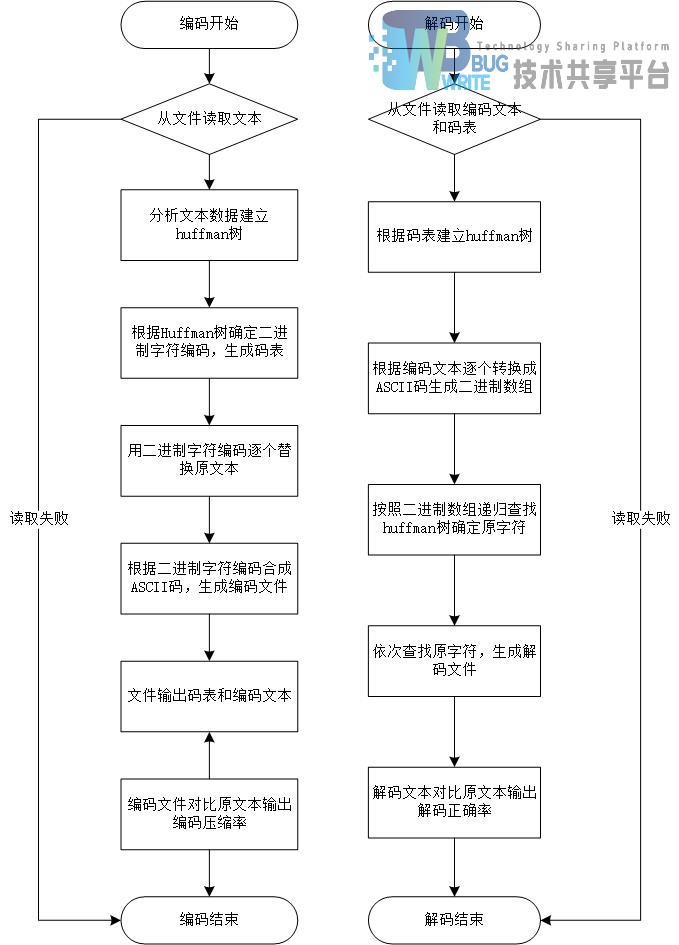
1 原理
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
参考文档和完整的文档和源码下载地址: