8-1 -A SparkSQL愿景之一写更少的代码(代码量和可读性)


8-2 -B SparkSQL愿景之一写更少的代码(统一访问操作接口)





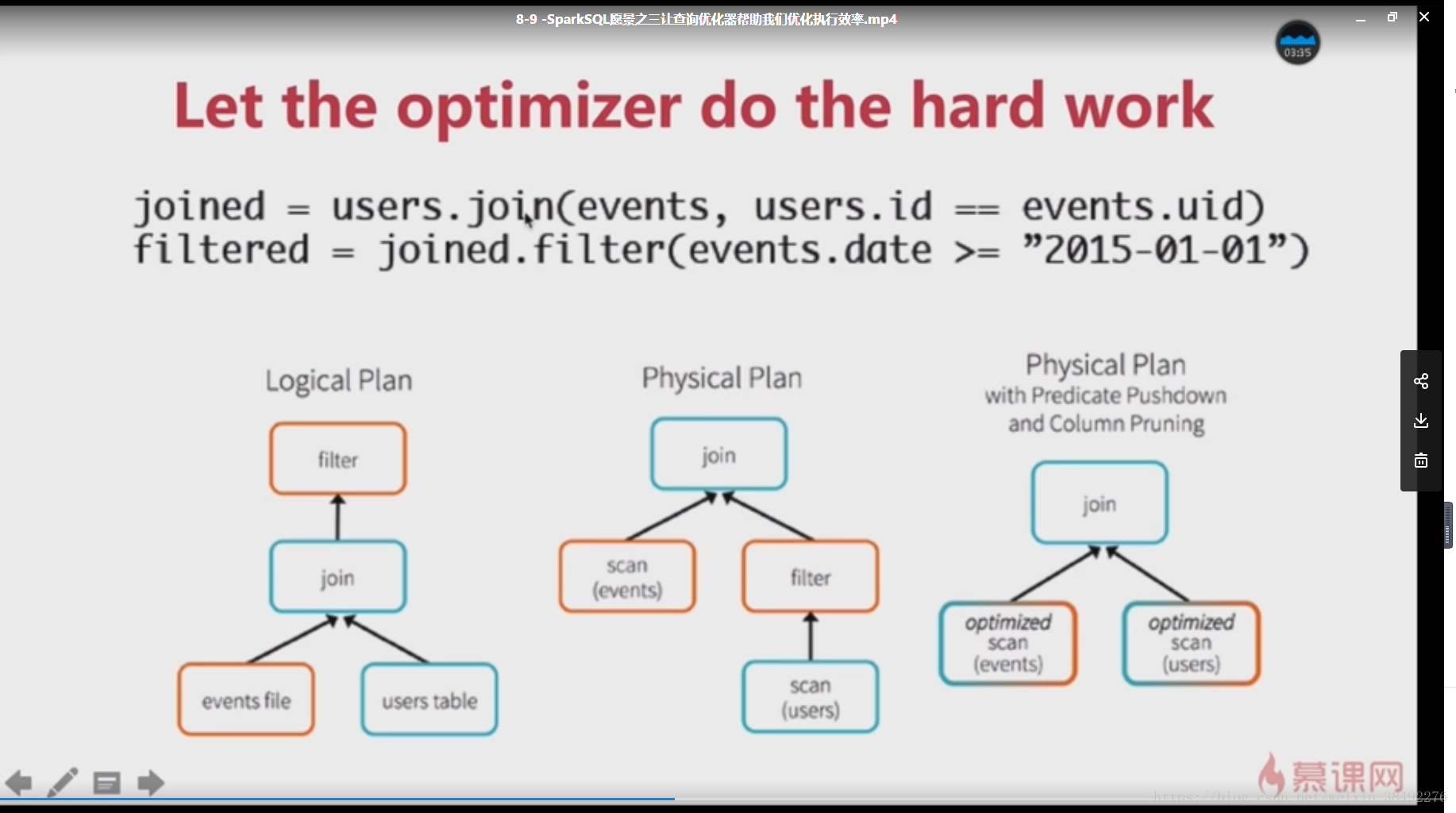
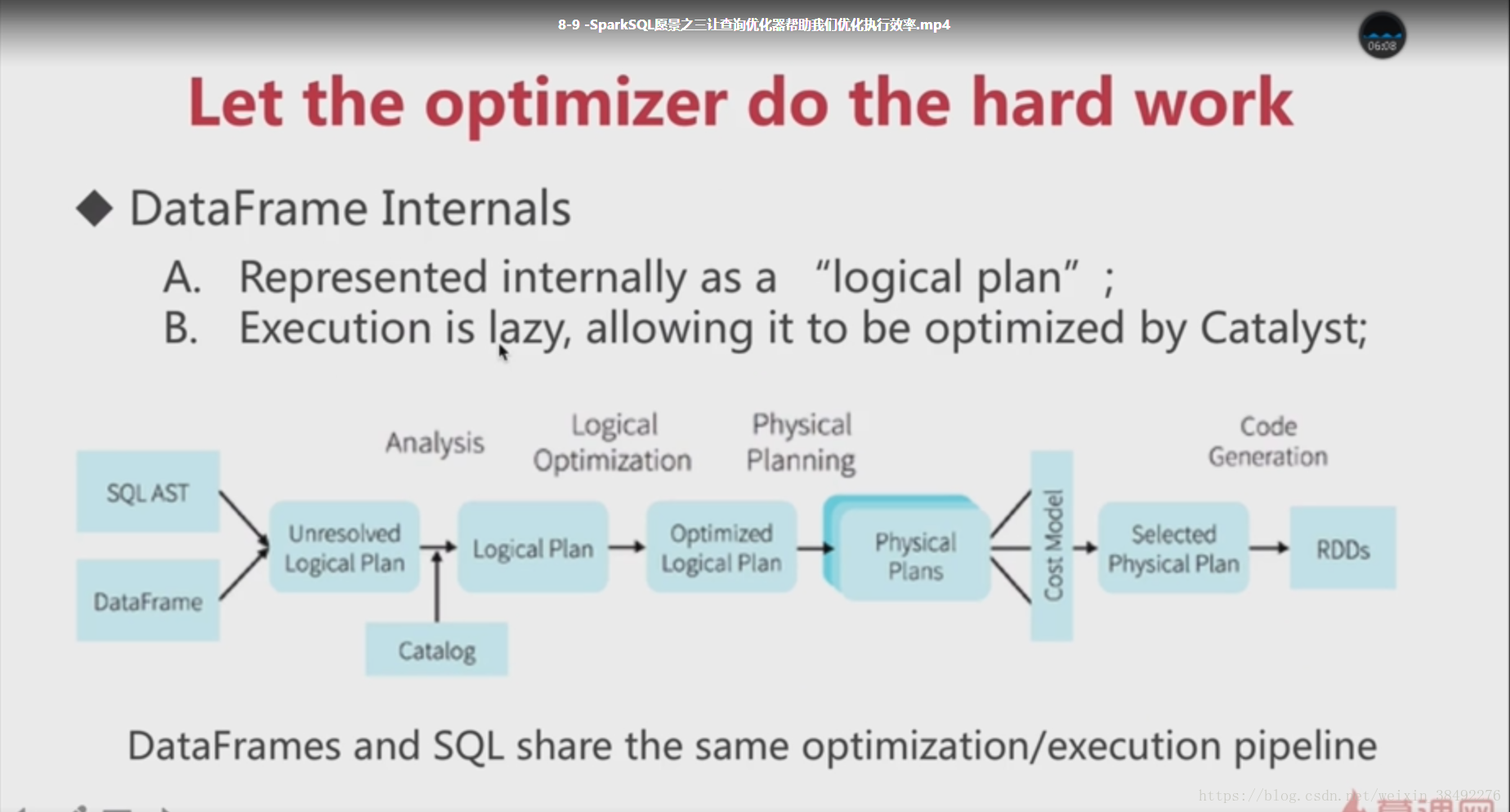
8-3 -C SparkSQL愿景之一写更少的代码(强有力的API支持)

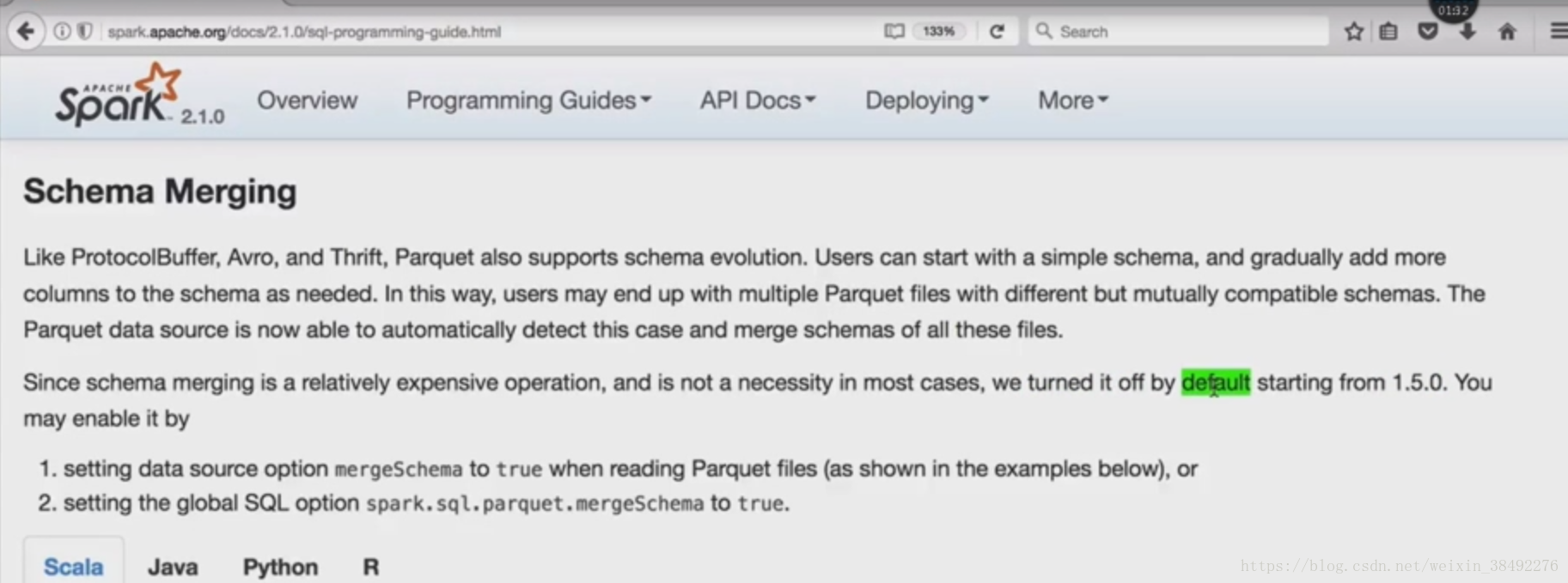
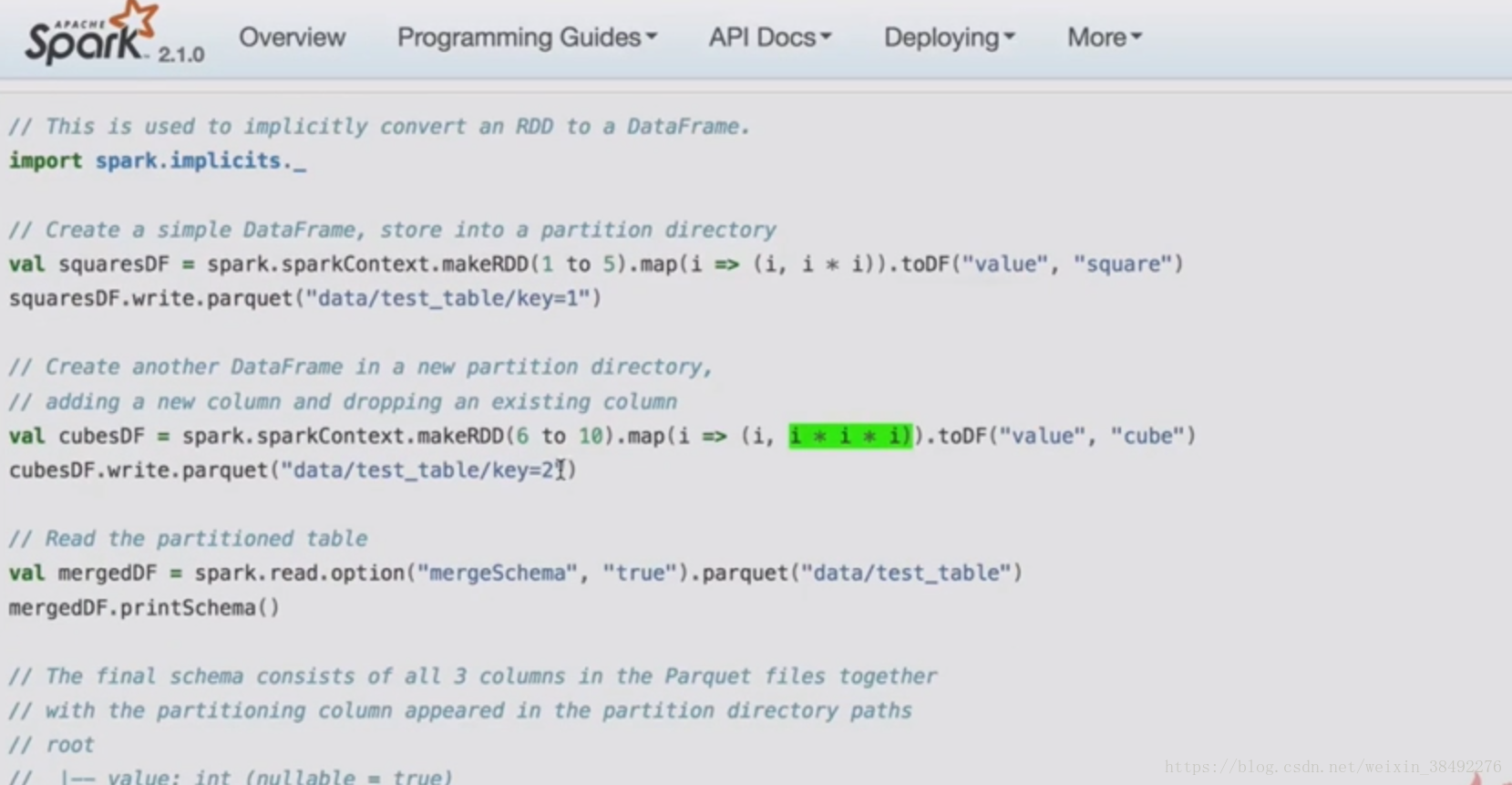
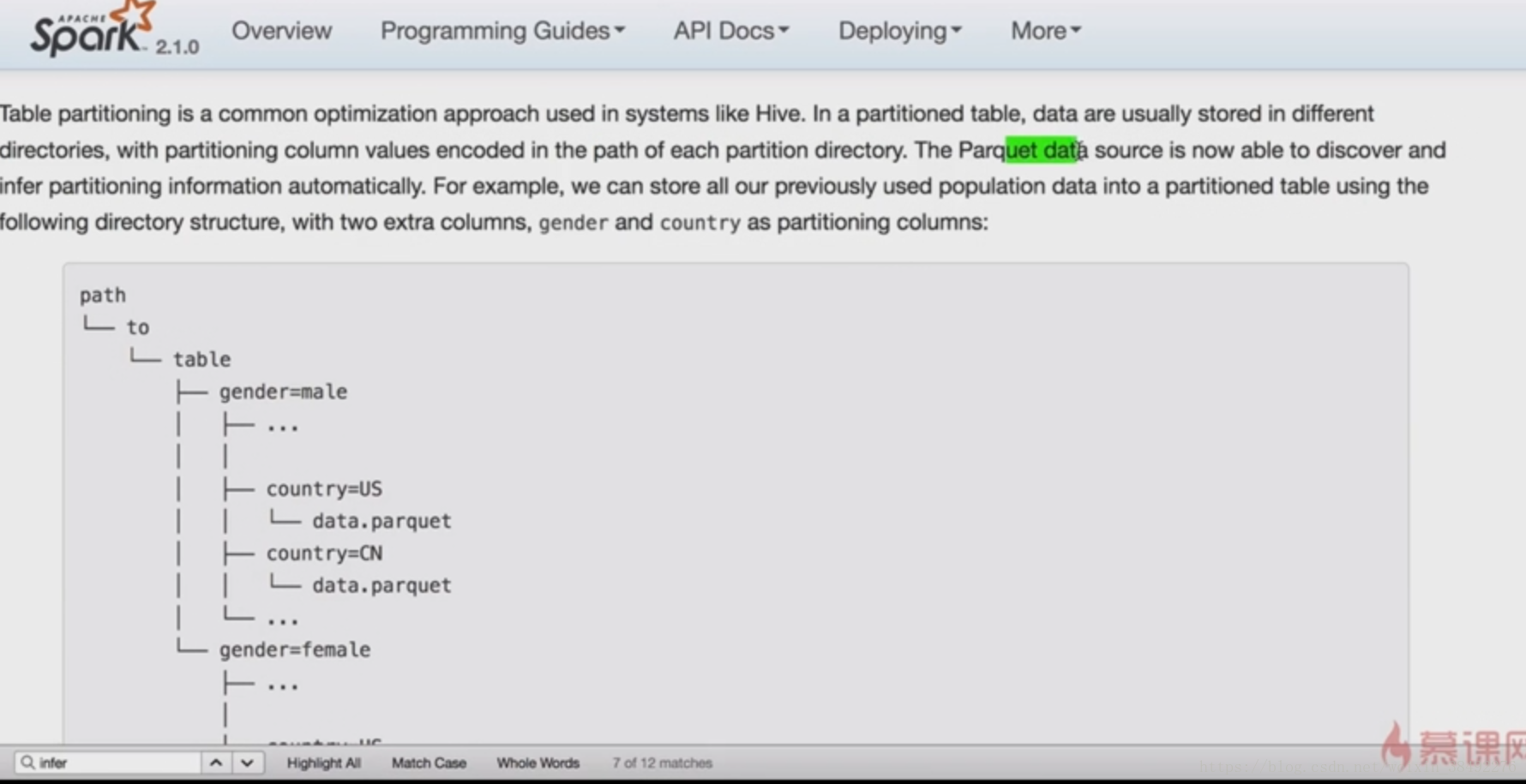
8-4 -D SparkSQL愿景之一些更少的代码(Schema推导)



源码地址:
package com.imooc.spark
import org.apache.spark.sql.SparkSession
/**
* Schema Infer
*/
object SchemaInferApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SchemaInferApp").master("local[2]").getOrCreate()
val df = spark.read.format("json").load("file:///Users/rocky/data/json_schema_infer.json")
df.printSchema()
df.show()
spark.stop()
}
}