一、环境说明
操作系统:window10
编程语言:Java (JDK版本 11.0.1)
使用IDE:Intellij IDEA
二、算法原理概述
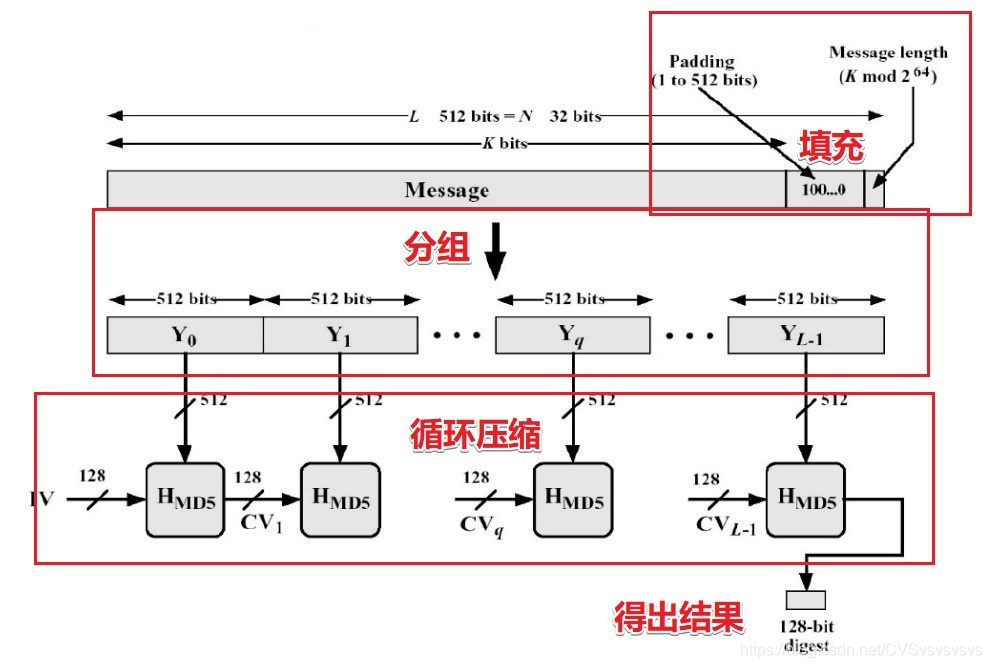
整个MD5(信息摘要算法5)的基本过程可以概括为以下几个步骤:
-
填充:消息为 bits的原始消息数据尾部填充长度为 bits的标识 (至少要填充一个bit) 。使得填充后的消息位数满足 (注:当 )时, 。
填充好的消息尾部需要在附加 值的低64位即 。 最终结果得到 的填充消息。
-
分块:把填充之后的消息结果分割为 个 分组: 。也是 个64字节的分组。
-
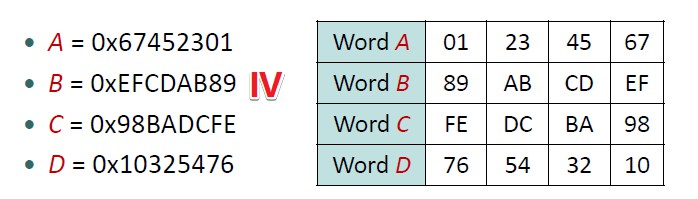
缓冲区初始化:初始化一个 的MD缓冲区,记为 ,表示成4个 的寄存器 ; 。
-
循环压缩 :对L个消息分组 ,逐个经过4重循环的压缩算法。表示为:
-
得出结果:最后一个消息分组经过 压缩得到MD5结果为MD值,即 。
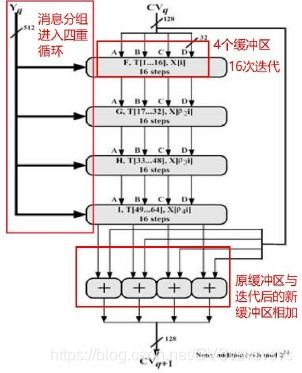
整个加密算法的基本流程如上。而整个加密算法的核心步骤在于 压缩函数流程如下。
-
总控流程: 从 输入128位,分配到缓冲区 ,从消息分组输入512位 ,经过4轮循环,每次循环16次迭代(共64次迭代)之后,得到用于下一轮的输入的 值。如果 ,即输出MD5值。
-
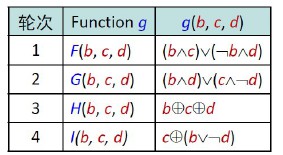
每轮循环:结合T表元素 和消息分组的不同部分 ,每轮固定不同的生成函数 做16次迭代运算,生成下一轮循环的输入。
-
四个生成函数 :
-
消息分组的内容:需要靠下标k来进行运算得到参与 迭代的消息部分,代表当前处理消息分组的第 个 位字,即 。
在各轮循环中第 次迭代 使用的 的确定:
设 :
◌ 第1轮迭代: .
顺序使用 $ X[0, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15]$
◌ 第2轮迭代: .
顺序使用
◌ 第3轮迭代: .
顺序使用
◌ 第4轮迭代: .
顺序使用 -
T 表元素的生成:共有64个元素,用于64次的迭代,每个元素的计算如下。
-
移位数s的确定:
s表共有64个元素,用于64次迭代,各次迭代运算采用的左循环移位的s 值:
-
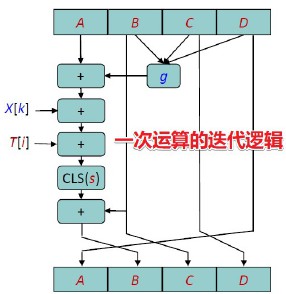
一次迭代运算逻辑: 为寄存器 的内容,每轮循环重的一次迭代运算逻辑如下:
-
对寄存器A进行迭代:
-
对缓冲区的内容进行向左循环变换,即 。
为消息分组的部分内容, 为生成函数, 为T表元素, 为移位数。
三、程序设计
数据结构
本程序使用的数据数据结构如下:
static byte[] M; /* 存放消息字节数组 */
static long[] T = new long[64]; /* 迭代运算的T表, 64个元素,每个元素有32bits,16进制8位 */
/*在迭代中的消息数组*/
static long[] X = new long[16];
/*四个寄存器A,B,C,D,构成128bits的迭代缓冲区*/
static long A = 0x67452301;
static long B = 0xEFCDAB89;
static long C = 0x98BADCFE;
static long D = 0x10325476;
消息数组M的生成如下:
FileInputStream fis = new FileInputStream(inputString); // 读入文件流
BufferedInputStream bis = new BufferedInputStream(fis); // 将文件流读入缓冲区
DataInputStream dis = new DataInputStream(bis); // 将缓冲区数据写入数据流
M = new byte[(int) (length + paddingLength + 8)]; // 填充消息最终长度 满足于 length + padding + 8 = 0 mod 64 字节
// 将文件内容读入全部字节数组M中并填充
for(int i = 0; i < length + paddingLength; i++){
if( i < length){
M[i] = (byte)dis.read();
}
else if(i == length){
M[i] = (byte)128;
}
else{
M[i] = 0;
}
}
迭代运算中的T表数据生成如下:
/*生成迭代的T表格*/
public static void create_T_Table(){
for(int i = 0;i < 64;i++){
T[i] = (long) (Math.floor(Math.abs(Math.sin(i+1)) * (long)Math.pow(2,32)));
}
}
处理消息分组X[]的生成如下:
/*将 512bit的消息处理为 16个字的X数组*/
for(j=0,k=0;j<16;j++,k+=4){
X[j] = ((int)M[i * 64 + k] & 0xFF) | ((int)M[i*64+k+1] & 0xFF) << 8 |
((int)M[i*64+k+2] & 0xFF) << 16 | ((int)M[i*64+k+3] & 0xFF) << 24;
}
重要模块步骤
循环左移s位模块
/*
* @ param x 被移数
* @ param s 左移的位数
* */
public static long rotateLeft(long x, long s){
return (x << s)| (x >> (32 - s)) & 0xFFFFFFFL;
}
/////////////////////////////////////////////////////////////////////
四个生成函数和四个迭代函数。
/*四重循环使用的函数*/
/*
* @param a b c d 为四个缓冲区的内容
* k 为X[k]
* s 为移位数目
* i为 T[j]
*/
public static long F_Func(long a,long b,long c,long d,long k,long s, long i){
return (b + rotate_left(((a + ((b & c) | ((~b) & d)) + k + i) & 0xFFFFFFFFL),s)) & 0xFFFFFFFFL;
}
public static long G_Func(long a,long b,long c,long d,long k,long s, long i){
return (b + rotate_left(((a + ((b & d) | (c & (~d))) + k + i) & 0xFFFFFFFFL),s)) & 0xFFFFFFFFL;
}
public static long H_Func(long a,long b,long c,long d,long k,long s, long i){
return (b + rotate_left(((a + (b ^ c ^ d) + k + i) & 0xFFFFFFFFL) , s)) & 0xFFFFFFFFL;
}
public static long I_Func(long a,long b,long c,long d,long k,long s, long i){
return (b + rotate_left(((a + (c ^ (b | (~d))) + k + i) & 0xFFFFFFFFL), s)) & 0xFFFFFFFFL;
}
/*将小端形式转为大端形式*/
public static long encode(long t){
return ((t >> 24) & 0xff) | ((t >> 16) & 0xff) << 8 | ((t >> 8) & 0xff) << 16 | (t & 0xff) << 24;
}
将数据从小端转为大端的形式
/*将小端形式转为大端形式*/
public static long encode(long t){
return ((t >> 24) & 0xff) | ((t >> 16) & 0xff) << 8 | ((t >> 8) & 0xff) << 16 | (t & 0xff) << 24;
}
获取填充的位数
String inputString = "test1.txt"; // 输入的文件名
File file = new File(inputString); // 文件操作对象
length = file.length(); // 获取文件的字节长度1
// 获取填充的位数
if(length % 64 < 56){
paddingLength = (int)(56 - length % 64); // 字节
}
else if(length % 64 == 56){
paddingLength = 64; // 64 字节
}
else if(length % 64 > 56){
paddingLength = (int) (64 - (length % 64 - 56));
}
将消息分块
// 该循环的作用是:对全部原始消息进行分块,每块大小为64个字节,共512位
for(int i = 0; i < (length + paddingLength + 8)/64; i++){
...
进入4次循环,共64次迭代
// 进入 4 轮循环,每次循环16次迭代,一共64次迭代
for(j = 0; j < 64; j ++){
int div16 = j / 16; // div16 代表每次循环的迭代次数
每次循环的迭代过程
switch (div16){
case 0:
// 第一轮循环,16次迭代
j_factor = j ;
k_index = j_factor;
// 分四个A、B、C、D 缓冲区处理
if(j % 4 == 0)
{
A = F_Func(A,B,C,D,X[k_index],7,T[j]);
}
else if(j % 4 == 1)
{
D = F_Func(D,A,B,C,X[k_index],12,T[j]);
}
else if(j % 4 == 2)
{
C = F_Func(C,D,A,B,X[k_index],17,T[j]);
}
else if(j % 4 == 3)
{
B = F_Func(B,C,D,A,X[k_index],22,T[j]);
}
break;
原寄存器内容与4重循环后的寄存器内容相加,得到下一轮压缩的寄存器值。
A = (A + tmpA) & 0xFFFFFFFFL;
B = (B + tmpB) & 0xFFFFFFFFL;
C = (C + tmpC) & 0xFFFFFFFFL;
D = (D + tmpD) & 0xFFFFFFFFL;
全部消息压缩后,输出结果。
System.out.format("小端形式MD5:%x %x %x %x\n", A,B,C,D);
A = encode(A); // 转为大端形式
B = encode(B);
C = encode(C);
D = encode(D);
System.out.format("大端形式MD5:%x %x %x %x\n",A,B,C,D);
使用java自带的MD5函数进行比对验证。
/*调用java自带md5函数 输出md5值*/
public static String getMd5ForFile(String fileName) throws IOException, NoSuchAlgorithmException {
FileInputStream in = null;
File file = new File(fileName);
in = new FileInputStream(file);
MessageDigest md5 = MessageDigest.getInstance("MD5");
byte[] cache = new byte[2048];
int len;
while ((len = in.read(cache)) != -1) {
md5.update(cache, 0, len);
}
in.close();
BigInteger bigInt = new BigInteger(1, md5.digest());
return bigInt.toString(16);
}
四、运行结果
主函数中的代码如下, 利用java自带的MD5函数进行验证。
public static void main(String[] args)throws IOException, NoSuchAlgorithmException{
String inputString = ""; // 输入的文件名
System.out.println("输入加密的文件名:");
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
inputString = br.readLine();//直接读取字符串
getMD5ByFile(inputString); // 自行实现的函数
System.out.println("java自带的MD5函数结果如下:");
System.out.println(getMd5ForFile(inputString)); // 使用java自带的MD5函数
}
文件内容为hello world时,结果如下

由此可见,基本实现了MD5算法。实验存在的不足之处是:处理大文件的时候,一次性将文件数据读入内存并不太现实,Java内置的解决办法是通过内存映射的方式来实现内存占用的问题,这为优化算法提供了新的思路。