion使用Iterator遍历元素;对应的iterManipulation使用Iterator修改元素;testVisual用以查看List的操作效果;
public class Lists {
private static boolean b;
private static String s;
private static int i;
private static Iterator<String> it;
private static ListIterator<String> lit;
public static void basicTest(List<String> a) {
a.add(1, "x"); // 在位置1添加
a.add("x"); // 在结尾添加
// 添加一个集合
a.addAll(Countries.names(25));
// 从3开始添加一个集合
a.addAll(3, Countries.names(25));
b = a.contains("1"); // 是否存在
// 整个集合都在里面吗
b = a.containsAll(Countries.names(25));
// 随机访问列表, ArrayList简单, LinkedList昂贵
s = a.get(1); // Get (typed) object at location 1
i = a.indexOf("1"); // Tell index of object
b = a.isEmpty(); // Any elements inside?
it = a.iterator(); // Ordinary Iterator
lit = a.listIterator(); // ListIterator
lit = a.listIterator(3); // Start at loc 3
i = a.lastIndexOf("1"); // Last match
a.remove(1); // Remove location 1
a.remove("3"); // Remove this object
a.set(1, "y"); // Set location 1 to "y"
a.retainAll(Countries.names(25));
a.removeAll(Countries.names(25));
i = a.size();
a.clear();
}
public static void iterMotion(List<String> a) {
ListIterator<String> it = a.listIterator();
b = it.hasNext();
b = it.hasPrevious();
s = it.next();
i = it.nextIndex();
s = it.previous();
i = it.previousIndex();
}
public static void iterManipulation(List<String> a) {
ListIterator<String> it = a.listIterator();
it.add("47");
// Must move to an element after add():
it.next();
// Remove the element after the newly produced one:
it.remove();
// Must move to an element after remove():
it.next();
// Change the element after the deleted one:
it.set("47");
}
public static void testVisual(List<String> a) {
print(a);
List<String> b = Countries.names(25);
print("b = " + b);
a.addAll(b);
a.addAll(b);
print(a);
// Insert, remove, and replace elements
// using a ListIterator:
ListIterator<String> x = a.listIterator(a.size()/2);
x.add("one");
print(a);
print(x.next());
x.remove();
print(x.next());
x.set("47");
print(a);
// Traverse the list backwards:
x = a.listIterator(a.size());
while(x.hasPrevious()) {
printnb(x.previous() + " ");
}
print();
print("testVisual finished");
}
// There are some things that only LinkedLists can do:
public static void testLinkedList() {
LinkedList<String> ll = new LinkedList<String>();
ll.addAll(Countries.names(25));
print(ll);
// Treat it like a stack, pushing:
ll.addFirst("one");
ll.addFirst("two");
print(ll);
// Like "peeking" at the top of a stack:
print(ll.getFirst());
// Like popping a stack:
print(ll.removeFirst());
print(ll.removeFirst());
// Treat it like a queue, pulling elements
// off the tail end:
print(ll.removeLast());
print(ll);
}
public static void main(String[] args) {
// Make and fill a new list each time:
basicTest(
new LinkedList<String>(Countries.names(25)));
basicTest(
new ArrayList<String>(Countries.names(25)));
iterMotion(
new LinkedList<String>(Countries.names(25)));
iterMotion(
new ArrayList<String>(Countries.names(25)));
iterManipulation(
new LinkedList<String>(Countries.names(25)));
iterManipulation(
new ArrayList<String>(Countries.names(25)));
testVisual(
new LinkedList<String>(Countries.names(25)));
testLinkedList();
}
}
6. Set和存储顺序
Set接口:继承来自Collection接口的行为
存储顺序不同的set实现不仅具有不同的行为,而且它们对于可以在特定的set中放置元素的类型也有不同的要求:

HashSet如果没有其他限制,应该默认选择,因为它对速度进行了优化。
必须为散列存储和树形储存都创建equals方法,但是hashCode只有在类被置于HashSet和LinkedHashSet时才必须。但都应该覆盖equals方法,总是同时覆盖hashCode方法。
6.1 SortedSet
SortedSet中的元素可以保证处于排序状态,SortedSet接口中的下列方法提供附加的功能:
- Comparator comparator()返回当前Set使用的Comparator;或者返回null,表示以自然方式排序。
- Object first()返回容器中的第一个元素。
- Object last()返回容器中的最末一个元素。
- SortedSet subSet(fromElement, toElement)生成此Set的子集,范围从fromElement(包含)到toElement(不包含)。
- SortedSet headSet(toElement)生成此Set的子集,由小于toElement的元素组成
- SortedSet tailSet(fromElement)生成此Set的子集,由大于或等于fromElement的元素组成
7. Queue
Queue接口:
- boolean add(E e); 添加一个元素,添加失败时会抛出异常
- boolean offer(E e); 添加一个元素,通过返回值判断是否添加成功
- E remove(); 移除一个元素,删除失败时会抛出异常
- E poll(); 移除一个元素,返回移除的元素
- E element(); 在队列的头部查询元素,如果队列为空,抛出异常
- E peek(); 在队列的头部查询元素,如果队列为空,返回null
Queue在Java SE5中仅有的两个实现是LinkedList和PriorityQueue,它们的差异在于排序行为而不是性能
7.1 优先级队列
列表中的每个对象都包含一个字符串和一个主要的以及次要的优先级值,该列表的排序顺序也是通过实现Comparable而进行控制的:
Queue<String> queue=new PriorityQueue<>();
7.2 双向队列
双向队列就像一个队列,但是可以在任意一段添加或移除元素。在LinkedList中包含支持双向队列的方法,但在Java标准类库中没有任何显式的用于双向队列的接口。因此,LinkedList无法去实现这样的接口,无法像前面转型到Queue那样向上转型为Deque。但是可以使用组合创建一个Deque类,并直接从LinkedList中暴露相关方法:
- queue.addFirst(); 向队列首部添加元素
- queue.addList(); 向队列尾部添加元素
- queue.getLast(); 获取队列尾部元素
- queue.getFirst(); 获取队列首部元素
- queue.removeFirst(); 移除队列首部元素
- queue.removeLast(); 移除队列尾元素
- queue.size(); 返回队列大小
8. 理解Map
Map接口:
- size(); 返回Map大小
- isEmpty(); 判断Map集合是否为空
- containsKey(); 判断Mpa集合是否包括Key键
- containsVaule(); 判断Map集合是否包括Vaule
- get(Object); 获得Map集合键为Object的Vaule
- put(K,V); 添加一个K,V键值对
- remove(Object); 移除K键值对
- putAll(Map); 添加所有元素Map集合
- clear(); 清空Map中所有集合元素
- keySet(); 返回键Key的Set集合
- values(); 返回值Vaule的Set集合
- entrySet(); 返回Map.entrySet集合
- remove(Objcet,Object); 移除K,V集合
- replace(K,V,V); 替换键值对
8.1 性能
get进行线性搜索时,执行速度会相当慢,这正是HashMap提高速度的地方。HashMap使用特殊值,称作散列码,来取代对键的缓慢搜索。散列码是相对唯一的,用以代表对象的int值,它是通过将该对象的某些信息进行转换而生成的。hashCode()是跟类Object中的方法,因此所有Java对象都能产生散列码。HashMap就是使用对象的hashCode进行快速查询的,此方法能够显著提高性能。

8.2 SortedMap接口
使用SortedMap(TreeMap的唯一实现),可确保键处于排序状态。使得它具有额外的功能,这些功能由SortedMap接口中的下列方法提供:
- Comparator comparator():返回当前Map使用的Comparator;或者返回null,表示以自然方式排序
- T firstKey返回Map中的第一个键
- T lastKey返回Map中的最末一个键
- SortedMap subMap(fromKey,toKey)生成此Map的子集,范围由fromKey(包括)到toKey(不包含)的键确定
- SortedMap headMap(toKey)生成此Map的子集,由键小于toKey的所有键值对组成
- SortedMap tailMap(fromkey)生成此Map的子集,由键大于或等于fromKey的所有键值对组成
8.3 LinkedHashMap
为了提高速度,LinkedHashMap散列化所有的元素,但在遍历键值对时,却又以元素的插入顺序返回键值对。此外,可以在构造器中设定LinkedHashMap,使之使用基于访问的最近最少使用(LRU)算法,于是没有被访问过的元素就会出现在队列的前面。对于需要定期清理元素以节省空间的程序来说,此功能是的程序很容易实现:
ublic class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer,String> linkedMap = new LinkedHashMap<Integer,String>(new CountingMapData(9));
print(linkedMap);
linkedMap = new LinkedHashMap<Integer,String>(16, 0.75f, true);
linkedMap.putAll(new CountingMapData(9));
print(linkedMap);
for(int i = 0; i < 6; i++) {
linkedMap.get(i);
}
print(linkedMap);
print(linkedMap.get(0));
print(linkedMap);
}
} /*
{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
{6=G0, 7=H0, 8=I0, 0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0}
A0
{6=G0, 7=H0, 8=I0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 0=A0}
*/
键值对是以插入顺序进行遍历的,但是,在LRU版本中,在只访问过前六个元素后,最后三个元素移到了队列前面。然后再次访问元素0时,它被移到了队列后端。
9. 散列与散列码
对于一个放入Map集合的对象,它的类必须实现hashcode和equal方法
正确的equals必须满足5个条件:
- 自反省,对任意x,x.equals(x)一定返回true
- 对称性,对任意x和y,如果x.equals(y)为true,则y.equals(x)也为true
- 传递性,对任意x,y,z,如果有x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true
- 一致性,对任意x和y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,返回结果应该保持一致
- 对任何不是null的x,x.equals(null)一定返回false
9.1 理解hashCode()
前面只是说明散列的数据结构(HashSet、HashMap、LinkedHashMap和LinkedHashSet)要正确处理键必须覆盖hashCode和equals方法。要很好的解决问题,必须了解数据结构的内部构造。
首先,散列的目的在于:想要使用一个对象来查找另一个对象。不过可以使用TreeMap或者自己实现的Map达到目的。
9.2 为速度而散列
散列的价值在于速度:散列使得查询得以快速进行。由于瓶颈位于键的查询速度,因此解决方案之一就是保持键的排序状态,然后使用Collections.binarySearch进行查询。
散列则更进一步,使用数组(存储一组元素最快的数据结构)来表示键的信息(不是键本身)。但数组不能调整容量。所以数组并不保存键本身。而是通过键对象生成一个数字,将其作为数组的下标。这个数字就是散列码。不同的键可以产生相同的下标,也就是说,可能会有冲突,因此,数组多大就不重要了,任何键总能在数组中找到它的位置。
于是查询一个值的过程首先是计算散列码,然后使用散列码查询数组。如果没有冲突,那就有了一个完美的散列函数。通常,冲突由外部链接处理:数组并不直接保存值,而是保存值的list。然后对list的值使用equals方法进行线性查询(这部分较慢)。但是如果散列函数好的话,数组的每个位置就只有较少的值。因此,不是查询整个list,而是快速地跳到数组的某个位置,只对很少的元素进行比较。这就是HashMap如此快的原因。
9.3 覆盖hashCode()
设计hashCode()时重要因素就是:无论何时,对同一个对象调用hashCode()都应该生成同样的值。此外,也不应该是hashCode()依赖于具有唯一性的对象信息,尤其是使用this的值。因为这样做无法生成一个新的键,使之与put中元素的键值对中的键相同。
String为例:程序中有多个String对象,都包含相同的字符串序列,那么这些String对象都映射到同一块内存区域。所以new String(“hello”)生成的两个实例,虽然相互独立的,但是对它们使用hashCode()应该产生相同的结果。
如何设计一个好的hashCode方法
- 给int变量result赋予一个非零值常量,例如17
- 为对象内每一个有意义的域f(即每个可以做equals()操作的域)计算出一个int散列码c:

- 合并计算得到的散列码:result = 37 * resut + c
- 返回result
- 检查hashCode()最后生成的结果,确保相同的对象有相同的散列码
public class CountedString {
private static List<String> created = new ArrayList<String>();
private String s;
private int id = 0;
public CountedString(String str) {
s = str;
created.add(s);
for(String s2 : created) {
if(s2.equals(s)) {
id++;
}
}
}
@Override
public String toString() {
return "String: " + s + " id: " + id + " hashCode(): " + hashCode();
}
@Override
public int hashCode() {
// 非常简单的方法: 返回s.hashCode() * id
int result = 17;
result = 37 * result + s.hashCode();
result = 37 * result + id;
return result;
}
@Override
public boolean equals(Object o) {
return o instanceof CountedString &&
s.equals(((CountedString)o).s) &&
id == ((CountedString)o).id;
}
public static void main(String[] args) {
Map<CountedString,Integer> map =
new HashMap<CountedString,Integer>();
CountedString[] cs = new CountedString[5];
for(int i = 0; i < cs.length; i++) {
cs[i] = new CountedString("hi");
map.put(cs[i], i);
}
print(map);
for(CountedString cstring : cs) {
print("Looking up " + cstring);
print(map.get(cstring));
}
}
} /*
{String: hi id: 4 hashCode(): 146450=3, String: hi id: 1 hashCode(): 146447=0, String: hi id: 3 hashCode(): 146449=2, String: hi id: 5 hashCode(): 146451=4, String: hi id: 2 hashCode(): 146448=1}
Looking up String: hi id: 1 hashCode(): 146447
0
Looking up String: hi id: 2 hashCode(): 146448
1
Looking up String: hi id: 3 hashCode(): 146449
2
Looking up String: hi id: 4 hashCode(): 146450
3
Looking up String: hi id: 5 hashCode(): 146451
4
*/
10.选择接口的不同实现
容器之间的区别通常归结为由什么在背后支持它们。也就是说,所使用的接口是有什么样的数据结构实现的。ArrayList底层由数组支持;而LinkedList是由双向链表实现,其中每个对象包含数据的同时还包含执行链表的前一个与后一个元素引用。因此,如果经常在表中插入或删除元素,LinkedList就比较合适;否则,应该使用速度更快的ArrayList。
Set中,HashSet是最常用的,查询速度最快;LinkedHashSet保持元素插入的次序;TreeSet基于Treemap ,生成一个总是处于排序状态的Set。
10.1对List的选择
- get和set的测试使用了随机数生成器来执行List的随机访问。在输出中,对于背后有数组支持的List和ArrayList,无论列表的大小如何变化,这些访问速度都很快。而对于LinkedList来说,访问时间对于较大的列表来说明显增加。很显然,如果你需要执行大量的随机访问,链表不是一个很好的选择。
- interadd测试使用迭代器在列表中间插入元素。对于ArrayList来说,当列表变大的时候,其开销会变得十分巨大,但是对于LinkedList来说,相对比较低廉,并且不会受着列表尺寸的变大而变大。
- insert和remove测试都使用了索引为5作为插入和删除点,而没有选择List两端的元素,LinkedList对于插入和删除操作来说十分低廉,并且不会随着列表尺寸的变大而变大。但是对于ArrayList来说,插入操作的代价特别高昂,并且随着列表尺寸的变大而变大。
总结:
最佳的做法可能是将ArrayList做为默认首选,只要需要使用额外的功能,或者当程序的性能因为经常从表中间进行插入和删除而变差的时候,才会选择LinkedList。如果使用的是固定数量的元素,那么既可以选择使用背后有数组支撑的List,也可以选择真正的数组。
CopyOnWriteArrayList是List的一个特殊实现,专门用于并发编程。
10.2 对Set的选择
HashSet的性能基本上总是比TreeSet好,特别是在添加和查询元素时。TreeSet存在的唯一原因是它可以维持元素的排序状态;所以,只有当需要一个排好序的Set时,才应该使用TreeSet。因为其内部结构支持排序,并且因为迭代是更有可能执行的操作,所以,用TreeSet迭代通常比用HashSet更快。
对于插入操作,LinkedHashSet比HashSet的代价更高,这是由维护链表所带来额外开销造成的。
10.3 对Map的选择
- 所有Map实现的插入操作都会随着Map的尺寸的变大而明显变慢。但是,查找的代价通常比插入小得多。
- Hashtable的性能大体上与HashMap相当,因为HashMap是用来替换Hashtable的,因此它们使用了相同的底层存储和查找机制。
- TreeMap通常比HashMap要慢,并且不必进行特殊排序。一旦填充了一个TreeMap,就可以调用keySet()方法来获取键的Set视图,然后调用toArray()来产生由这些键构成的数组。之后可以使用Arrays.binarySearch()在排序数组中查找对象。当然,这只有HashMap的行为不可接受的情况下才有意义。因为hashMap本身就被设计为可以快速查找键。
- LinkedHashMap在插入时比HashMap慢一点,因为它维护散列数据结构的同时还要维护链表(以保持插入顺序)。正是因为这给列表,使得其迭代速度更快。
- IdentityHashMap则具有完全不同的性能,因为它使用==而不是equals来比较元素。
HashMap的性能因子
- 容量:表中的桶位数
- 初始容量:表在创建时所拥有的桶位数,HashMap和HashSet都具有允许指定初始化容量的构造器
- 尺寸:表中当前存储的项数
- 负载因子:尺寸/容量。空表的负载因子是0,而半满表的负载因子是0.5。以此类推。负载轻的表产生冲突的可能性小,因此对于插入和查找都是最理想的。HashMap和HashSet都具有允许指定负载因子的构造器,表示当负载情况达到该负载因子的水平时,容器将自动增加其容量,实现方式是是容量大致加倍,并重新将现有对象分布到新的桶位集中(成为再散列)。
HashMap使用默认的负载因子0.75,这个因子在时间和空间代价之间到达了平衡。更高的负载因子可以降低表所需的空间,但是会增加查找代价。因为查找是我们在大多数时间里所做的操作。如果知道将要在HashMap中存储多少项,那么创建一个具有恰当大小的初始容量将可以避免自动再散列的开销。
11. Collections实用方法(Collections类中的静态方法)

11.1 List的排序和查询
List排序和查询使用的方法与对象数组所使用的相应方法有相同的名字与语法,只是用Collections的static方法代替Arrays的方法:
- Collections.srot(list) 是哪个list中的自然排序
- Collections.binarySearch(list,key) 在list集合中查找所需要的key
11.2 设定Collection或者Map为不可修改的元素
- Collections.unmodifiableCollection()
- Collections.unmodifiableList()
- Collections.unmodifiableSet()
- Collections.unmodifiableSortedSet()
- Collections.unmodifiableMap()
- Collections.unmodifiableSortedMap()
11.3 Collection或Map的同步控制
- Collections.synchronizedCollection()
- Collections.synchronizedList()
- Collections.synchronizedSet()
- Collections.synchronizedSortedSet()
- Collections.synchronizedMap()
- Collections.synchronizedSortedMap()
直接将新生成的容器传递给了适当的“同步方法”;这样做就不会有任何机会暴露出不同步的版本。
11.4 快速报错
Java容器有一种保护机制,能够防止多个进程同时修改同一容器的内容。如果在迭代遍历某个容器的过程中,另一个进程介入其中,并且插入、删除或修改此容器内的某个对象,那就会出问题。Java容器类类库采用快速报错(fail-fast)机制。它会探查容器上的任何除了进程所进行的操作以外的所有变化,一旦它发现其他进程修改了容器,就会立刻抛出ConcurrentModificationException异常。这就是快速报错的意思——不是使用复杂的算法在事后来检查问题。
public class FailFast {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
Iterator<String> it = c.iterator();
c.add("An object");
try {
String s = it.next();
} catch (ConcurrentModificationException e) {
System.out.println(e);
}
}
} /*
java.util.ConcurrentModificationException
*/
程序运行时发生了异常,因为在容器取得迭代器之后,有东西被放入该容器中。当程序的不同部分修改了同一容器时,就可能导致容器的状态不一致。所以,此异常提醒你,应该修改代码。
ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArraySet都使用了可以避免ConcurrentModificationException的技术。
12. 持有引用
ava.lang.ref类库包含了一组类,这些类为垃圾回收提供了更大的灵活性。当存在可能会耗尽内存的大对象时,这些类显得特别有用。有三个继承自抽象类Reference的类:SoftReference、WeakReference和PhantomReference。当垃圾回收器正在考察的对象只能通过某个Reference对象才可获得时,上诉这些不同的派生类为垃圾回收器提供了不同级别的间接性指示。
对象是可获得的(reachable),是指此对象可在程序中的某处找到,这意味着在栈中有一个普通引用,它指向此对象。如果一个对象是可获得的,垃圾回收器就不能释放它,因为它仍然为程序所用。如果一个对象不是可获得的,那程序将无法使用它,所以将其回收是安全的。
SoftReference、WeakReference和PhantomReference由强到弱排列,对应不同级别“可获得性”。
- SoftReference用以实现内存敏感的高速缓存。
- WeakReference是为实现规范映射而设计,它不妨碍垃圾回收器回收映射的键或值。规范映射中对象的实例可以在程序的多出被同时使用,以节省存储空间。
- PhantomReference用以调度回收前的清理工作,它比Java终止机制更灵活。
12.1 WeakHashMap
WeakHashMap用来保存WeakReference。它使得规范映射更易于使用,在这种映射中,每个值只保存一份实例以节省存储空间。当程序需要那个值的时候,便在映射中查询现有的对象,然后使用它。映射可将值做为其初始化的一部分,不过通常在需要的时候才生成值。
这是一种节约存储空间的技术,因为WeakHashMap允许垃圾回收器自动清理键和值,所以十分便。对于WeakHashMap添加键和值的操作,则没有什么特殊要求,映射会自动使用WeakReference包装他们。
13 Java 1.0/1.1 的容器
13.1 Vector和Enumeration
在Java 1.0/1.1 中,Vector是唯一可以自我扩展的序列,它实现类List接口。基本可以看做ArrayList,但是具有又长又难的方法名。在订正过Java容器类类库中,Vector被改造过,可将其归类为Collection和List。
public class Enumerations {
public static void main(String[] args) {
Vector<String> v =
new Vector<String>(Countries.names(10));
Enumeration<String> e = v.elements();
while (e.hasMoreElements()) {
System.out.print(e.nextElement() + ", ");
}
// Produce an Enumeration from a Collection:
e = Collections.enumeration(new ArrayList<String>());
}
} /*
ALGERIA, ANGOLA, BENIN, BOTSWANA, BULGARIA, BURKINA FASO, BURUNDI, CAMEROON, CAPE VERDE, CENTRAL AFRICAN REPUBLIC,
*/
13.2 Hashtable
Hashtable实现Map接口
HashTable是线程安全的,在实现线程安全的方式是在修改整个数据之前锁住整个HashTable
13.3 Stack
Java1.0/1.1的Stack是继承Vector。所以他拥有Vector的所有特点和行为,再加上一些额外的Stack行为。
一个简单的Stack实例,将enum中的每个String表示压入Stack,还展示了可以如何方便地将LinkedList或者之前创建过的Stack类用作栈:
enum Month {
JANUARY, FEBRUARY, MARCH, APRIL, MAY, JUNE,
JULY, AUGUST, SEPTEMBER, OCTOBER, NOVEMBER
}
public class Stacks {
public static void main(String[] args) {
Stack<String> stack = new Stack<String>();
for (Month m : Month.values()) {
stack.push(m.toString());
}
print("stack = " + stack);
// Treating a stack as a Vector:
stack.addElement("The last line");
print("element 5 = " + stack.elementAt(5));
print("popping elements:");
while (!stack.empty()) {
printnb(stack.pop() + " ");
}
print();
// Using a LinkedList as a Stack:
LinkedList<String> lstack = new LinkedList<String>();
for (Month m : Month.values()) {
lstack.addFirst(m.toString());
}
print("lstack = " + lstack);
while (!lstack.isEmpty()) {
printnb(lstack.removeFirst() + " ");
}
print();
// Using the Stack class from
// the Holding Your Objects Chapter:
net.mindview.util.Stack<String> stack2 =
new net.mindview.util.Stack<String>();
for (Month m : Month.values()) {
stack2.push(m.toString());
}
print("stack2 = " + stack2);
while (!stack2.empty()) {
printnb(stack2.pop() + " ");
}
}
} /*
stack = [JANUARY, FEBRUARY, MARCH, APRIL, MAY, JUNE, JULY, AUGUST, SEPTEMBER, OCTOBER, NOVEMBER]
element 5 = JUNE
popping elements:
The last line NOVEMBER OCTOBER SEPTEMBER AUGUST JULY JUNE MAY APRIL MARCH FEBRUARY JANUARY
lstack = [NOVEMBER, OCTOBER, SEPTEMBER, AUGUST, JULY, JUNE, MAY, APRIL, MARCH, FEBRUARY, JANUARY]
NOVEMBER OCTOBER SEPTEMBER AUGUST JULY JUNE MAY APRIL MARCH FEBRUARY JANUARY
stack2 = [NOVEMBER, OCTOBER, SEPTEMBER, AUGUST, JULY, JUNE, MAY, APRIL, MARCH, FEBRUARY, JANUARY]
NOVEMBER OCTOBER SEPTEMBER AUGUST JULY JUNE MAY APRIL MARCH FEBRUARY JANUARY
*/
13.4 BitSet
高效率存储大量“开/关”信息,BitSet是最好的选择。不过它的效率仅是对空间而言;如果需要搞笑的访问时间,BitSet比本地数组稍慢一点。此外,BitSet的最小容量是long:64位。如果存储的内容比较小,例如8位,那么BitSet就浪费了一些空间。因此如果空间对你很重要,最好撰写自己的类,或者直接使用数组(只有在创建包含开关信息列表的大量对象,并且促使你作出决定的依据仅仅是性能和其他度量因素时,才属于这种情况。如果你做出这个决定只是因为你认为某些对象太大了,那么你最终会产生不需要的复杂度,并会浪费大量的时间)。