ForkJoin框架
目录
开始之前,请死记:
我们使用ForkJoin框架时,我们的主要业务逻辑都是:继承RecursiveTask或者RecursiveAction,业务核心逻辑fork/join叉分合并写在compute()方法内,伪码如下:
class MyTask extends RecursiveTask<T>{
public T compute(){
if (problem is small)
directly solve problem
else
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
/**如果任务体量小
* 就执行该任务
* 否则
* 叉分体量大的父任务,叉分成新的体量小的子任务
* 子任务fork提交待执行(fork提交:fork与compute的相互递归调用)
* 子任务执行结果进行join合并
* 返回合并结果给父任务
*/
/**
* 简要说明fork和compute是怎么相互递归调用的
*
* @1:fork提交新任务,新任务压入线程池管理的队列workQueue之中
* @2:新任务由线程池调度工作线程来执行,工作线程LIFO或FIFO机制来执行新任务
* @3:新任务执行时,会调用exec(){compute();}方法
* @4:我们自定义的compute(){newChildTask.fork();}方法内又会形成新任务进行fork
* @5:进行@1-->@4的递归处理,直至新任务足够体量小时不用叉分可直接执行
*/
}
}
ForkJoin简介
JAVA 1.7引入了ForkJoin框架,它是一个并发执行任务的框架。Fork/Join Pool采用优良的设计、代码实现和硬件原子操作机制等多种思路保证其执行性能。其中包括(但不限于):计算资源共享、高性能队列、避免伪共享、工作窃取机制等。Doug Lea关于ForkJoin的论文中给出了这样一段伪代码:
Result solve(Problem problem)
if (problem is small)
directly solve problem
else
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
ForkJoin的基本思想:【分而治之】当任务足够小的时候直接解决它,否则将任务分割成可以独立解决的部分,小的任务解决后再将它们合并,得到大的任务结果。看下示例图,更加清晰的理解它:


注:ForkJoin是一个单机框架,类似的分布式的框架有Hadoop这类的,它们的计算模型是MapReduce,体现了和ForkJoin一样的思想-分而治之。
ForkJoin核心类
-
ForkJoinPool :线程池,实现了ExecutorService接口和工作窃取算法,用于线程调度与管理
-
ForkJoinTask :任务,提供了fork()方法和join()方法。通常不直接使用,而是使用以下子类:
RecursiveAction :无返回值的任务,通常用于只fork不join的情形
RecursiveTask :有返回值的任务,通常用于fork+join的情形
- ForkJoinWorkerThread : 是 ForkJoinPool 内的 worker thread,被线程池调度,用于执行 ForkJoinTask
- WorkQueue : 存放ForkJoinTask的队列,有若干个队列
总体来说:ForkJoin框架有雷同线程池Executor框架的设计思路,关于Executor线程池请参考我的博客Executor线程池原理。ForkJoinPool为管家,内部管理了一堆工作线程ForkJoinWorkerThread,和若干任务队列WorkQueue(WorkQueue中存放着待执行的一堆任务ForkJoinTask)。ForkJoinTask是抽象的父类,现实中,我们的程序一般都是继承它的子类RecursiveAction(不需要任务有返回值)或者RecursiveTask(需要利用任务的返回值)即可。
接下来我们主要介绍下,ForkJoinPool线程池、RecursiveTask有返回值任务、RecursiveAction无返回值任务
搞懂了RecursiveTask,就必然一定掌握了RecursiveAction无返回值任务。
ForkJoinPool线程池
在ForkJoinPool主类的注释说明中,有这样一句话:
A static commonPool() is available and appropriate for most applications. The common pool is used by any ForkJoinTask that is not explicitly submitted to a specified pool.
Using the common pool normally reduces resource usage (its threads are slowly reclaimed during periods of non-use, and reinstated upon subsequent use).
中文翻译:ForkJoinPool类有一个静态方法commonPool(),适用于绝大多数的应用系统场景。公共池适用于任何类型的任务,只要这个任务不是必须提交给特定的池。使用commonPool通常可以帮助应用程序中多种需要进行归并计算的任务共享计算资源,从而使后者发挥最大作用(ForkJoinPools中的工作线程在闲置时会被缓慢回收,并在随后需要使用时被恢复)。
而这种获取ForkJoinPools实例的方式,才是Doug Lea推荐的使用方式 。 例如:
ForkJoinPool fjp = ForkJoinPool.commonPool(); //获得线程公共池
Future<T> result = fjp.invoke(task); //公共池内提交一个任务并等待执行结果
在JDK8当中,对ForkJoin进行了增强,可以将上面两句编写成一句代码即可:
Future<T> result = task.invoke(); //等价于上面两句代码
RecursiveTask有返回值任务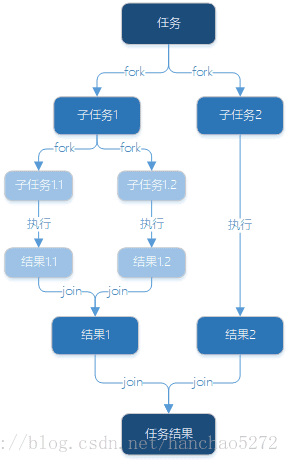
/**
* 截取的部分源码:
*
* compute()方法是核心业务逻辑,我们会在此处编写fork/join的叉分/合并递归的逻辑
*
* 之所以能递归,是因为执行任务时会调用exec(){result = compute();}方法
* 而我们在compute()方法中会编写叉分大任务为小任务,然后fork();而fork()方法的内部会
* 把新叉分的子任务提交给线程池管理的workQueue,待工作线程执行,工作线程一旦执行该子
* 任务时,又会调用exec()方法,又会执行compute()方法,于是这样就构成了递归调用。
*
*递归总结:fork()和compute()递归调用【compute()中调用fork(),fork()中又调用exec(){compute();}】
*/
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
private static final long serialVersionUID = 5232453952276485270L;
/**
* The result of the computation.
*/
V result;
/**
* The main computation performed by this task.
* @return the result of the computation
*/
protected abstract V compute();
public final V getRawResult() {
return result;
}
protected final void setRawResult(V value) {
result = value;
}
/**
* Implements execution conventions for RecursiveTask.
*/
protected final boolean exec() {
result = compute();
return true;
}
}一般我们编写代码,都是继承RecursiveTask<T>类,实现compute()方法。在compute()方法内部,编写fork/join叉分/合并逻辑。举例如下:
/**
* 以下代码的compute()方法内部的fork/join逻辑,用伪码表示:就是Doug Lea大师的论文伪码
* Result solve(Problem problem)
* if (problem is small)
* directly solve problem
* else
* split problem into independent parts
* fork new subtasks to solve each part
* join all subtasks
* compose result from subresults
*/
class Sum extends java.util.concurrent.RecursiveTask<Integer> {
private static final int THRESHOLD = 20; //叉分临界值(假定每任务体量20个元素合适)
int id;
public Sum(int id) {
this.id = id;
}
@Override
protected Integer compute() {
int allsum = 0;
int currentVolume = (end - start+1) ; //当前任务体量的大小
//无需叉分成更小任务
/**
* if (problem is small)
* directly solve problem
*/
if (currentVolume < THRESHOLD) {
int sum = getSum(start, end);
return sum;
}
//当前任务体量太大,叉分成新的左,右子任务
/**
* else
* split problem into independent parts
* fork new subtasks to solve each part
* join all subtasks
* compose result from subresults
*/
else {
int middle = (start + end) / 2;
Sum left = new Sum(seq.addAndGet(1));
Sum right = new Sum(seq.addAndGet(1));
left.fork();
right.fork();
allsum = left.join() + right.join();
}
return allsum;
}
@Override
public String toString() {
return "{id=" + id +"}";
}
private int getSum(int start, int end) {
int sum = 0;
for (int i = start; i <= end; i++) {
sum += i;
}
return sum;
}
} RecursiveAction无返回值任务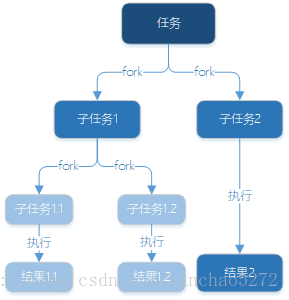
/**
* 截取的部分源码:
*
* compute()方法是核心业务逻辑,我们会在此处编写fork/join的叉分/合并递归的逻辑
*
* 之所以能递归,是因为执行任务时会调用exec(){result = compute();}方法
* 而我们在compute()方法中会编写叉分大任务为小任务,然后fork();而fork()方法的内部会
* 把新叉分的子任务提交给线程池管理的workQueue,待工作线程执行,工作线程一旦执行该子
* 任务时,又会调用exec()方法,又会执行compute()方法,于是这样就构成了递归调用。
*
*递归总结:fork()和compute()递归调用【compute()中调用fork(),fork()中又调用exec(){compute();}】
*/
public abstract class RecursiveAction extends ForkJoinTask<Void> {
private static final long serialVersionUID = 5232453952276485070L;
/**
* The main computation performed by this task.
* @return the result of the computation
*/
protected abstract void compute();
public final Void getRawResult() {
return result;
}
protected final void setRawResult(V value) {
result = value;
}
/**
* Implements execution conventions for RecursiveTask.
*/
protected final boolean exec() {
result = compute();
return true;
}
}ForkJoin原理
ForkJoin的工作原理:线程池是管家,管理着一堆工作线程,管理着若干个任务队列。当有任务提交给线程池时,线程池调度线程来执行任务。任务执行期间,有ForkJoin的基本思想穿插在里面。也就是说,如果待执行的任务体量太大,就进行fork()叉分成更小的任务,递归任务的叉分过程,直到任务被划分成足够小体量的子任务;然后子任务的执行结果在合并join()成父任务的结果,递归任务的合并过程,直到最终合并成初始的那个原始任务的结果。
结合 ForkJoinPool 的作者 Doug Lea 的论文——《A Java Fork/Join Framework》,分析讲解 Fork/Join Framework 的原理。
根据上面的示例代码,可以看出 fork() 和 join() 是 Fork/Join Framework “魔法”的关键。我们的主要业务代码逻辑都封装在compute()方法当中。可以根据函数名假设一下 fork() 和 join() 的作用:
fork():开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。join():等待该任务的处理线程处理完毕,获得返回值。
以上模型似乎可以(?)解释 ForkJoinPool 能够多线程执行的事实,但有一个很明显的问题
当任务分解得越来越细时,所需要的线程数就会越来越多,而且大部分线程处于等待状态,这样理解是正确的嘛?
如果我们在上面的示例代码加入以下代码
System.out.println(pool.getPoolSize());
这会显示当前线程池的大小,在我的机器(4核CPU)上这个值是4,也就是说只有4个工作线程。
这个矛盾可以导出,我们的假设每fork一次都新开一个线程是错误的,并不是每个 fork() 都会促成一个新线程被创建,而每个 join() 也不是一定会造成线程被阻塞。Fork/Join Framework 的算法:工作窃取算法 work stealing 。
work stealing 算法在 Doung Lea 的论文中有详细的描述,得到的相对通俗的解释:
基本思想
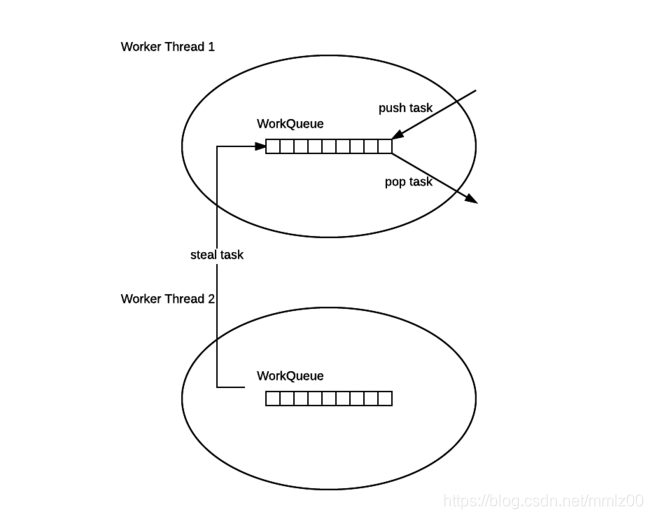
ForkJoinPool的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。- 每个工作线程在运行中产生新的任务(通常是因为调用了
fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。 - 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
- 在遇到
join()时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。 - 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
fork
fork() 做的工作只有一件事,既是把任务推入当前工作线程的工作队列里。可以参看以下的源代码:
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
join
join() 的工作则复杂得多,也是 join() 可以使得线程免于被阻塞的原因——不像同名的 Thread.join()。
- 检查调用
join()的线程是否是 ForkJoinThread 线程。如果不是(例如 main 线程),则阻塞当前线程,等待任务完成。如果是,则不阻塞。 - 查看任务的完成状态,如果已经完成,直接返回结果。
- 如果任务尚未完成,但处于自己的工作队列内,则完成它。
- 如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 FIFO 方式),执行,以期帮助它早日完成欲 join 的任务。
- 如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要 join 的任务时,则找到小偷的小偷,帮助它完成它的任务。
- 递归地执行第5步。
将上述流程画成序列图的话就是这个样子:
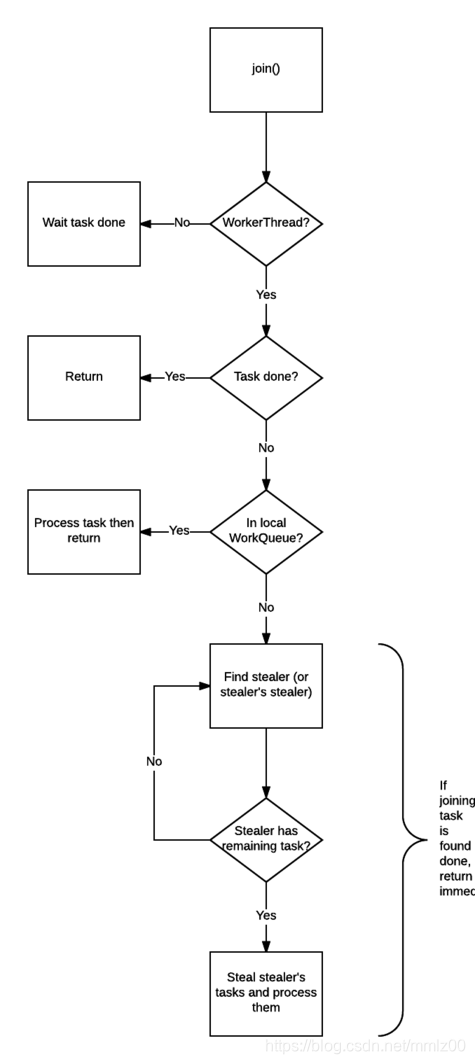
以上就是 fork() 和 join() 的原理,这可以解释 ForkJoinPool 在递归过程中的执行逻辑,但还有一个问题
最初的任务是 push 到哪个线程的工作队列里的?
这就涉及到 submit() 函数的实现方法
submit
其实除了前面介绍过的每个工作线程自己拥有的工作队列以外,ForkJoinPool 自身也拥有工作队列,这些工作队列的作用是用来接收由外部线程(非 ForkJoinThread 线程)提交过来的任务,而这些工作队列被称为 submitting queue 。
submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。
ForkJoin示例
原始for-loop求和
public class ForkJoinTaskTest {
public static void main(String[] args) throws Exception {
long beginTime,endTime;
beginTime = System.nanoTime();
int sum = 0;
for (int i = 1; i <= 100; i++)
sum += i;
System.out.println("\n\rsum is: "+sum);
endTime = System.nanoTime();
System.out.println("耗时["+(endTime-beginTime)+"]");
}
}程序运行结果:sum is: 5050 ,耗时[5909]
ForkJoinPool线程池示例
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
import java.util.concurrent.atomic.*;
public class ForkJoinTaskTest {
private static AtomicInteger seq = new AtomicInteger(0);
static class Sum extends java.util.concurrent.RecursiveTask<Integer> {
private static final int THRESHOLD = 20;
int start;
int end;
int level;
int id;
String name;
int parentId;
String parentName;
public Sum(int id, Sum parent, String name, int start, int end, int level) {
this.id = id;
this.start = start;
this.end = end;
this.level = level;
this.parentId = parent == null ? 0 : parent.id;
this.parentName = parent == null ? "noParent" : parent.name;
this.name = parentId+"_"+name;
}
@Override
protected Integer compute() {
int allsum = 0;
int currentVolume = (end - start+1) ;
if (currentVolume < THRESHOLD) {
int sum = getSum(start, end);
System.out.println("【id"+id+"】大小("+currentVolume+"),无需拆分,sum结果:"+sum);
return sum;
}
else {
int middle = (start + end) / 2;
Sum left = new Sum(seq.addAndGet(1), this, "left", start, middle, level + 1);
Sum right = new Sum(seq.addAndGet(1), this, "right", middle + 1, end, level + 1);
System.out.println("【id"+id+"大小"+currentVolume+"】大于临界点20,得拆分,左孩:" + left+",右孩:"+right);
left.fork();
right.fork();
allsum = left.join() + right.join();
System.out.println(
"【id"+id+"结果" + ",sum" + allsum+"】" +
" = " +
"【左孩(id"+left.id+")结果"+left.getRawResult()+"】"+
"+" +
"【右孩(id"+right.id+")结果"+right.getRawResult()+"】");
}
return allsum;
}
@Override
public String toString() {
return "{" +
"id=" + id +
",name='" + name + '\'' +
",level=" + level +
",pId=" + parentId +
",<" + start +
"," + end +
">}";
}
private int getSum(int start, int end) {
int sum = 0;
for (int i = start; i <= end; i++) {
sum += i;
}
return sum;
}
}
public static void main(String[] args) throws Exception {
System.out.println("临界点:task's THRESHOLD is: "+Sum.THRESHOLD+"\n\r");
long beginTime,endTime;
beginTime = System.nanoTime();
/*
* 这四句话和下面两句话是一个意思
*
ForkJoinPool fjp = ForkJoinPool.commonPool();
Sum sum= new Sum(seq.addAndGet(1), null, "root", 1, 100, 1);
Future<Integer> result = fjp.submit(sum);
System.out.println(result.get());
*/
Sum sum= new Sum(seq.addAndGet(1), null, "root", 1, 100, 1);
System.out.println(sum.invoke());
endTime = System.nanoTime();
System.out.println("耗时["+(endTime-beginTime)+"]");
}
}
程序结果如下:
临界点:task's THRESHOLD is: 20
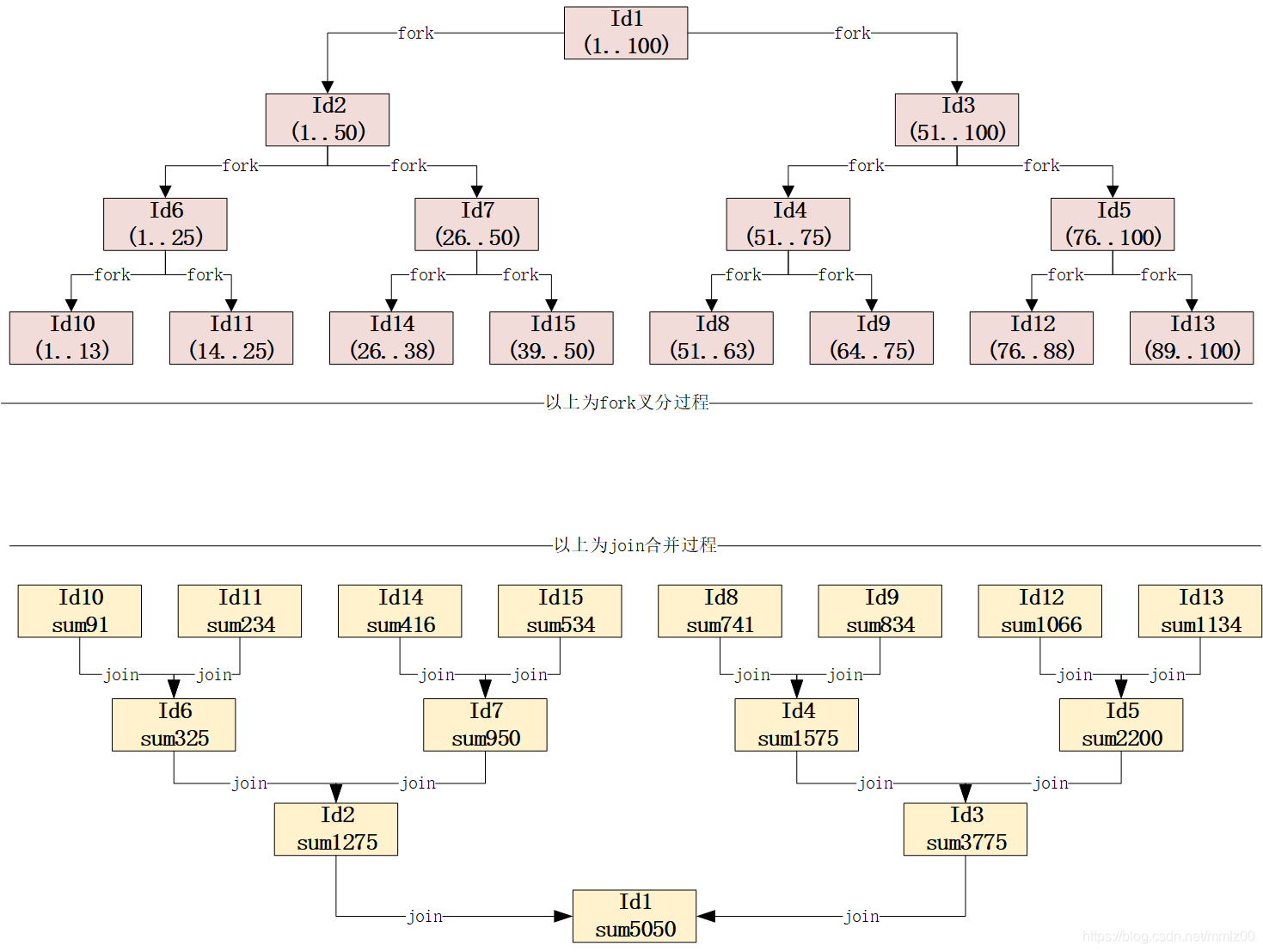
【id1大小100】大于临界点20,得拆分,左孩:{id=2,name='1_left',level=2,pId=1,<1,50>},右孩:{id=3,name='1_right',level=2,pId=1,<51,100>}
【id3大小50】大于临界点20,得拆分,左孩:{id=4,name='3_left',level=3,pId=3,<51,75>},右孩:{id=5,name='3_right',level=3,pId=3,<76,100>}
【id2大小50】大于临界点20,得拆分,左孩:{id=6,name='2_left',level=3,pId=2,<1,25>},右孩:{id=7,name='2_right',level=3,pId=2,<26,50>}
【id4大小25】大于临界点20,得拆分,左孩:{id=8,name='4_left',level=4,pId=4,<51,63>},右孩:{id=9,name='4_right',level=4,pId=4,<64,75>}
【id6大小25】大于临界点20,得拆分,左孩:{id=10,name='6_left',level=4,pId=6,<1,13>},右孩:{id=11,name='6_right',level=4,pId=6,<14,25>}
【id8】大小(13),无需拆分,sum结果:741
【id5大小25】大于临界点20,得拆分,左孩:{id=12,name='5_left',level=4,pId=5,<76,88>},右孩:{id=13,name='5_right',level=4,pId=5,<89,100>}
【id10】大小(13),无需拆分,sum结果:91
【id12】大小(13),无需拆分,sum结果:1066
【id9】大小(12),无需拆分,sum结果:834
【id13】大小(12),无需拆分,sum结果:1134
【id11】大小(12),无需拆分,sum结果:234
【id5结果,sum2200】 = 【左孩(id12)结果1066】+【右孩(id13)结果1134】
【id4结果,sum1575】 = 【左孩(id8)结果741】+【右孩(id9)结果834】
【id7大小25】大于临界点20,得拆分,左孩:{id=14,name='7_left',level=4,pId=7,<26,38>},右孩:{id=15,name='7_right',level=4,pId=7,<39,50>}
【id6结果,sum325】 = 【左孩(id10)结果91】+【右孩(id11)结果234】
【id14】大小(13),无需拆分,sum结果:416
【id3结果,sum3775】 = 【左孩(id4)结果1575】+【右孩(id5)结果2200】
【id15】大小(12),无需拆分,sum结果:534
【id7结果,sum950】 = 【左孩(id14)结果416】+【右孩(id15)结果534】
【id2结果,sum1275】 = 【左孩(id6)结果325】+【右孩(id7)结果950】
【id1结果,sum5050】 = 【左孩(id2)结果1275】+【右孩(id3)结果3775】
5050 ,耗时[15025371]
用图形表示即为:
ThreadPoolExecutor线程池示例
我们用ThreadPoolExecutor线程池技术来改造下上述代码:
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
import java.util.concurrent.atomic.*;
public class ForkJoinTaskTest {
private static AtomicInteger seq = new AtomicInteger(0);
static class Sum implements Callable<Integer> {
private static final int THRESHOLD = 20;
int start;
int end;
int id;
String name;
int parentId;
String parentName;
public Sum(int id, Sum parent, String name, int start, int end, List<Sum> ls) {
this.id = id;
this.start = start;
this.end = end;
this.parentId = parent == null ? 0 : parent.id;
this.parentName = parent == null ? "noParent" : parent.name;
this.name = parentId+"_"+name;
}
@Override
public Integer call() {
int sum = 0;
for (int i = start; i <= end; i++)
sum += i;
return sum;
}
/**
* 递归调用叉分方法
*/
public void split(List<Sum> ls) {
int currentVolume = (end - start+1) ;
if (currentVolume < THRESHOLD) {
System.out.println(".............【id"+id+"】体量"+currentVolume+",无需拆分,可作为任务.....");
ls.add(this);
}
else {
int middle = (start + end) / 2;
Sum left = new Sum(seq.addAndGet(1), this, "left", start, middle, ls);
Sum right = new Sum(seq.addAndGet(1), this, "right", middle + 1, end, ls);
System.out.println("【id"+id+"】体量"+currentVolume+">临界点20,拆分,左孩:" + left+",右孩:"+right);
left.split(ls);
right.split(ls);
}
}
public String toString() {
return "{" +
"id=" + id +
",name='" + name + '\'' +
",pId=" + parentId +
",<" + start +
"," + end +
">}";
}
}
public static void main(String[] args) throws Exception {
System.out.println("临界点:task's THRESHOLD is: "+Sum.THRESHOLD+"\n\r");
long beginTime,endTime;
beginTime = System.nanoTime();
/**
* 定义好任务,并且将任务叉分完毕
*/
List<Sum> ls = new ArrayList<>();
Sum sumTask = new Sum(seq.addAndGet(1), null, "root", 1, 100, ls);
sumTask.split(ls);
/**
* 将叉分好的所有任务都提交给线程池
*/
List<Future<Integer>> results = new ArrayList<>();
int parallism = Runtime.getRuntime().availableProcessors(); // CPU的核心数
ExecutorService es = Executors.newFixedThreadPool(parallism);
for(Sum s: ls)
results.add(es.submit(s));
/**
* 将所有任务的执行结果求和,得出最终结果
*/
int total = 0;
for (Future<Integer> f : results)
try {
total += f.get();
} catch (Exception ignore) {}
System.out.println("\n\rsum is: "+total);
endTime = System.nanoTime();
System.out.println("耗时["+(endTime-beginTime)+"]");
es.shutdown();
}
}
以上代码运行结果如下:
临界点:task's THRESHOLD is: 20
【id1】体量100>临界点20,拆分,左孩:{id=2,name='1_left',pId=1,<1,50>},右孩:{id=3,name='1_right',pId=1,<51,100>}
【id2】体量50>临界点20,拆分,左孩:{id=4,name='2_left',pId=2,<1,25>},右孩:{id=5,name='2_right',pId=2,<26,50>}
【id4】体量25>临界点20,拆分,左孩:{id=6,name='4_left',pId=4,<1,13>},右孩:{id=7,name='4_right',pId=4,<14,25>}
.............【id6】体量13,无需拆分,可作为任务.....
.............【id7】体量12,无需拆分,可作为任务.....
【id5】体量25>临界点20,拆分,左孩:{id=8,name='5_left',pId=5,<26,38>},右孩:{id=9,name='5_right',pId=5,<39,50>}
.............【id8】体量13,无需拆分,可作为任务.....
.............【id9】体量12,无需拆分,可作为任务.....
【id3】体量50>临界点20,拆分,左孩:{id=10,name='3_left',pId=3,<51,75>},右孩:{id=11,name='3_right',pId=3,<76,100>}
【id10】体量25>临界点20,拆分,左孩:{id=12,name='10_left',pId=10,<51,63>},右孩:{id=13,name='10_right',pId=10,<64,75>}
.............【id12】体量13,无需拆分,可作为任务.....
.............【id13】体量12,无需拆分,可作为任务.....
【id11】体量25>临界点20,拆分,左孩:{id=14,name='11_left',pId=11,<76,88>},右孩:{id=15,name='11_right',pId=11,<89,100>}
.............【id14】体量13,无需拆分,可作为任务.....
.............【id15】体量12,无需拆分,可作为任务.....
sum is: 5050 ,耗时[13240563]
得出的结果跟用ForkJoinPool时的执行结果是一样的。
总结:
ForkJoinPool 不是为了替代 ThreadPoolExecutor,而是它的补充,在某些应用场景下性能比 ThreadPoolExecutor 更好。
ForkJoinPool 不是一定就比传统的for-loop性能要好,这要看任务是否足够大,从以上三例可以看出,有时反而for-loop更快。
ForkJoin的同步执行
主线程调用invoke();来启动任务执行,主线程阻塞在这里,必须等待任务完成时,invoke()方法才返回。
ForkJoin的异步执行
主线程调用execute();来启动任务执行,主线程继续往下执行代码,并不在此处阻塞,此时,主线程继续执行主线程的逻辑,任务由线程池调度工作线程执行,工作线程和主线程之间是互不影响的。
ForkJoin应用场景
- ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。(见 Java Tip: When to use ForkJoinPool vs ExecutorService )
- ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等。
- ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
ForkJoinPool有一个 Async Mode ,效果是工作线程在处理本地任务时也使用 FIFO 顺序。这种模式下的ForkJoinPool更接近于是一个消息队列,而不是用来处理递归式的任务。- 在需要阻塞工作线程时,可以使用
ManagedBlocker。 - Java 1.8 新增加的
CompletableFuture类可以实现类似于 Javascript 的 promise-chain,内部就是使用ForkJoinPool来实现的。 - 为了更好的利用ForkJoin,任务一般是体量大的并且是可以递归运算的,这些运算在没有外部阻塞或同步时就能进行。
ForkJoin注意事项
ForkJoin的执行效率

这里可以看出,当运算量小时,直接for-loop运算的效率高于forkjoin。因为forkjoin会消耗着创建线程,线程切换的资源和时间。
而当运算量大时,forkjoin由于其多线程特性,更好的利用了CPU资源,而线程资源创建切换的损耗比起大量的计算时间来说也可以被忽略了。因此forkjoin的表现更为出色。
ForkJoin的守护线程
ForkJoin使用的线程是守护线程,记住这一点非常重要。因此,当主线程结束时,它们这些守护线程也会结束。所以,可能需要保持主线程活跃(比如:主线程处调用Future.get();或者join()或者invoke()等方法;让主线程阻塞在这里等待任务运行完毕),直到任务结束。
ForkJoin异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally())
{
System.out.println(task.getException());
}getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
public final Throwable getException() {
int s = status & DONE_MASK;
return ((s >= NORMAL) ? null :
(s == CANCELLED) ? new CancellationException() :
getThrowableException());
}