1、unicode的诞生
首先明白计算机能识别的都是二进制010101010这种代码,但是这些010010111人是难以看懂的,于是美国人就用ASCII码制作了一张表,里面包含从a、b、c.......@%$等128个字符差不多半个字节(1111,1111==256 0111,1111==128),为了以后扩充方便就取了一个字节,最高位是0,就这样将英文字符、字符、数字128个包含进去了,下次计算机的0101这种二进制代码就直接查这个ASCII表就知道对应的字符。
但是,美国用的字母,德国,英国。。。最重要的我们中国汉子几万个,一张表存不下啊。
于是聪明的中国人发明了GBK编码表,gbk编码规定,计算机不能在每次都只读一个字节(00000000,8位表示一个字节)那么死板了,你要先看看第一位是不是为0,要是为0 的话,就当作ASCII码来读入一个字节,不然的话就读入两个字节(汉子太多一个字节存不下,读入两个字节表示汉字就查GBK)。
那么每个国家一个表,这可就尴尬了,相互通信的时候由于解码方式不同就会导致乱码(用ASCII发邮件,计算机查ASCII表转换成对应0101010二进制,接收的人用GBK解码,将010101取查GBK肯定就查不到啊)。
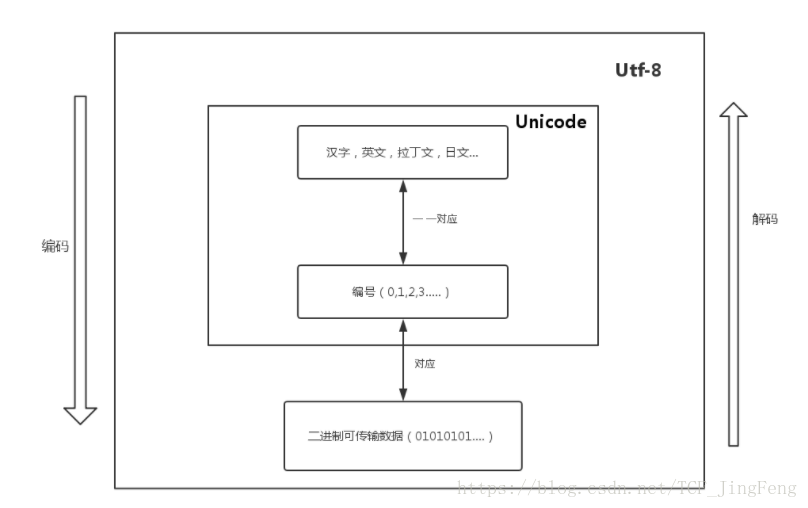
于是,国际组织就发明了一套公用的表unicode编码,将所有国家,所有字符都收进去了从0一直到100多万(用三个字节)
2、utf-8的产生
虽然世界通用的表unicode是有了,但是有人就发现这有点浪费资源啊。每次让计算机读取三个字节然后参照Unicode表解码,那么像a、b...0、1、2...这些一个字节就够了的就太浪费了。
于是uft-8,utf-16,utf-32这些编码方案就出现了。utf-16是用两个字节来编码所有的字符,utf-32则选择用4个字节来编码,utf-8为了节省资源,采用变长编码,编码长度从1个字节到6个字节不等。可由于互联网大部分是1个字节(代码很多英文的),所以最后大家选择用的最多的还是utf-8。
总结一句就是
=====================

=====================
一个unicode码可能转成长度为一个BYTE,或两个,三个,四个BYTE的UTF8码,取决于unicode码的值(utf-8可变长)。
英文unicode码因为值小于十六进制表示的0x80(即8x16=128,即01111111=128,即一个字节就可以表示了),只要用一个BYTE的UTF8传送,比送unicode两个BYTEs快。
UTF8是为传送unicode而想出来的“再编码”方法罢了,将unicode编码之后再在网络传输。
因此,UTF-8最适合用来作为字符串网络传输的编码格式,自动变长节约空间嘛。解码的时候按UTF-8先解码成unicode,在查unicode表解码二进制,如下图: