分词往往是自然语言处理的第一步。在分词的基础上,我们可以进行关键字的提取、搜索、纠错等应用。在理论上,分词可以采用的方法有很多,最经典的办法莫过于HMM模型、CRF及其它语言模型如Bigram、Trigram等。NLPIR(又名:ICTCLAS2015)是由中科院张华平博士研发的,基于HMM模型免费分词软件。早期的版本名为ICTCLAS+年份。由于分词的内核是由C语言写成的,因此对于Java的开发人员不是十分地方便。不过好在Java的本地接口技术可以帮助我们应付简单的开发和测试。下面就是本人用NLPIR建立的Java工程环境。经过测试,可以正常运行和分词。在这里结合C接口说明文档进行解释(该文本可以从下载的NLPIR压缩包中获得)。
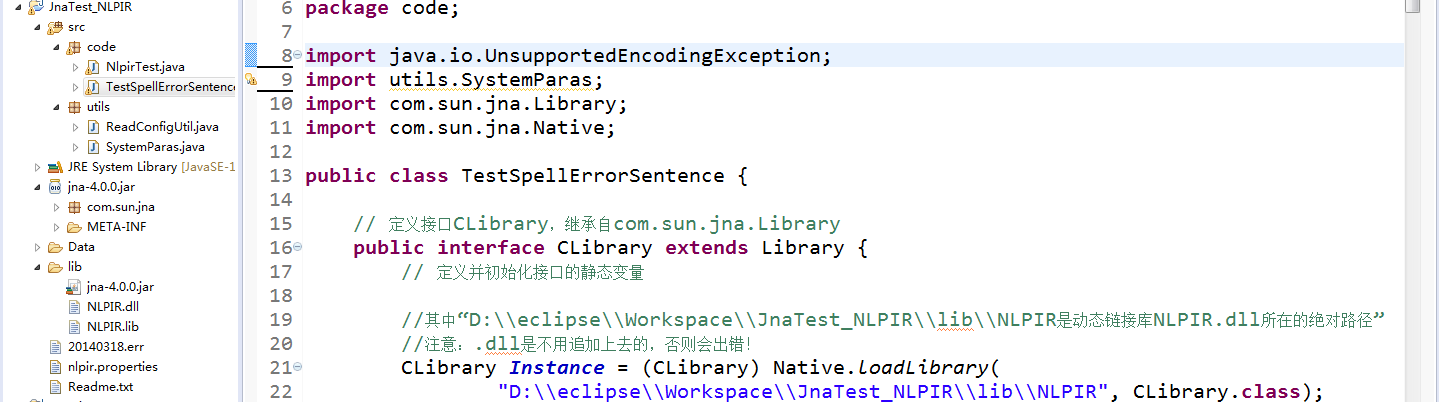
图1.工程效果图
0.初始化函数: NLPIR_Init(String sDataPath, int encoding, String sLicenceCode)
想要正确地运行NLPIR(无论在C环境还是Java环境),都必须具备两个东西:Data文件夹和动态链接库NLPIR.dll。它们均可以从下载的压缩包中获得。在图1中也可以看到。

1.对内存中的字符串进行分词:NLPIR_ParagraphProcess(String sSrc, int bPOSTagged)

2.对外存中的字符串进行分词:NLPIR_FileProcess(String sSourceFilename,String sResultFilename,int bPOStagged)

3.添加或者删除用户自己的词汇:NLPIR_AddUserWord(String sWord), NLPIR_DelUsrWord(String sWord)

在了解了上述的一些接口函数后,我们就可以对做一些基本的分词工作了。例如图2就是一个分词的简单事例。
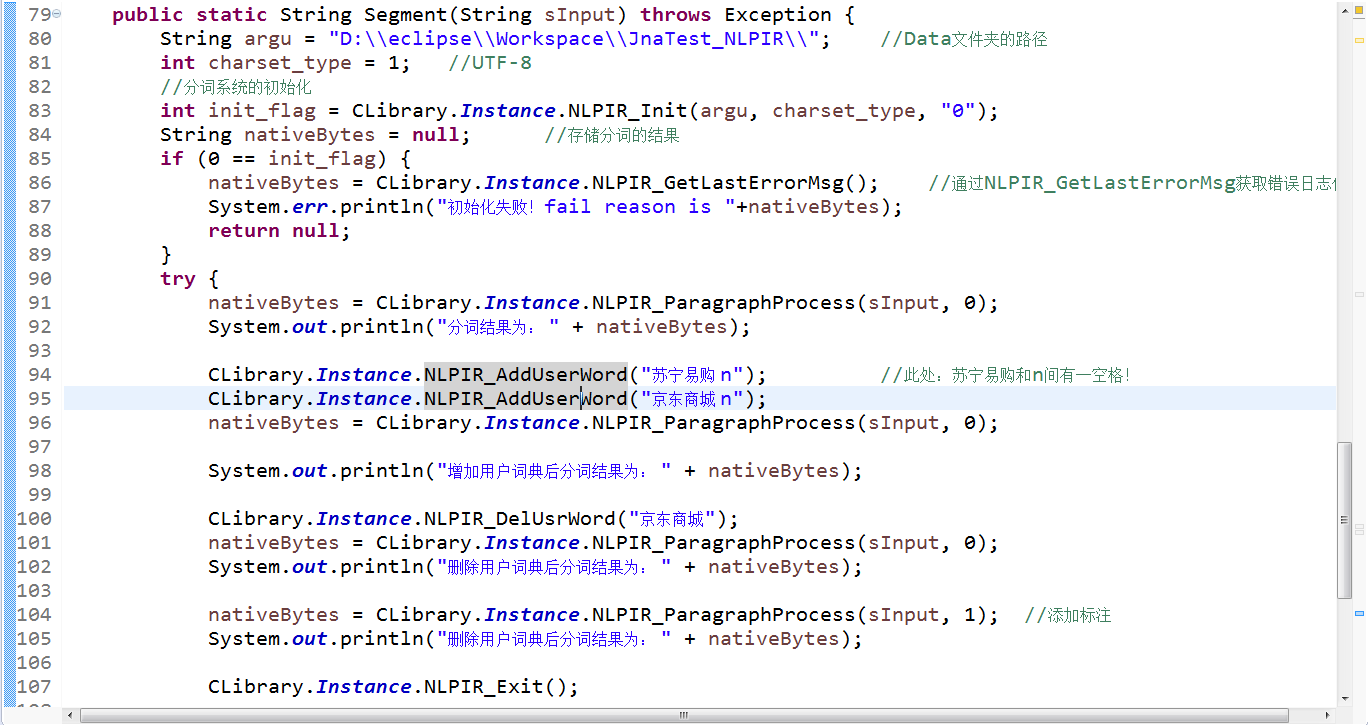
图2.分词程序的例子
分词的结果为(其中最后一个分词结果是添加了词性标注):
