(尊重劳动成果,转载请注明出处:https://blog.csdn.net/qq_25827845/article/details/84894463冷血之心的博客)
系列文章:
前序:
距离上一篇多线程的总结:Java多线程编程学习总结(一)已经很长一段时间了,在这半年的工作与学习中,我对Java多线程编程的认识又得到了一些提升,将一些概念实际运用到了工作中,做到了学以致用。在这篇博客中,我们来分析一个由于线程池使用不当所造成内存溢出OutOfMemoryError的故障。
场景:
在一个场景中,服务端接收来自一个客户端的请求,并且去查询N个业务方所提供的接口去查询数据,并且将数据返回给客户端进行显示。
分析:
由于业务方的数量N较大,并且用户需要获取到最新的数据,这部分数据涉及到了隐私,拒绝长时间的缓存。所以,这近乎一个实时的数据查询,给服务端带来了一定的压力。
解决方案:
我们可以使用多线程去获取数据,加快数据的返回速度。
问题:
N个业务方提供的接口质量参差不齐,并且可能涉及到跨机房跳转的问题,导致客户端出现请求超时的问题频现,用户体验较差。
解决方案:
我们将多线程返回的数据存入一个缓存中,客户端在获取数据请求发起之后,开始轮询开始发起异步请求,服务端收到请求之后,将当前缓存中已经准备的数据返回,客户端将数据显示,这样给用户一种数据逐渐被获取的感觉,解决了请求超时的问题,提升了用户体验。
---------------------------------------------------------------------------------------------------------------------
好了,问题得到了完美的解决,接下来便是搬砖(开发),联调,测试,上线。
然而好景不长,该服务出现了内存不足,并且自动crash掉的问题。错误文件没有保存下来,大概意思是 OutOfMemoryError: unable to create new native thread. 无法创建新的线程,并且分析了可能的原因并且给出了解决方案。
解决方法1:
(1)故障恰好发生在周末(无心检查代码>_<),既然是内存溢出,那么我的第一选择是看看当前的JVM参数配置,如下所示:
-Xms2048m -Xmx2048m -XX:NewSize=1024m -XX:NewRatio=3 好,既然内存不足,考虑到crash发生在QPS比较高的时刻,我怀疑是创建的线程太多导致内存溢出了。那么我们暂且将内存调大到4G来观察下效果。
---------------------------------------------------------------------------------------------------------------
但是,好景还是不长,同样的问题又出现了。我头特别铁,还是怀疑是QPS太高导致创建的线程太多,才会出现内存溢出的问题。继续解决。
解决方法2:
(1)查询资料后,我进一步调整了JVM的启动参数,设置了-Xss 每个线程的Stack大小,从默认的1M,调整到了512K
(2)修改代码逻辑,减小了一个请求的创建次数,牺牲了用户的体验效果。
----------------------------------------------------------------------------------------------------------------
就这样开开心心的过了两天,以为已经完美解决了该问题。然后两天后,同样的问题继续出现 (挠头......)这个时候我已经头破血流了,怀疑自己的代码是否足够优雅&高效,应该是有某些关键的地方存在内存泄漏的问题,最后导致内存溢出(多大的内存都不好使)。
检查代码,发现服务端收到请求之后,会发起一个HTTP的Get请求,去业务方的接口中去获取数据,其中肯定涉及到了一些关键的资源。就是一个普通的Get请求方法。
/**
* get请求
* @return
*/
public static String doGet(String url) throws IOException {
String strResult = "";
HttpClient client = HttpClients.custom().build();
//发送get请求
HttpGet request = new HttpGet(url);
HttpResponse response = client.execute(request);
/**请求发送成功,并得到响应**/
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
/**读取服务器返回过来的json字符串数据**/
strResult = EntityUtils.toString(response.getEntity());
}
return strResult;
}
查阅了一些参考资料,给出的一致结论是:在高并发请求下,如果HTTPClient和response在使用完毕之后,不进行close,那么将会导致内存溢出。醍醐灌顶呀,仿佛这就是为我这次量身打造的解决方案一样。突然觉得自己在写这些方法的时候不应该直接去copy网上的代码,应该检查才对。
public static String doGet(String url) {
String strResult = "";
CloseableHttpClient client = HttpClients.custom().build();
//发送get请求
HttpGet request = new HttpGet(url);
CloseableHttpResponse response = null;
try {
response = client.execute(request);
/**请求发送成功,并得到响应**/
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
/**读取服务器返回过来的json字符串数据**/
strResult = EntityUtils.toString(response.getEntity());
}
} catch (IOException e) {
LOGGER.error("There is IOException where doGet, Exception:{}",e.toString());
}finally {
// 注意,此处必须close掉连接,否则高并发下会导致服务crash
try {
response.close();
client.close();
} catch (IOException e) {
LOGGER.error("There is IOException where doGet, Exception:{}",e.toString());
}
}
return strResult;
}
接着,我将内存重新调回了2048M, 线程大小使用了默认的1M,而不是512K。
---------------------------------------------------------------------------------------------------------
美滋滋,我感觉已经这次应该差不多了,因为内存泄漏的地方已经被我修复了,没有理由还有问题。然后,同样的问题继续出现 (继续挠头......内心崩溃ing...)好,我继续寻找代码中内存泄漏的点。
这次我先上服务器,通过命令 ps hH p 59178|wc -l (59178是pid)查看了当前服务中的线程个数。详细命令大家可以参考文章:http://www.cnblogs.com/kevingrace/p/5252919.html 。不查不知道,一查吓一跳,当前服务的线程个数竟然是10000+,这是一个恐怖的线程个数,别的服务线程大概都在500以下。很明显,问题发现了,当前服务创建了太多的线程,并且线程个数依然在逐渐上涨之中,应该是程序中的线程创建方式有问题,导致空闲的线程没有被回收。
说到了线程池,我们继续来看线程池的概念和使用。
ThreadPoolExecutor是ExecutorService的默认实现类。这个类是一个线程池,我们只需要调用该类对象的submit或者execute方法,并且传入相应的RunnableTask或者CallableTask即好。
那么我们如何创建线程池呢?
我们先来看看ThreadPoolExecutor的构造函数:

解释下构造函数中涉及到的重要参数:
corePoolSize:线程池中的核心线程数
maximumPoolSize:线程池中允许的最大线程数
(ThreadPoolExecutor 将根据 corePoolSize和 maximumPoolSize设置的边界自动调整池大小。当新任务在方法 execute(java.lang.Runnable) 中提交时,如果运行的线程少于 corePoolSize,则创建新线程来处理请求,即使其他辅助线程是空闲的。如果运行的线程多于 corePoolSize 而少于 maximumPoolSize,则仅当队列满时才创建新线程。)
keepAliveTime:当线程数大于核心线程数时,终止多余的空闲线程等待新任务的最长时间,超过该时间的线程将被回收。
unit:该参数表示keepAliveTime的时间单位
workQueue:用于表示任务的队列
线程池可以解决两个不同问题:由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个 ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。
尽管我们可以通过调整构造函数中的值来创建一个线程池,但是,我们也可以使用较为方便的 Executors 工厂方法 Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)和 Executors.newSingleThreadExecutor()(单个后台线程),它们均为大多数使用场景预定义了设置。
如果你了解Array和Arrays,Collection和Collections的关系,那么你一定会猜到Java提供了Executor框架的同时也提供了工具类Executors,使用该工具类可以非常方便的创建不同类型的线程池,我们通过ThreadPoolThread的构造函数中的核心线程数以及最大线程数来说明下。
Executors.newCachedThreadPool():无界线程池,将 maximumPoolSize 设置为基本的无界值(如 Integer.MAX_VALUE),则允许池适应任意数量的并发任务。来一个创建一个线程,适合用来执行大量耗时较短且提交频率较高的任务。
Executors.newFixedThreadPool(int):固定大小线程池,设置的 corePoolSize 和 maximumPoolSize 相同,则创建了固定大小的线程池。当线程池大小达到核心线程池大小,就不会增加也不会减小工作者线程的固定大小的线程池。
Executors.newSingleThreadExecutor( ):便于实现单(多)生产者-消费者模式。
接下来,我们说一下参数workQueue,也就是任务队列,既然是队列,那么对于任务来说,肯定会存在一个排队策略。
- 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。
- 如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。
- 如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
--------------------------------------------------------------------------------------------------------------
我是华丽的分割线,好了线程池的概念先说到这里,接下来,我们继续看看我遇到的内存溢出问题。
---------------------------------------------------------------------------------------------------------------
在我的程序中,创建了固定大小的线程池,也就是使用了Executors.newFixedThreadPool(50) 。由于我的错误用法,将创建线程池的步骤放在了局部,并不是一个全局的固定大小的线程池,导致客户端的每一个请求都会创建50个线程。固定大小的线程池没有设置其过期回收时间,也就是keepAliveTime=0. 看看源码如下:
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue. At any point, at most
* {@code nThreads} threads will be active processing tasks.
* If additional tasks are submitted when all threads are active,
* they will wait in the queue until a thread is available.
* If any thread terminates due to a failure during execution
* prior to shutdown, a new one will take its place if needed to
* execute subsequent tasks. The threads in the pool will exist
* until it is explicitly {@link ExecutorService#shutdown shutdown}.
*
* @param nThreads the number of threads in the pool
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code nThreads <= 0}
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}也就是说,我们当前的进程所拥有的线程个数在不断的增加,空闲线程并不会被自动回收,导致JVM内存溢出。大概相当于下边的代码运行结果:
package com.ywq;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test {
public static void main(String[] args){
while (true) {
createThread(100000);
}
}
private static void createThread(int num) {
ExecutorService executorService = Executors.newFixedThreadPool(num);
executorService.submit(new Runnable() {
public void run() {
System.out.println("Ok");
}
});
}
}我们在IDEA中设置JVM参数,给当前服务分配2G的内存,-Xms2048m -Xmx2048m -XX:NewSize=1024m -XX:NewRatio=3,运行程序,结果如下:
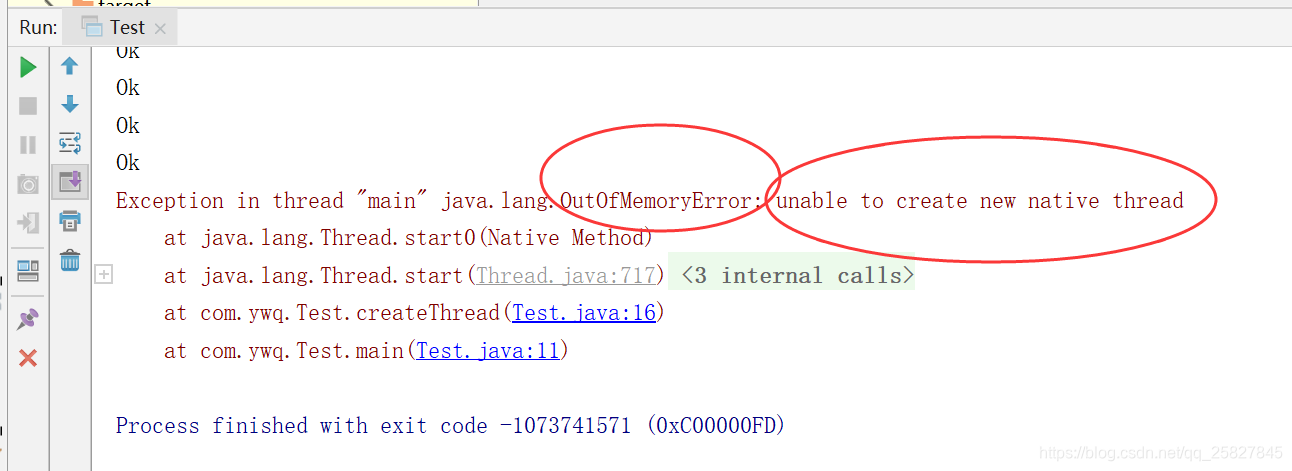
这就是我在程序中所犯的错误,改进代码如下:
package com.ywq;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test {
private static ExecutorService executorService = Executors.newCachedThreadPool();
public static void main(String[] args) {
while (true) {
createThread(100000);
}
}
private static void createThread(int num) {
executorService.submit(new Runnable() {
public void run() {
System.out.println("Ok");
}
});
}
}我们定义了一个全局的线程池,并且是一个newCachedThreadPool,我们看以下源码:
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}空闲线程超过60s之后,会进行空闲线程的回收,但是我们运行上边的测试代码,依然会出现内存不足的问题。为什么呢?
答案:当然会出现了,我们的测试代码的并发太高了,相当于在60s之内会创建N个线程,根本来不及回收就内存溢出了。
为了演示效果,我们使用自己的参数来定义一个线程池,1ms就进行一次空闲线程的回收。讲道理,这样就不会内存溢出。
package com.ywq;
import java.util.concurrent.*;
public class Test {
private static ExecutorService executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE,
1L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>());;
public static void main(String[] args) {
while (true) {
createThread(100000);
}
}
private static void createThread(int num) {
executorService.submit(new Runnable() {
public void run() {
System.out.println("Ok");
}
});
}
}所以,我的这一次JVM内存溢出的原因就是因为线程池的使用不当造成的。阿里巴巴的开发手册上强烈建议大家在使用线程池的时候进行自定义,这样才会对各个参数更加敏感,写出的代码才会更加优雅而可靠。
总结:
多线程编程,变化莫测,诡计多端,我们需要在理解多线程概念的基础上与实际工作进行有效结合,养成一种对参数的敏感性。另外,出现内存溢出,十有八九是有内存泄漏的地方,各位千万不要像我一样头铁,坚持觉得自己代码无Bug >_<
如果对你有帮助,记得点赞哦~欢迎大家关注我的博客,我会持续更新后续学习笔记,如果有什么问题,可以进群824733818一起交流学习哦~