DataFrame 是 pandas 中两个主要数据结构之一,另一个是 Series。DataFrame 的文档在这里:传送门。
因为这几天需要使用这个数据结构来完成一个小作业,在这里总结一下 Dataframe 的一些基本用法。
创建
首先我们来看一看 Dataframe 的创建,Dataframe 文档里给出的构造函数是:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
其中 data 的类型可以是 numpy ndarray、字典或者 Dataframe。相当于是你构造 DataFrame 的初始值。
index 是行索引,columns 是列索引,我看的这两个一般都给的是列表。
dtype 是指定 data 里元素的数据类型。上面那个链接给的例子里有涉及到这一项,可以去看看。
我们来看一个实例
>>> import pandas as pd
>>> from pandas import DataFrame
>>> data = {'state':['ok', 'normal', 'good', 'bad'],
'year':[2000, 2001, 2002, 2003],
'pop':[3.7, 3.6, 2.4, 0.9]}
>>> print(DataFrame(data)) # 行索引 index 默认为0,1,2,3
state year pop
0 ok 2000 3.7
1 normal 2001 3.6
2 good 2002 2.4
3 bad 2003 0.9
>>> print(DataFrame(data, index = ['one', 'two', 'three', 'four'])) # 指定行索引
state year pop
one ok 2000 3.7
two normal 2001 3.6
three good 2002 2.4
four bad 2003 0.9
>>> print(DataFrame(None, index=range(3), columns=range(4))) # data 默认是 None,第一个我们不写也会得到下面结果
0 1 2 3
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 NaN NaN NaN NaN
>>> print(DataFrame(2, index=range(3), columns=range(4)))
0 1 2 3
0 2 2 2 2
1 2 2 2 2
2 2 2 2 2
有一些函数返回的数据类型也是 DataFrame,比如 DataFrame.from_dict, pandas.read_csv, pandas.read_table, pandas.read_clipboard 等(这个可以看文档)
元素访问
想要获取 DataFrame 结构中某一元素,我们可以像数组一样访问
值得注意的是:这个数据结构是按先列后行来进行索引的。
>>> dataframe = DataFrame(2, index=range(3), columns=range(4))
>>> dataframe
0 1 2 3
0 2 2 2 2
1 2 2 2 2
2 2 2 2 2
>>> dataframe[3][2] # 访问第 3 列第 2 行的数据
2
>>> type(dataframe[3][2])
<class 'numpy.int64'>
# 可以使用 ix 属性来按 先行后列 访问数据
>>> dataframe.ix[2, 1] # 访问第 2 行,第 1 列的数据
2
获取行列
想要获取其中的某一行或某一列,可以直接使用索引即可
下图来自参考资料第一个链接,侵删。
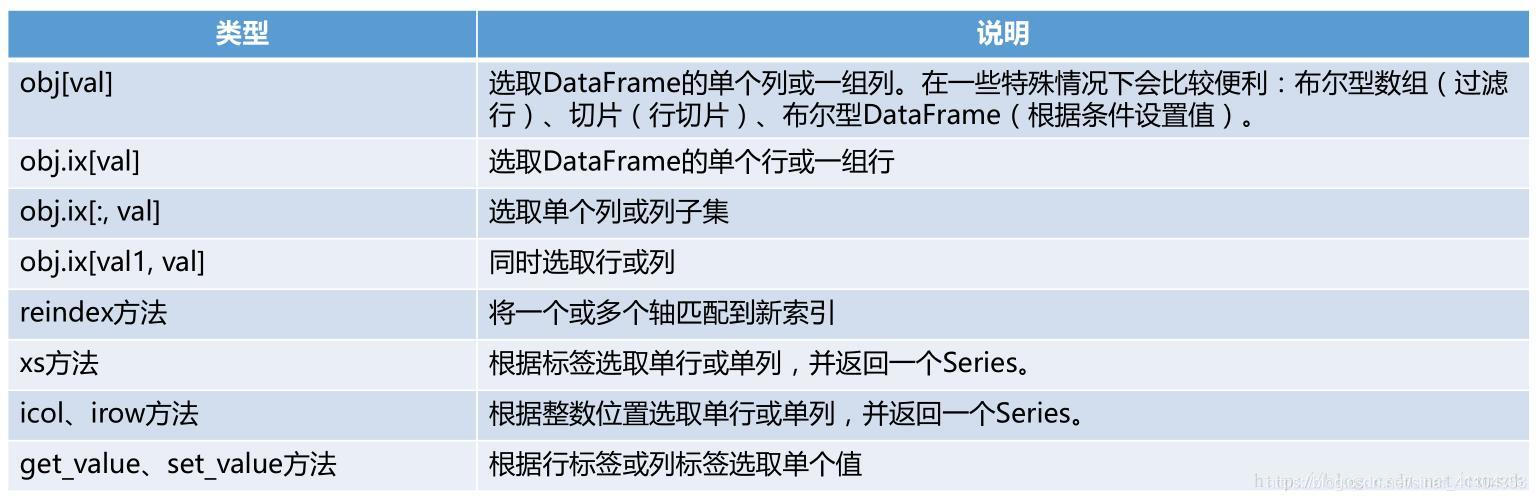
# 先简单介绍下 nparray
>>> import numpy as np
>>> np.arange(4)
array([0, 1, 2, 3])
>>> np.arange(16).reshape((2, 8)) # 将 nparray 拆分成 2×8 的格式
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15]])
# 创建一个 4 行 2 列的 DataFrame
>>> dataframe = DataFrame(np.arange(8).reshape((4, 2)),
index=['zero', 'one', 'two', 'three'])
>>> dataframe
0 1
zero 0 1
one 2 3
two 4 5
three 6 7
>>> dataframe[0] # 获取第 0 列
zero 0
one 2
two 4
three 6
Name: 0, dtype: int32
>>> dataframe.ix[1] # 获取第 1 行
0 2
1 3 # 这里解释下:第一列 0 1 是索引信息,后一列 2 3 是行数据,不过把它竖起来了。
Name: zero, dtype: int32
>>> dataframe.ix['one'] # 获取第 1 行
0 2
1 3
Name: zero, dtype: int32
>>> type(dataframe[0])
<class 'pandas.core.series.Series'>
常用属性
没介绍的不代表不常用,而是我就知道下面俩
矩阵转置
将矩阵转置十分简单,用属性 T 即可。我觉得用处是当你记不住咋获取行的时候,转置获取是一个不错的方法。
>>> dataframe = DataFrame(np.arange(8).reshape((4, 2)), index=['zero', 'one', 'two', 'three'])
>>> dataframe
0 1
zero 0 1
one 2 3
two 4 5
three 6 7
>>> dataframe.T
zero one two three
0 0 2 4 6
1 1 3 5 7
元素个数
使用 size 属性就可以了
>>> dataframe.size
8
行元素个数
>>> dataframe.iloc[:,0].size # 这里用到了切片。对 python 基本的切片还有点印象的同学应该可以回想起来 : 啥也不写表示一个拷贝。
4
列元素个数
>>> dataframe.columns.size
2
操作
遍历
行遍历
对行进行遍历可以使用 dataframe.values 返回的 ndarry 进行遍历。
>>> dataframe.values
array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])
>>> type(dataframe.values)
<class 'numpy.ndarray'>
>>> for row in dataframe.values:
for i in range(row.size):
print(row[i])
0
1
2
3
4
5
6
7
当然,其实 DataFrame 也已经给我们封装好了函数:DataFrame.iterrows() 以及 DataFrame.itertuples()
两者官方文档里更推荐使用 itertuples()。具体的使用文档里比较详细,这里就不提了。
列遍历
列遍历可以通过先将矩阵转置再遍历行。我觉得应该也有函数,但是由于学识所限,目前还不太了解。
求和
行求和
>>> dataframe
0 1
zero 0 1
one 2 3
two 4 5
three 6 7
>>> dataframe.sum(axis=1)
zero 1
one 5
two 9
three 13
dtype: int64
列求和
>>> dataframe.sum()
0 12
1 16
dtype: int64
判等
判断两个 DataFrame 是否相等可以使用 DataFrame 的 equal() 方法。
# 下面创建了两个 DataFrame
>>> dataframe1 = pd.DataFrame(np.arange(2, 10).reshape(4, 2))
>>> dataframe2 = pd.DataFrame(np.arange(8).reshape(4, 2))
>>> dataframe1
0 1
0 2 3
1 4 5
2 6 7
3 8 9
>>> dataframe2
0 1
0 0 1
1 2 3
2 4 5
3 6 7
>>> dataframe1.equals(dataframe2)
False
>>> dataframe3 = pd.DataFrame(np.arange(8).reshape(4, 2))
>>> dataframe2.equals(dataframe3)
True
存储
DataFrame 有一系列的以 to_ 开头的函数支持将 DataFrame 写入到不同格式的文件中。具体的可以在文档里 C-f 搜索。
这里我比较喜欢的是 to_html(文件路径) 这个函数,也不需要额外的包什么的,拿来即用,下面是效果:
可以看到是十分的整齐简单~
如果你不想要 0-14 那些索引信息的话,可以设置 header=None 或者 index=None 来隐藏
参考资料
https://blog.csdn.net/cxmscb/article/details/54632492
https://blog.csdn.net/jinlong_xu/article/details/61193418