在之前的项目里面用到了线程池的功能,这里记录一下。
我们为什么要实现线程池,下面是我百度查的:
在Java中,如果每当一个请求到达就创建一个新线程,开销是相当大的。在实际使用中,每个请求创建新线程的服务器在创建和销毁线程上花费的时间和消耗的系统资源,甚至可能要比花在处理实际的用户请求的时间和资源要多得多。除了创建和销毁线程的开销之外,活动的线程也需要消耗系统资源。如果在一个JVM里创建太多的线程,可能会导致系统由于过度消耗内存或“切换过度”而导致系统资源不足。为了防止资源不足,服务器应用程序需要一些办法来限制任何给定时刻处理的请求数目,尽可能减少创建和销毁线程的次数,特别是一些资源耗费比较大的线程的创建和销毁,尽量利用已有对象来进行服务,这就是“池化资源”技术产生的原因。
线程池主要用来解决线程生命周期开销问题和资源不足问题。通过对多个任务重用线程,线程创建的开销就被分摊到了多个任务上了,而且由于在请求到达时线程已经存在,所以消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。另外,通过适当地调整线程池中的线程数目可以防止出现资源不足的情况
确实,在项目中如果业务上需要单独创建一个线程来查询或更新某个逻辑,可能会新建一个线程来实现,但是当请求量增大时,对虚拟机的消耗是非常大的,我们使用线程池来优化避免请求过多导致资源崩溃。
下面就是我做的一个简单例子,:
我的例子是maven项目:所以我们需要添加相应的依赖,
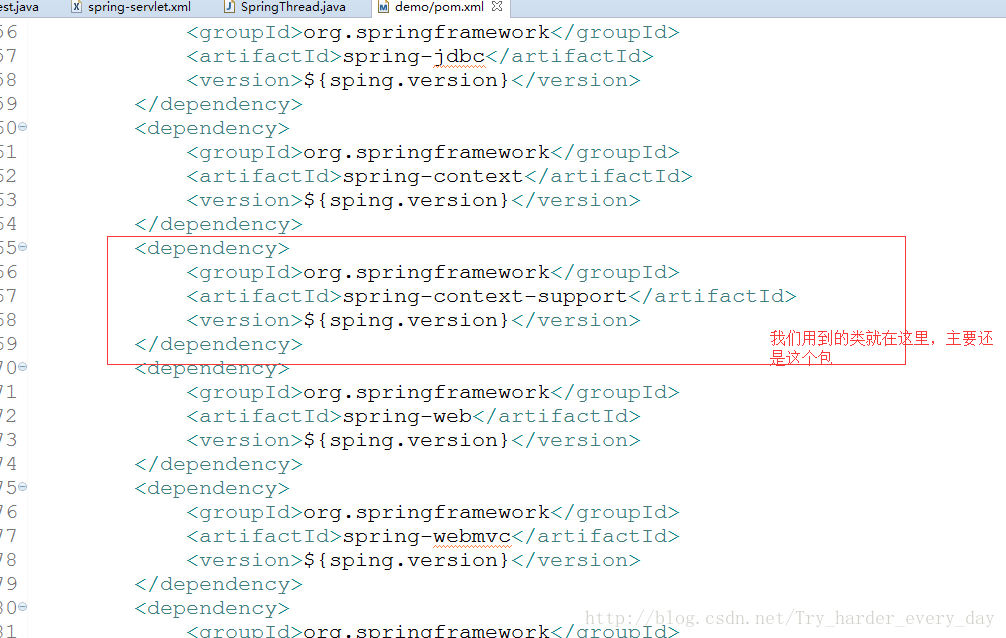
下面是我们的配置:
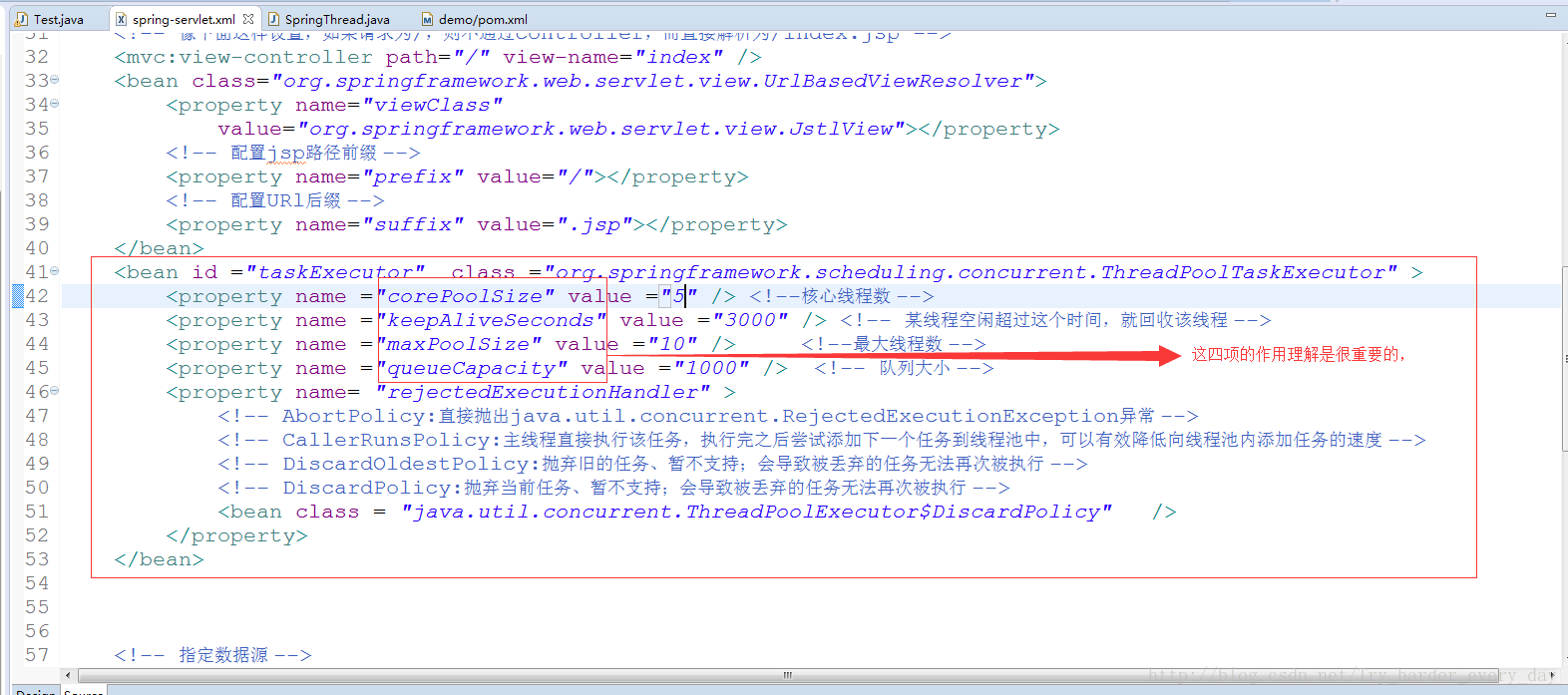
上面标注的这四项的具体作用,在线程池中的流程:
- 如果当前运行的线程数小于corePoolSize,那么就创建线程来执行任务(执行时需要获取全局锁)。
- 如果运行的线程大于或等于corePoolSize,那么就把task加入BlockQueue。
- 如果创建的线程数量大于BlockQueue的最大容量,那么创建新线程来执行该任务。
- 如果创建线程导致当前运行的线程数超过maximumPoolSize,就根据饱和策略来拒绝该任务
可以直接将水倒入池中,也就是新建任务线程。
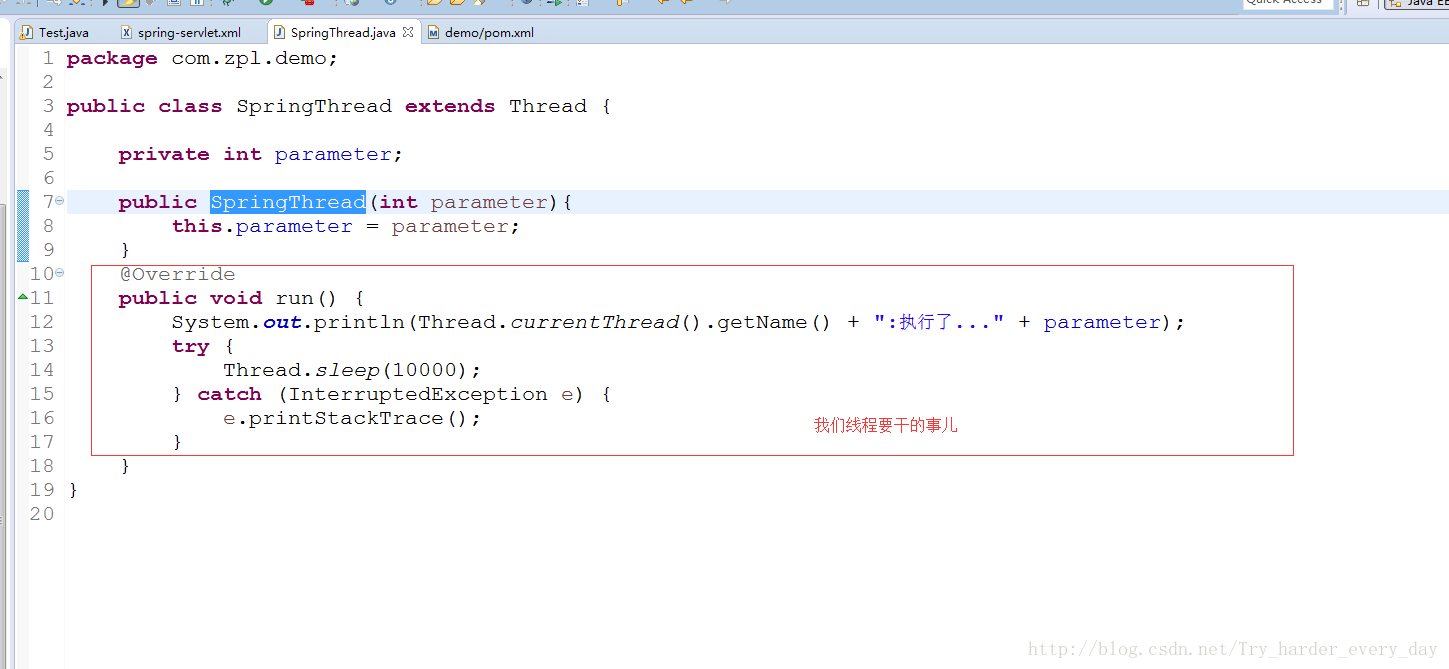
下面我们就是上代码:
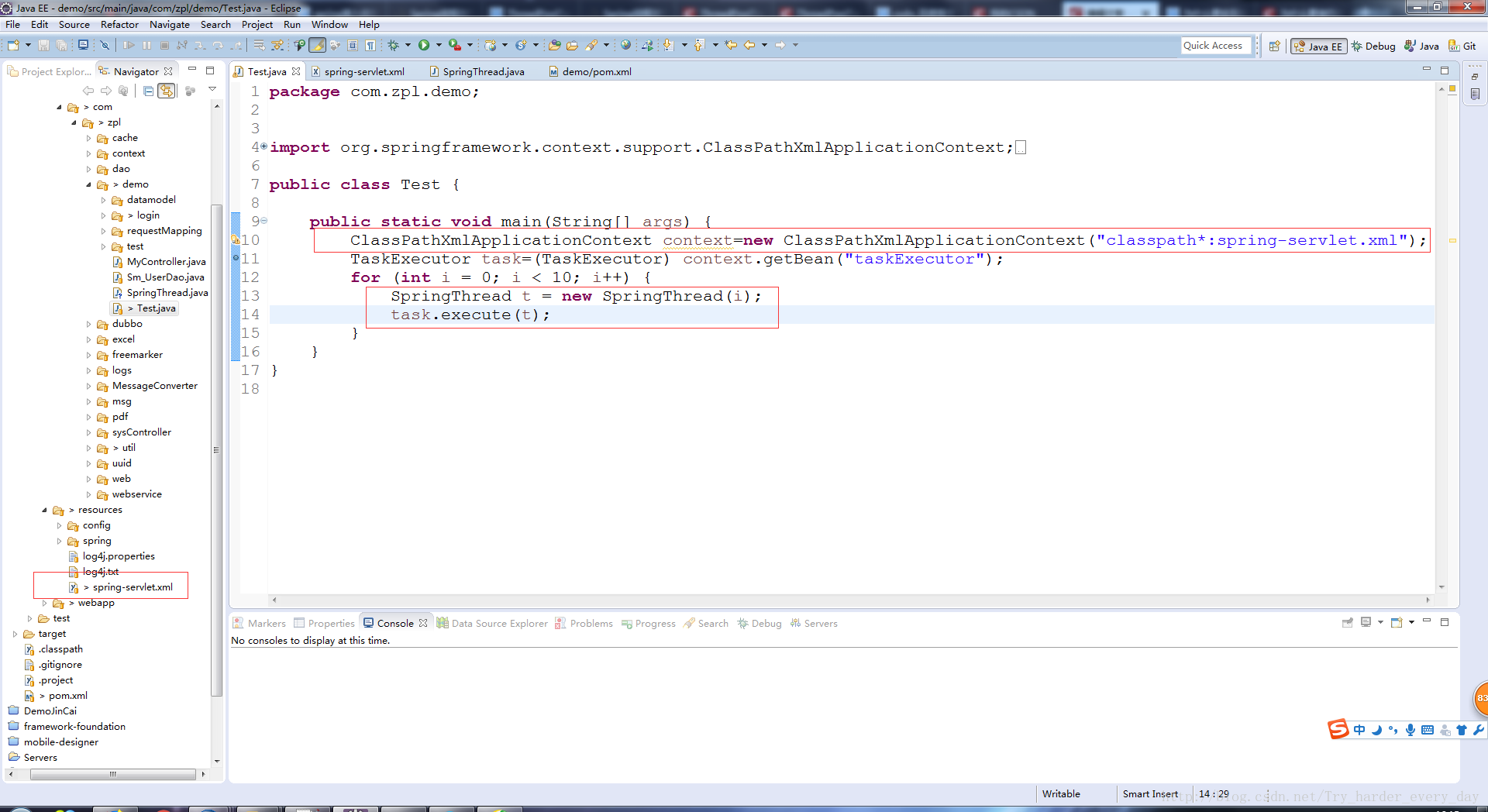
执行后的结果:
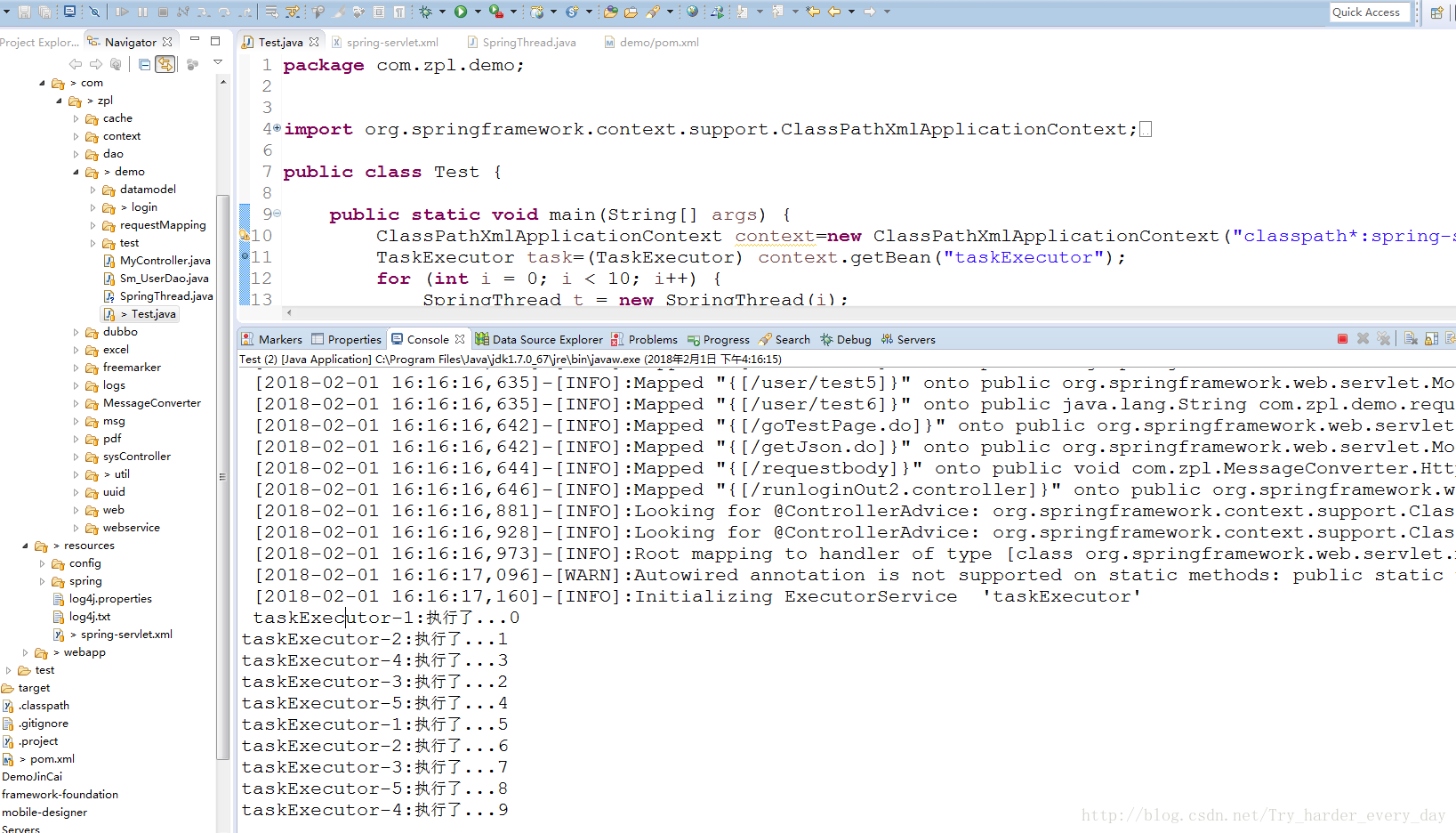
这个只是简单的线程池使用,还有一些复杂的线程池,比如终止线程等一些处理,当然也得遇到不同的业务场景。后续添加一些线程的处理作为记录学习。。。
参考:http://blog.csdn.net/foreverling/article/details/78073105