Web Scraping HTML Tables with Python
https://towardsdatascience.com/web-scraping-html-tables-with-python-c9baba21059
Pokemon Database Website
Starting off, we will try scraping the online Pokemon Database (http://pokemondb.net/pokedex/all).
Inspect HTML
Before moving forward, we need to understand the structure of the website we wish to scrape. This can be done by clicking right-clicking the element we wish to scrape and then hitting “Inspect”. For our purpose, we will inspect the elements of the table, as illustrated below:
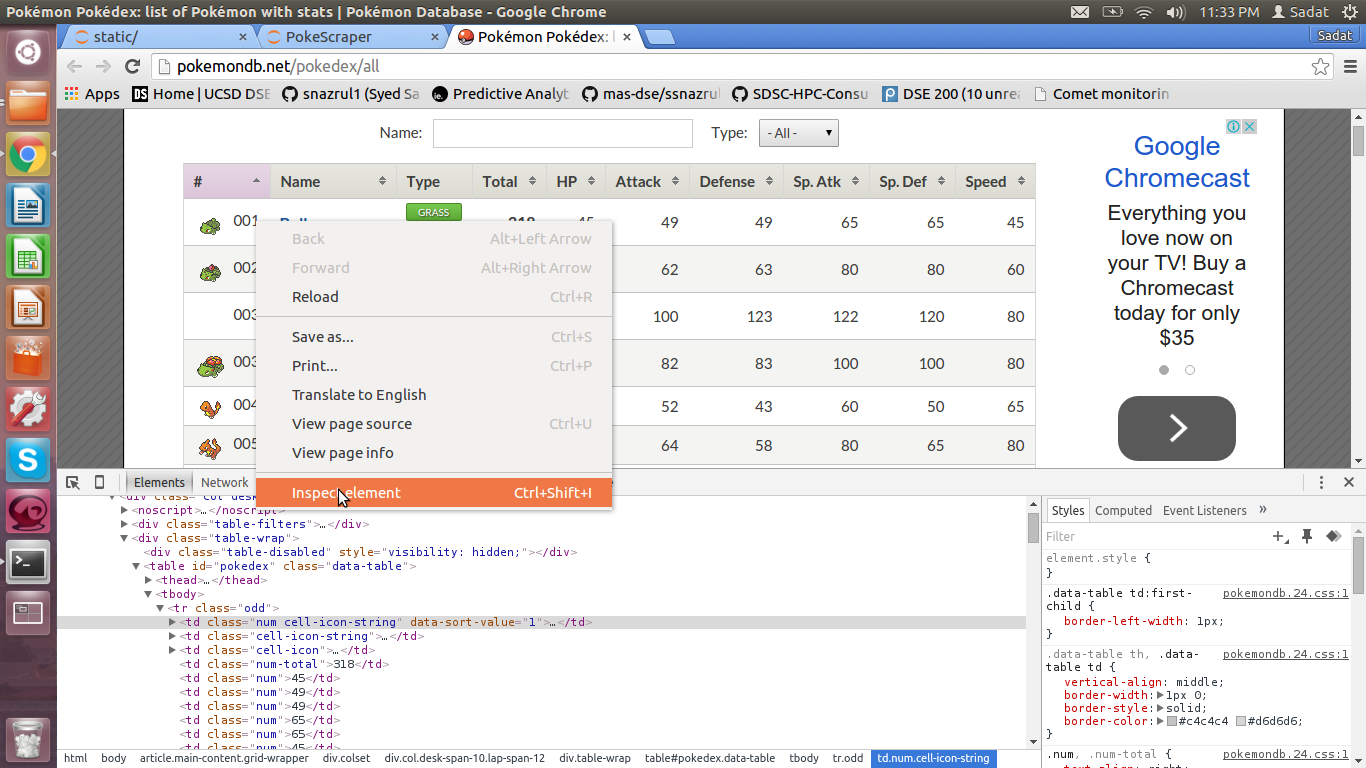
Inspecting cell of HTML Table
Based on the HTML codes, the data are stored in after <tr>..</tr>. This is the row information. Each row has a corresponding <td>..</td> or cell data information.
Import Libraries
We will need requests for getting the HTML contents of the website and lxml.html for parsing the relevant fields. Finally, we will store the data on a Pandas Dataframe.
import requests import lxml.html as lh import pandas as pd
Scrape Table Cells
The code below allows us to get the Pokemon stats data of the HTML table.
url='http://pokemondb.net/pokedex/all'
#Create a handle, page, to handle the contents of the website page = requests.get(url)
#Store the contents of the website under doc doc = lh.fromstring(page.content)
#Parse data that are stored between <tr>..</tr> of HTML
tr_elements = doc.xpath('//tr')
For sanity check, ensure that all the rows have the same width. If not, we probably got something more than just the table.
#Check the length of the first 12 rows [len(T) for T in tr_elements[:12]]
OUTPUT: [10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10]
Looks like all our rows have exactly 10 columns. This means all the data collected on tr_elements are from the table.
Parse Table Header
Next, let’s parse the first row as our header.
tr_elements = doc.xpath('//tr')
#Create empty list col=[] i=0
#For each row, store each first element (header) and an empty list
for t in tr_elements[0]:
i+=1
name=t.text_content()
print '%d:"%s"'%(i,name)
col.append((name,[]))
OUTPUT:
1:”#”
2:”Name”
3:”Type”
4:”Total”
5:”HP”
6:”Attack”
7:”Defense”
8:”Sp. Atk”
9:”Sp. Def”
10:”Speed”
Creating Pandas DataFrame
Each header is appended to a tuple along with an empty list.
#Since out first row is the header, data is stored on the second row onwards
for j in range(1,len(tr_elements)):
#T is our j'th row
T=tr_elements[j]
#If row is not of size 10, the //tr data is not from our table
if len(T)!=10:
break
#i is the index of our column
i=0
#Iterate through each element of the row
for t in T.iterchildren():
data=t.text_content()
#Check if row is empty
if i>0:
#Convert any numerical value to integers
try:
data=int(data)
except:
pass
#Append the data to the empty list of the i'th column
col[i][1].append(data)
#Increment i for the next column
i+=1
Just to be sure, let’s check the length of each column. Ideally, they should all be the same.
[len(C) for (title,C) in col]
OUTPUT: [800, 800, 800, 800, 800, 800, 800, 800, 800, 800]
Perfect! This shows that each of our 10 columns has exactly 800 values.
Now we are ready to create the DataFrame:
Dict={title:column for (title,column) in col}
df=pd.DataFrame(Dict)
Looking at the top 5 cells on the DataFrame:
df.head()
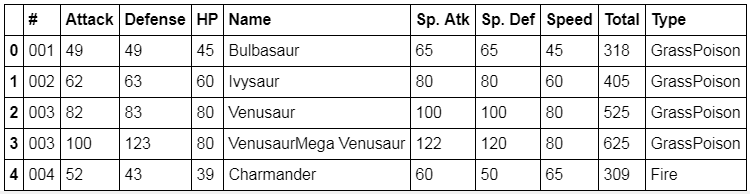
There you have it! Now you have a Pandas DataFrame with all the information needed!
Additional Information
This tutorial is a subset of a 3 part series:
The series covers:
- Scraping a Pokemon Website
- Data Analysis
- Building a GUI Pokedex