霍夫曼编码 一般采用前缀编码 -- -- 对字符集进行编码时,要求字符集中任一字符的编码都不是其它字符的编码的前缀,这种编码称为前缀(编)码。
算法思想:
构造哈夫曼树非常简单,将所有的节点放到一个队列中,用一个节点替换两个频率最低的节点,新节点的频率就是这两个节点的频率之和。这样,
新节点就是两个被替换节点的父节点了。如此循环,直到队列中只剩一个节点(树根)。 其实这就是一个贪心策略,属于贪心算法的典型应用。
例子:
我们直接来看示例,如果我们需要来压缩下面的字符串:
“beep boop beer!”
首先,我们先计算出每个字符出现的次数,我们得到下面这样一张表 :
| 字符 | 次数 |
| ‘b’ | 3 |
| ‘e’ | 4 |
| ‘p’ | 2 |
| ‘ ‘ | 2 |
| ‘o’ | 2 |
| ‘r’ | 1 |
| ‘!’ | 1 |
然后,我把把这些东西放到Priority Queue中(用出现的次数据当 priority),我们可以看到,Priority Queue 是以Prioirry排序一个数组,如果Priority一样,会使用出现的次序排序:下面是我们得到的Priority Queue:

接下来就是我们的算法——把这个Priority Queue 转成二叉树。我们始终从queue的头取两个元素来构造一个二叉树(第一个元素是左结点,第二个是右结点),并把这两个元素的priority相加,并放回Priority中(再次注意,这里的Priority就是字符出现的次数),然后,我们得到下面的数据图表:

同样,我们再把前两个取出来,形成一个Priority为2+2=4的结点,然后再放回Priority Queue中 :
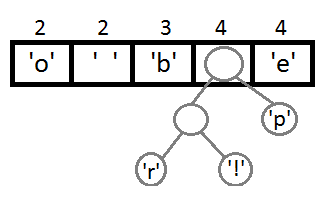
继续我们的算法(我们可以看到,这是一种自底向上的建树的过程):
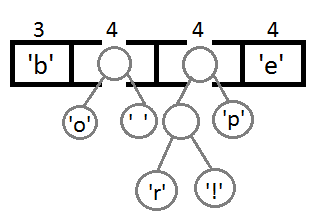
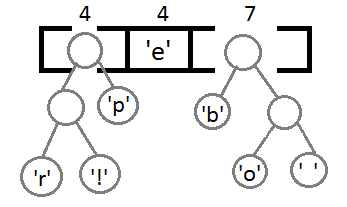
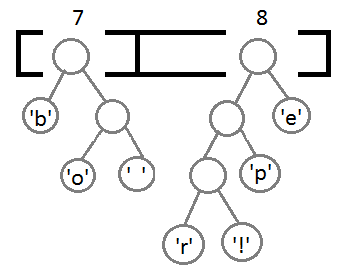
最终我们会得到下面这样一棵二叉树:
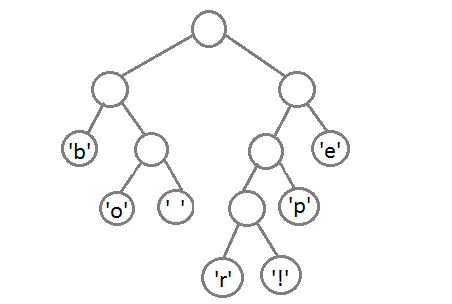
此时,我们把这个树的左支编码为0,右支编码为1,这样我们就可以遍历这棵树得到字符的编码,比如:‘b’的编码是 00,’p’的编码是101, ‘r’的编码是1000。我们可以看到出现频率越多的会越在上层,编码也越短,出现频率越少的就越在下层,编码也越长。
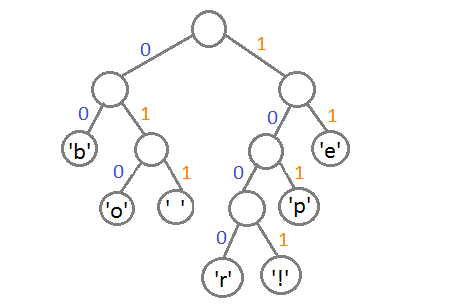
最终我们可以得到下面这张编码表:
| 字符 | 编码 |
| ‘b’ | 00 |
| ‘e’ | 11 |
| ‘p’ | 101 |
| ‘ ‘ | 011 |
| ‘o’ | 010 |
| ‘r’ | 1000 |
| ‘!’ | 1001 |
这里需要注意一点,当我们encode的时候,我们是按“bit”来encode,decode也是通过bit来完成,比如,如果我们有这样的bitset “1011110111″ 那么其解码后就是 “pepe”。所以,我们需要通过这个二叉树建立我们Huffman编码和解码的字典表。
这里需要注意的一点是,我们的Huffman对各个字符的编码是不会冲突的,也就是说,不会存在某一个编码是另一个编码的前缀,不然的话就会大问题了。因为encode后的编码是没有分隔符的。
于是,对于我们的原始字符串 beep boop beer!
其对就能的二进制为 : 0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 0001
我们的Huffman的编码为: 0011 1110 1011 0001 0010 1010 1100 1111 1000 1001
从上面的例子中,我们可以看到被压缩的比例还是很可观的。
代码
#include <iostream>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
const int M = 6; // 待编码字符个数
typedef struct Tree
{
int freq; // 出现频率,即权重
char key;
Tree *left;
Tree *right;
Tree(int fr = 0, char k = '\0', Tree *l = nullptr, Tree *r = nullptr):
freq(fr), key(k), left(l), right(r) {};
}Tree, *pTree;
struct cmp
{
bool operator() (Tree *a, Tree *b)
{
return a->freq > b->freq; // 升序排列
}
};
priority_queue<pTree, vector<pTree>, cmp> pque; // 小顶堆
// 利用中序遍历的方法输出霍夫曼编码
// 左0右1,迭代完一次st回退一个字符
void printCode(Tree *proot, string st)
{
if (proot == nullptr)
{
return;
}
if (proot->left)
{
st += '0';
}
printCode(proot->left, st);
if (!proot->left && !proot->right) // 叶子结点
{
printf("%c's code: ", proot->key);
for (size_t i = 0; i < st.size(); ++i)
{
printf("%c", st[i]);
}
printf("\n");
}
st.pop_back(); // 退回一个字符
if (proot->right)
{
st += '1';
}
printCode(proot->right, st);
}
// 清空堆上分配的内存空间
void del(Tree *proot)
{
if (proot == nullptr)
{
return;
}
del(proot->left);
del(proot->right);
delete proot;
}
// 霍夫曼编码
void huffman()
{
int i;
char c;
int fr;
/* 读入测试数据
* a 45
* b 13
* c 12
* d 16
* e 9
* f 5
*/
for (i = 0; i < M; ++i)
{
Tree *pt = new Tree;
scanf("%c%d", &c, &fr);
getchar();
pt->key = c;
pt->freq = fr;
pque.push(pt);
}
//将森林中最小的两个频度组成树,放回森林。直到森林中只有一棵树。
while (pque.size() > 1)
{
Tree *proot = new Tree;
pTree pl, pr;
pl = pque.top(); pque.pop();
pr = pque.top(); pque.pop();
proot->freq = pl->freq + pr->freq;
proot->left = pl;
proot->right = pr;
pque.push(proot);
}
string s = "";
printCode(pque.top(), s);
del(pque.top());
}
int main()
{
huffman();
return 0;
}
运行结果

对应的二叉树为:
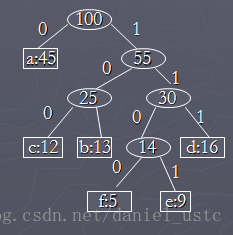
算法以freq为键值的优先队列Q用在贪心选择时有效地确定算法当前要合并的2棵具有最小频率的树。一旦2棵具有最小频率的树合并后,产生一棵新的树,
其频率为合并的2棵树的频率之和,并将新树插入优先队列Q。经过n-1次的合并后,优先队列中只剩下一棵树,即所要求的树proot。算法huffman用最
小堆实现优先队列Q。初始化优先队列需要O(n)计算时间,由于最小堆的节点删除、插入均需O(logn)时间,n-1次的合并总共需要O(nlogn)计算时间。
因此,关于n个字符的哈夫曼算法的计算时间为O(nlogn) 。
参考资料: