Python 读取图像文件的性能对比
Python 读取图像文件的性能对比
使用 Python 读取一个保存在本地硬盘上的视频文件,视频文件的编码方式是使用的原始的 RGBA 格式写入的,即无压缩的原始视频文件。最开始直接使用 Python 对读取到的文件数据进行处理,然后显示在 Matplotlib 窗口上,后来发现视频播放的速度比同样的处理逻辑的 C++ 代码慢了很多,尝试了不同的方法,最终实现了在 Python 中读取并显示视频文件,帧率能够达到 120 FPS 以上。
读取一帧图片数据并显示在窗口上
最简单的方法是直接在 Python 中读取文件,然后逐像素的分配 RGB 值到窗口中,最开始使用的是 matplotlib 的 pyplot 组件。
一些用到的常量:
FILE_NAME = "I:/video.dat"
WIDTH = 2096
HEIGHT = 150
CHANNELS = 4
PACK_SIZE = WIDTH * HEIGHT * CHANNELS每帧图片的宽度是 2096 个像素,高度是 150 个像素,CHANNELS 指的是 RGBA 四个通道,因此 PACK_SIZE 的大小就是一副图片占用空间的字节数。
首先需要读取文件。由于视频编码没有任何压缩处理,大概 70s 的视频(每帧约占 1.2M 空间,每秒 60 帧)占用达 4Gb 的空间,所以我们不能直接将整个文件读取到内存中,借助 Python functools 提供的 partial 方法,我们可以每次从文件中读取一小部分数据,将 partial 用 iter 包装起来,变成可迭代的对象,每次读取一帧图片后,使用 next 读取下一帧的数据,接下来先用这个方法将保存在文件中的一帧数据读取显示在窗口中。
with open( file, 'rb') as f:
e1 = cv.getTickCount()
records = iter( partial( f.read, PACK_SIZE), b'' ) # 生成一个 iterator
frame = next( records ) # 读取一帧数据
img = np.zeros( ( HEIGHT, WIDTH, CHANNELS ), dtype = np.uint8)
for y in range(0, HEIGHT):
for x in range( 0, WIDTH ):
pos = (y * WIDTH + x) * CHANNELS
for i in range( 0, CHANNELS - 1 ):
img[y][x][i] = frame[ pos + i ]
img[y][x][3] = 255
plt.imshow( img )
plt.tight_layout()
plt.subplots_adjust(left=0, right=1, top=1, bottom=0)
plt.xticks([])
plt.yticks([])
e2 = cv.getTickCount()
elapsed = ( e2 - e1 ) / cv.getTickFrequency()
print("Time Used: ", elapsed )
plt.show()需要说明的是,在保存文件时第 4 个通道保存的是透明度,因此值为 0,但在 matplotlib (包括 opencv)的窗口中显示时第 4 个通道保存的一般是不透明度。我将第 4 个通道直接赋值成 255,以便能够正常显示图片。
这样就可以在我们的窗口中显示一张图片了,不过由于图片的宽长比不协调,使用 matplotlib 绘制出来的窗口必须要缩放到很大才可以让图片显示的比较清楚。
为了方便稍后的性能比较,这里统一使用 opencv 提供的 getTickCount 方法测量用时。可以从控制台中看到显示一张图片,从读取文件到最终显示大概要用 1.21s 的时间。如果我们只测量三层嵌套循环的用时,可以发现有 0.8s 的时间都浪费在循环上了。

读取并显示一帧图片用时 1.21s

在处理循环上用时 0.8s
约百万级别的循环处理,同样的代码放在 C++ 里面性能完全没有问题,在 Python 中执行起来就不一样了。在 Python 中这样的处理速度最多就 1.2 fps。我们暂时不考虑其他方法进行优化,而是将多帧图片动态的显示在窗口上,达到播放视频的效果。
连续读取图片并显示
这时我们继续读取文件并显示在窗口上,为了能够动态的显示图片,我们可以使用 matplotlib.animation 动态显示图片,之前的程序需要进行相应的改动:
fig = plt.figure()
ax1 = fig.add_subplot(1, 1, 1)
try:
img = np.zeros( ( HEIGHT, WIDTH, CHANNELS ), dtype = np.uint8)
f = open( FILE_NAME, 'rb' )
records = iter( partial( f.read, PACK_SIZE ), b'' )
def animateFromData(i):
e1 = cv.getTickCount()
frame = next( records ) # drop a line data
for y in range( 0, HEIGHT ):
for x in range( 0, WIDTH ):
pos = (y * WIDTH + x) * CHANNELS
for i in range( 0, CHANNELS - 1 ):
img[y][x][i] = frame[ pos + i]
img[y][x][3] = 255
ax1.clear()
ax1.imshow( img )
e2 = cv.getTickCount()
elapsed = ( e2 - e1 ) / cv.getTickFrequency()
print( "FPS: %.2f, Used time: %.3f" % (1 / elapsed, elapsed ))
a = animation.FuncAnimation( fig, animateFromData, interval=30 ) # 这里不要省略掉 a = 这个赋值操作
plt.tight_layout()
plt.subplots_adjust(left=0, right=1, top=1, bottom=0)
plt.xticks([])
plt.yticks([])
plt.show()
except StopIteration:
pass
finally:
f.close()和第 1 部分稍有不同的是,我们显示每帧图片的代码是在 animateFromData 函数中执行的,使用 matplotlib.animation.FuncAnimation 函数循环读取每帧数据(给这个函数传递的 interval = 30 这个没有作用,因为处理速度跟不上)。另外值得注意的是不要省略掉 a = animation.FuncAnimation( fig, animateFromData, interval=30 ) 这一行的赋值操作,虽然不太清楚原理,但是当我把 a = 删掉的时候,程序莫名的无法正常工作了。
控制台中显示的处理速度:
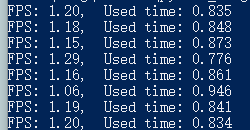
由于对 matplotlib 的了解不多,最开始我以为是 matplotlib 显示图像过慢导致了帧率上不去,打印出代码的用时后发现不是 matplotlib 的问题。因此我也使用了 PyQt5 对图像进行显示,结果依然是 1~2 帧的处理速度。因为只是换用了 Qt 的界面进行显示,逻辑处理的代码依然沿用的 matplotlib.animation 提供的方法,所以并没有本质上的区别。这段用 Qt 显示图片的代码来自于 github matplotlib issue,我对其进行了一些适配。
使用 Numpy 的数组处理 api
我们知道,显示图片这么慢的原因就是在于 Python 处理 2096 * 150 这个两层循环占用了大量时间。接下来我们换用一种 numpy 的 reshape 方法将文件中的像素数据读取到内存中。注意 reshape 方法接收一个 ndarray 对象。我这种每帧数据创造一个 ndarray 数组的方法可能会存在内存泄漏的风险,实际上可以调用一个 ndarray 数组对象的 reshape 方法。这里不再深究。
重新定义一个用于动态显示图片的函数 optAnimateFromData,将其作为参数传递个 FuncAnimation:
def optAnimateFromData(i):
e1 = cv.getTickCount()
frame = next( records ) # one image data
img = np.reshape( np.array( list( frame ), dtype = np.uint8 ), ( HEIGHT, WIDTH, CHANNELS ) )
img[ : , : , 3] = 255
ax1.clear()
ax1.imshow( img )
e2 = cv.getTickCount()
elapsed = ( e2 - e1 ) / cv.getTickFrequency()
print( "FPS: %.2f, Used time: %.3f" % (1 / elapsed, elapsed ))
a = animation.FuncAnimation( fig, optAnimateFromData, interval=30 )效果如下,可以看到使用 numpy 的 reshape 方法后,处理用时大幅减少,帧率可以达到 8~9 帧。然而经过优化后的处理速度仍然是比较慢的:

优化过的代码执行结果
使用 Numpy 提供的 memmap
在用 Python 进行机器学习的过程中,发现如果完全使用 Python 的话,很多运算量大的程序也是可以跑的起来的,所以我确信可以用 Python 解决我的这个问题。在我不懈努力下找到 Numpy 提供的 memmap api,这个 API 以数组的方式建立硬盘文件到内存的映射,使用这个 API 后程序就简单一些了:
cv.namedWindow("file")
count = 0
start = time.time()
try:
number = 1
while True:
e1 = cv.getTickCount()
img = np.memmap(filename=FILE_NAME, dtype=np.uint8, shape=SHAPE, mode="r+", offset=count )
count += PACK_SIZE
cv.imshow( "file", img )
e2 = cv.getTickCount()
elapsed = ( e2 - e1 ) / cv.getTickFrequency()
print("FPS: %.2f Used time: %.3f" % (number / elapsed, elapsed ))
key = cv.waitKey(20)
if key == 27: # exit on ESC
break
except StopIteration:
pass
finally:
end = time.time()
print( 'File Data read: {:.2f}Gb'.format( count / 1024 / 1024 / 1024), ' time used: {:.2f}s'.format( end - start ) )
cv.destroyAllWindows()将 memmap 读取到的数据 img 直接显示在窗口中 cv.imshow( "file", img),每一帧打印出显示该帧所用的时间,最后显示总的时间和读取到的数据大小:
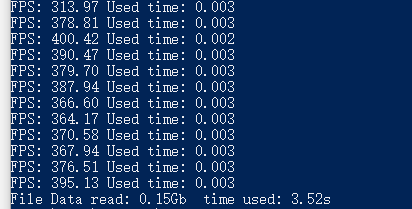
执行效率最高的结果
读取速度非常快,每帧用时只需几毫秒。这样的处理速度完全可以满足 60FPS 的需求。
总结
Python 语言写程序非常方便,但是原生的 Python 代码执行效率确实不如 C++,当然了,比 JS 还是要快一些。使用 Python 开发一些性能要求高的程序时,要么使用 Numpy 这样的库,要么自己编写一个 C 语言库供 Python 调用。在实验过程中,我还使用 Flask 读取文件后以流的形式发送的浏览器,让浏览器中的 JS 文件进行显示,不过同样存在着很严重的性能问题和内存泄漏问题。这个过程留到之后再讲。
本文中的相应代码可以在 github 上查看。
){kind=link}