Collection
来源于Java.util包,实用常用的数据结构,字面意思就是容器
主要方法
boolean add(Object o)添加对象到集合
boolean remove(Object o)删除指定的对象
int size()返回当前集合中元素的数量
boolean contains(Object o)查找集合中是否有指定的对象
boolean isEmpty()判断集合是否为空
Iterator iterator()返回迭代器
boolean containsAll(Collection c)查找集合中是否有集合c中的元素
boolean addAll(Collection c)将集合c中所有的元素添加给该集合
void clear()删除集合中所有元素
void removeAll(Collection c)从集合中删除c集合中也有的元素
void retainAll(Collection c)从集合中删除集合c中不包含的元素继承等关系如下:
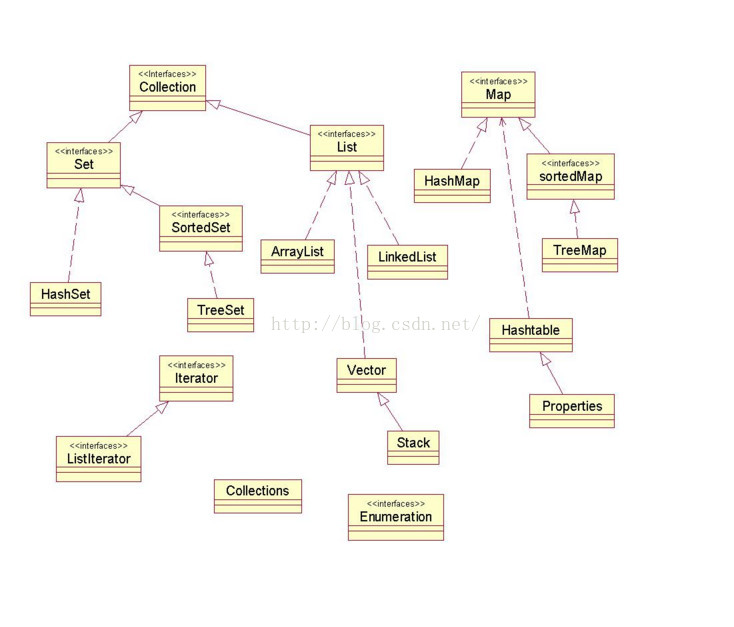
List
元素有序的(怎么存的就怎么取出来,顺序不会乱),元素可以重复,因为该集合体系有索引。继承于Collections接口,所以具有Collection的一些常见的方法
ArrayList
底层的数据结构使用的是数组结构(数组长度是可变的百分之五十延长)(特点是查询很快,但增删较慢)
主要方法
boolean add(Object o)添加元素到List尾部
void add(int index,Object o)添加元素到List指定位置
void clear()删除集合中所有元素
boolean contains(Object o)查找集合中是否有指定的对象
Object get(int index)返回指定index上的元素
boolean isEmpty()判断List是否为空
Object remove(int index)删除指定位置上的元素
boolen remove(Object o)删除指定位置上的元素
int size()返回当前集合中元素的数量LinkedList
底层的数据结构是链表结构
Vector & Stack
Vector类似ArrayList,但Vector为同步,在多线程同时访问时安全性高。
Stack为栈,后进先出。
Stack方法
boolean empty() 为空?
Object peek() 查看栈顶对象(不删)
Object pop() 返回出栈的栈顶对象
push(Object item)入栈
int search(Object o)返回对象的indexSet
存储无序(存入和取出的顺序不一定相同)元素,不能存储相同的元素。
继承于Collections接口,所以具有Collection的一些常见的方法
常见方法
add() 向集合中添加元素
clear() 去掉集合中所有的元素
contains() 判断集合中是否包含某一个元素
isEmpty() 判断集合是否为空
iterator() 主要用于递归集合,返回一个Iterator()对象
remove() 从集合中去掉特定的对象
size() 返回集合的大小hashSet
哈希表边存放的是哈希值。HashSet存储元素的顺序并不是按照存入时的顺序(和List显然不同) 是按照哈希值来存的所以取数据也是按照哈希值取得。
当你试图把对象加入HashSet时,HashSet会使用对象的hashCode来判断对象加入的位置。同时也会与其他已经加入的对象的hashCode进行比较,如果没有相等的hashCode,HashSet就会假设对象没有重复出现。
因此总的来说,元素的哈希值是通过元素的hashcode方法 来获取的, HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法 如果 equls结果为true ,HashSet就视为同一个元素。如果equals 为false就不是同一个元素。
哈希值相同equals为false的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。通过hashCode值来确定元素在内存中的位置。一个hashCode位置上可以存放多个元素。
treeSet
会将里面的元素默认排序。TreeSet底层使用的是TreeMap,TreeMap的底层实现是红黑树。我们需要告诉TreeSet如何来进行比较元素,如果不指定,就会抛出异常
如何指定比较的规则,需要在自定义类(Person)中实现Comparable接口,并重写接口中的compareTo方法
public class Person implements Comparable<Person> {
private String name;
private int age;
...
public int compareTo(Person o) {
if() return 0; //当compareTo方法返回0的时候集合中只有一个元素
else if()return 1; //当compareTo方法返回正数的时候集合会怎么存就怎么取
else return -1; //当compareTo方法返回负数的时候集合会倒序存储
}
}Map
hashMap
hashmap比较重要知识点较多,下次仔细学习之后再仔细写
https://www.cnblogs.com/skywang12345/p/3310835.html
事实上Java的数据无非就三种,基本类型,引用类型(类似C里面的指针类型)和数组,有些地方说是2种类型,只有引用类型和数组。通过这三种数据类型可以构建出任何数据结构。
而HashMap也是用数组来构建,只不过数据数组的数据类型是一个叫做Entry的内部类来保存key、value、hash(不是hashCode)和next(也就是链表的下一个元素)
其实HashSet也是HashMap,只不过比较特殊,没有使用Entry的value而只用了key而已。
void clear()
Object clone()
boolean containsKey(Object key)
boolean containsValue(Object value)
Set<Entry<K, V>> entrySet()
V get(Object key)
boolean isEmpty()
Set<K> keySet()
V put(K key, V value)
void putAll(Map<? extends K, ? extends V> map)
V remove(Object key)
int size()
Collection<V> values()treemap
看完红黑树再写