嘿嘿嘿,哈哈哈(摩拳擦掌中)。
今天的工作做完了,让我们开始继续看《大话数据结构》。 ^ - ^
今天要看的是线性表。最简单也最常用。它的英文名是List。
线性表:零个或多个数据元素的有限序列。
当线性表里的元素为零个的时候,就称为空表。
线性表主要分为顺序存储和链式存储,先来看看简单一点的顺序存储。
一.线性表的顺序存储
线性表的顺序存储:指的是用一段地址连续的存储单元依次存储线性表的数据元素。
下面来看看顺序存储的结构代码:
#define MAX_SIZE 100 //存储空间初始分配量
typedef int ElemType; //ElemType 现定义为int
typedef strut{
ElemType data[MAX_SIZE]; //数组存储元素
int length; //线性表当前长度
}SqList; //别名SqList特别注意,length是表示当前线性表的长度,是可变的,但length不会超过data的最大长度。
下面就可以来看看基本的操作啦:
1.查询操作
// 得到线性表L中第i个数据
void GetElem (SqList L , int i ,ElemType *e){
int currentLength = L.length;//当前线性表长度
if(currentLength == 0 || i < 1 || i > currentLength){
//空表,越界
}else{
*e = L.data[i-1]; //得到数组中下标为i-1的值
}
}注:默认线性表的长度从1开始,而默认的数组下标从0开始,所以线性表中第i个数据对应数组下标为i-1的数据。
2.插入操作
//在线性表中的第i个位置插入新元素e
void ListInsert(SqList *L , int i ,ElemType e){
int currentLength = L->length;
if(currentLength == MAX_SIZE || i < 1 || i > currentLength + 1){
//表满,越界
}else{
if(i <= currentLength){//插入位置不在表尾
for(int k = currentLength - 1; k >= i-1 ; k--){
L->data[k+1] = L->data[k];//把要插入位置后的元素向后移动
}
}//end if
L->data[i-1] = e; //插入新元素e
L->length++; //线性表长度+1
}//end if
}注:把元素向后移的时候,从表尾开始,一直到数组下标为i-1为止。插入新元素e后,记得将线性表长度+1。
2.删除操作
//删除线性表的第i个位置的元素
void ListDelete(SqList *L,int i,ElemType *e){
int currentLength = L->length;
if(currentLength == 0 || i > currentLength || i < 1){
//空表,越界
}else{
*e = L->data[i-1];//需要可用于保存数据,不需要则去除
if(i < currentLength){//如果i不在表尾
for(int k = i -1; k < currentLength - 1; k++){
L->data[k] = L->data[k+1];//把删除位置后的元素向前移动
}
L->length--;//线性表长度-1
}//end if
}//end if
}注:把元素向前移动的时候,从删除位置i对应的下标i-1开始一直到表尾,然后把线性表的长度-1。
下面我们来分析一下线性表查询插入删除的时间复杂度。
查询的时间复杂度
直接查找到对应下标的数据,时间复杂度很明显为O(1)。
插入和删除的时间复杂度
最好的情况:插入和删除的位置都在表尾,则不用进行元素的移动,时间复杂度为O(1)。
最坏的情况:插入和删除的位置都在表首,则需要将整个表的元素向前移动或者向后西东,时间复杂度为O(n)。
平均的情况:插入和删除需要移动n-i个元素,平均概率下,最终的移动次数就与最中间的元素的移动次数相等,为n-1/2 。根据上一章的大O阶推导法,可得时间复杂度仍为O(n)。
最后来概括一下线性表的顺序存储结构的优缺点:
优点:
1.无须为表示表中元素之间的逻辑关系而增加额外的存储空间(一开始就定义了最大的存储空间)
2.可以快速地存取表中的任意位置的元素
缺点:
1.插入和删除操作需要移动大量元素
2.当线性表长度变化较大时,难以确定存储空间的容量
3.造成存储空间的“碎片”(所谓碎片是指没有用到的数组空间)
今天就先到此为止啦,下班咯 ^ - ^ ————2016.7.29 18:00
下面给出测试代码:
//为了使结果显而易见,将List输出
void PrintList(SqList L){
cout<<"SqList: ";
for (int i =0; i< L.length; i++)
cout<<L.data[i] <<" ";
cout<<" length is "<<L.length<<endl;
}int main()
{
//线性表初始化
SqList L;
int n = 8;
for (int i =0; i< n; i++)
L.data[i] = i*i;
L.length = n;
PrintList(L);
//查询第i个位置的元素
int e;
int i = 4;
GetElem(L,i,&e);
cout<<"get "<<i<<" is "<<e<<endl;
//在第i个位置插入e
i = 2;
e = 99;
ListInsert(&L,i, e);
cout<<"insert into "<<i<<" is "<<e<<endl;
PrintList(L);
//删除第i个位置的元素
i = 3;
ListDelete(&L,i,&e);
cout<<"delete from "<<i<<" is "<<e<<endl;
PrintList(L);
return 0;
}下面给出测试代码的运行结果:
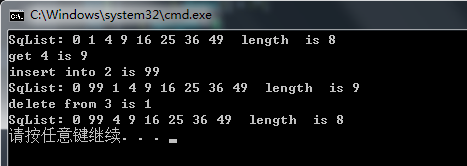
注:如果想下载完整代码的可以去我的资源页下载。
二.线性表的链式存储
首先我们需要知道一个名词——结点,英文名Node,一个Node里面包含了数据域和指针域,数据域用来存储数据元素的信息,指针域内存储的信息可以称为指针或链,用来指示其直接后继的信息。
n个Node链结成一个链表,即为线性表的链式存储结构,因为每个Node只包含一个指针域,又可以称为单链表。
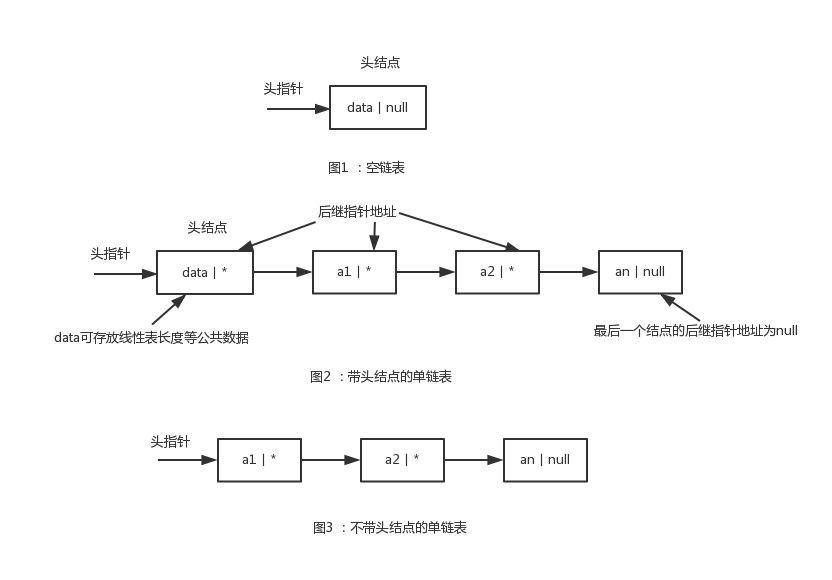
图1是空链表,头结点的后继指针地址为null。
图2是带头结点的单链表,其中头结点的功能,以及和头指针的区别我们会在下面仔细说明。一般使用线性表,都是指有头结点的情况。
图3是不带头结点的单链表。
头指针:
1.在线性表的链式存储结构中,头指针是指链表指向第一个结点的指针,若链表有头结点,则头指针就是指向链表头结点的指针。
2.头指针具有标识作用,故常用头指针冠以链表的名字。
3.无论链表是否为空,头指针均不为空。头指针是链表的必要元素。
头结点:
1.头结点是为了操作的统一与方便而设立的,放在第一个元素结点之前,其数据域一般无意义(当然有些情况下也可存放链表的长度、用做监视哨等等)。
2.有了头结点后,对在第一个元素结点前插入结点和删除第一个结点,其操作与对其它结点的操作统一了。
首元结点也就是第一个元素的结点,它是头结点后边的第一个结点。
3.头结点不是链表所必需的。
加入头结点有什么好处呢?
加了头结点之后,插入、删除都是在后继指针next上进行操作,不用动头指针;
若不加头结点的话,在第1个位置插入或者删除第1个元素时,需要动的是头指针。
例:在进行删除操作时,L为头指针,p指针指向被删结点,q指针指向被删结点的前驱,对于非空的单链表:
1.带头结点时
删除第1个结点(q指向的是头结点):q->next=p->next; free(p);
删除第i个结点(i不等于1):q->next=p->next;free(p);
2.不带头结点时
删除第1个结点时(q为空):L=p->next; free(p);
删除第i个结点(i不等于1):q->next=p->next;free(p);
结论:带头结点时,不论删除哪个位置上的结点,用到的代码都一样;
不带头结点时,删除第1个元素和删除其它位置上的元素用到的代码不同,相对比较麻烦。
下面来看看链式存储的结构代码:
typedef int ElemType; //ElemType 现定义为int
typedef struct Node{ //这个Node一定要写
ElemType data; //存储的数据
Node *next;//后继指针
}Node;//别名为Node
typedef Node *LinkList; //定义LinkList注:data就是数据域,next就是指针域
下面就可以来看看基本的操作啦:
1.创建LinkList
//建立带表头结点的单链表 (从头插入)
void CreateLsit(LinkList *L , int n){
LinkList p ;
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL ;//一个带头结点的单链表
for(int i = 0;i < n ; i++){
p = (LinkList) malloc (sizeof(Node));
p->data = i*i;
//从头结点插入
p->next = (*L)->next;
(*L)->next = p;
}
}
思路:这个比较简单,直接从头结点插入就好了,插入的详细操作在下面会讲解。
//建立带表头结点的单链表(从尾插入)
void CreateLsit2(LinkList *L , int n){
LinkList p , r;
*L = (LinkList)malloc(sizeof(Node));
r = (*L);//尾指针等于头指针
for(int i = 0;i < n ; i++){
p = (LinkList) malloc (sizeof(Node));
p->data = i*i;
//从尾部插入
r->next = p;
r = p;
}
r->next = NULL;//最后尾指针指向null
}思路:新建一个尾结点r,在开始的时候令r=(*L),插入的时候直接令r->next 等于新插入的结点p , 同时将r向后移动,在最后的时候令r->next = NULL;
2.查询操作
//查询LinkList中第i个数据
void GetElem(LinkList L,int i,ElemType *e){
LinkList p;
int j = 1;
p = L->next; //链表L指向的第一个结点
while( p && j < i){
p = p->next;
j++;
}//end while
if(!p || j > i){
//第i个元素为空,越界
}else{
*e = p->data;
}//end if
}思路:
1.创建一个新结点p,让p指向链表的第一个结点,j作为当前位置,从1开始
2. 当p不为null,并且j<i时,遍历链表,让p的指针向后移动,j++
3. 如到链表末尾p为空,则说明第i个元素不存在
4. 否则,讲结点的数据赋值给e
3.插入操作
//在第i个位置之前插入e
void ListInsert(LinkList *L , int i, ElemType e){
int j = 1;
LinkList p,s;
p = *L;
while(p && j < i){
p = p->next;
j++;
}
if(!p || j > i ){
//第i个位置,越界
}else{
s = (LinkList)malloc(sizeof(Node));
s->data = e;
s->next = p->next;
p->next = s;
}
} 思路:
1.创建一个新结点p,让p指向链表的第一个结点,j作为当前位置,从1开始
2. 当p不为null,并且j<i时,遍历链表,让p的指针向后移动,j++
3. 如到链表末尾p为空,则说明第i个元素不存在
4. 否则,创建一个新结点s,将e赋值给s->data,然后就是单链表插入标准语句:s->next = p->next; p->next = s;
4.删除操作
//删除第i个元素
void ListDelete(LinkList *L , int i, ElemType *e){
int j = 1;
LinkList p,q;
p = *L;
while(p->next && j < i){
p = p->next;
j++;
}
if(!(p->next) || j > i ){
//第i个位置,越界
}else{
q = p->next; //q为临时变量
p->next = q->next;
*e = q->data;
free(q);
}
} 思路:
1.创建一个新结点p,让p指向链表的第一个结点,j作为当前位置,从1开始
2. 当p->next不为null,并且j<i时,遍历链表,让p的指针向后移动,j++
3. 如到链表末尾p为空,则说明第i个元素不存在
4. 否则,创建一个临时结点q,令q=p->next,把q->data值赋给e,然后就是单链表删除标准语句:p->next = q->next;最后把q结点用free释放。
下面我们来分析一下线性表查询插入删除的时间复杂度。
查询的时间复杂度
从头结点开始找,一直到i位置结束,时间复杂度为O(n)。
插入和删除的时间复杂度
从头结点开始找,一直到i位置,再进行插入删除操作,时间复杂度仍为O(n)。这样看来,似乎链式存储和顺序存储没有在时间复杂度上没有什么区别。但如果我要在第i个位置同时插入多个元素,顺序存储每次的时间复杂度都是o(n),而链式存储只有在查找第i个位置的时候,时间复杂度为o(n),其余的只需通过赋值和移动指针实现,时间复杂度都是o(1).
由此我们可得出结论:在删除插入操作频繁的时候,链式存储的优势就更明显。
下面给出测试代码:
//输出LinkList
void PrintList(LinkList L){
LinkList p = L->next;
cout<<"LinkList: ";
int j=0;
while (p){
cout<<p->data<<" ";
p=p->next;
j++;
}
cout<<" length is "<<j<<endl;
}int main(){
LinkList L,L1;
//从头插入创建LinkList
CreateLsit(&L,10);
PrintList(L);
//从尾插入创建LinkList
CreateLsit2(&L1,10);
PrintList(L1);
//清楚表
ClearList(&L);
PrintList(L);
//插入
int i = 5;
int e = 99;
ListInsert(&L1,i,e);
cout<<"insert into "<<i<<" is "<<e<<endl;
PrintList(L1);
//查询
GetElem(L1,i,&e);
cout<<"get "<<i<<" is "<<e<<endl;
//删除
ListDelete(&L1,i,&e);
cout<<"delete from "<<i<<" is "<<e<<endl;
PrintList(L1);
return 0;
}下面给出测试代码的运行结果:
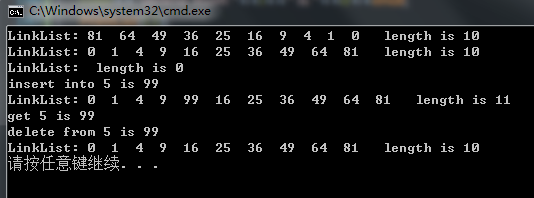
注:如果想下载完整代码的可以去我的资源页下载。
Over ————2016.7.30 16:00