查询的基本操作
1选择操作
对应的是限制条件(格式类似“field<op>consant”, field表示列对象,op是操作符如"="、">"等)。
操作对象是二维表中的行
优化方式:
选择操作下推
目的:
是尽量减少连接操作前的元素组,使得中间临时关系尽量少(元组数少,连接得到的元组数就少)
好处:
这样可能减少IO和CPU的消耗、节约内存空间。
2投影操作。
对应的SELECT查询的目的列对象。
优化方式:投影操作下推
目的:
是尽量减少连接操作前的列数,使得中间临时关系尽量少(特别注意差别:选择操作是使元祖的个数”尽量少“,投影操作是使一条元祖”尽量小“)
好处:
这样虽然不能减少IO(多数数据库存储方式是行存储,元祖是读取的最基本单位,所以要想操作列则必须读取一行数据),但可以减少连接后的中间关系的元祖大小,节约内存空间。
3连接操作
对应的是连接对象条件(格式类似“field_1<op>field_2”,field_1和field_2表示不同表的列对象,op是操作符如“=”、“>”等),表示两个表连接的条件。
Q:连接操作有优化方式么?
连接操作涉及到的两个子问题
3.1多表连接中每个表被连接的顺序决定着效率
如果一个查询语句只有一个表,则这样的语句很简单;但如果有多个表,则会设计表之间以什么样的顺序连接最高效(如A、B、C三表连接,如果ABC、ACB、BCA等连接之后的结果集一样,则哪种连接次序的效率最高,是需要考虑的问题)。
3.2多表连接每个表被连接的顺序被用户语义决定
查询语句多表连接有着不同的语义(如是笛卡尔集、内连接、还是外连接中的左外连接等),这决定着表之间的前后连接次序是不能随意更换的,否则,结果集中数据是不同的。因此,表的前后连接次序是不能随意交换的。
查询的2种类型
根据SQL语句的形式特点,还可以做如下区分:
1针对SPJ的查询优化。
基于选择、投影、连接三种基本操作相结合的查询所做的优化。
2针对非SPJ的查询优化
在SPJ基础上存在GROUPBY操作的查询,这是一种较为复杂的查询,对带有GROUPBY、ORDERBY等操作的优化。
所以,针对SPJ和非SPJ的查询优化,其实是对以上多种操作的优化。
“选择”和“投影”操作,可以在关系代数规则的指导下进行优化。
表连接,需要多表连接的相关算法完成优化。其他操作的优化多是基于索引和代价估算完成的。————物理优化。
逻辑查询优化包括的技术:
1子查询优化
2视图重写
3等价谓词重写
4条件化简
5外连接消除
6嵌套连接消除
7连接消除
8语义优化
9非SPJ的优化
Query Execution Plan of MySQL
语法格式:
EXPLAIN[explain_type] explainable_stmt
可选项包括:
EXTENDED|PARTITIONS|FORMAT = format_name
format_name:
TRADITIONAL|JSON
说明:
1 EXPLAIN命令,显示SQL语句的查询执行计划。
2 EXPLAIN EXTENDED命令,显示SQL语句的详细的查询执行计划;之后可以通过“SHOW WARNINGS”命令查看详细的信息。
3 EXPLAIN PARTITIONS命令。显示SQL语句的带有分区表信息的查询执行计划。
4 EXPLAIN命令的输出格式有两种。
4.1 TRADITIONAL;传统类型;按行隔离,每个标识一个子操作
4.2 JSOn;JSON格式。
5 explainable_stmt,可被EXPLAIN执行的SQL语句,包括的类型有:
SELECT、INSERT、UPDATE、DELETE。
执行顺序
执行五表连接的查询语句如下:
| 1 2 3 4 5 6 7 |
|
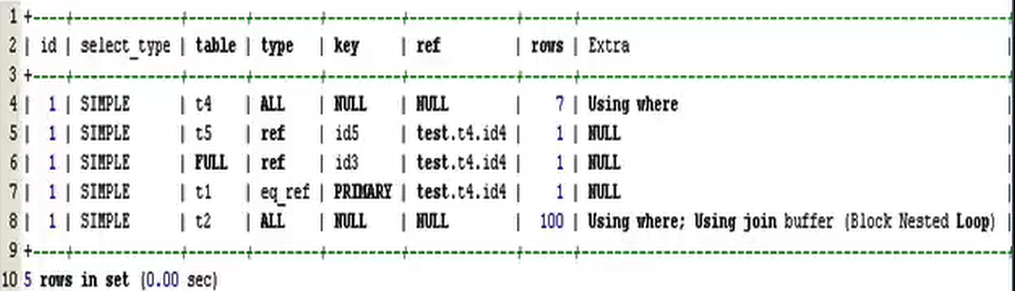
结点解析
1) id:每个被独立执行的操作的标识,表示对象被操作的顺序;id值大,先被执行;如果相同,执行顺序从上到下。
2) select_type:查询中每个select子句的类型;
3) table:名字,被操作对象的名称,通常是表名,但有其他格式。
4) partitions:匹配的分区信息(对于非分区表值为NULL)。
5) type:连接操作的类型;
6) possible_keys:备选的索引(列出可能被使用到的索引)
7) key:经优化器选定的索引;常用“ANALYZE TABLE”命令可以使优化器正确的选择索引。
8) key_len:被优化器选定的索引键的长度,单位是字节。
9) ref:表示本行被操作的对象的参照对象(被参照的对象可能是一个常用量“const”表示,也可能是其他的key指向的对象)。
10) rows:查询执行所扫描的元组个数(对于InnoDB,此值是个估计值)。
11) filtered:按照条件表上数据被过滤的元组个数的百分比,“rows X filtered/100”可求出过滤后的元组数即实际的元组数。
子查询的优化
当一个查询是另一个查询的子部分时,称之为子查询(查询语句中嵌套有查询语句)
查询的子部分,包括哪些情况:
1目标列位置。
子查询如果位于目标列,则只能是标量子查询,否则数据库可能返回类似“错误:子查询必须只能返回一个字段”的提示。
示例:
| 1 2 3 4 |
|
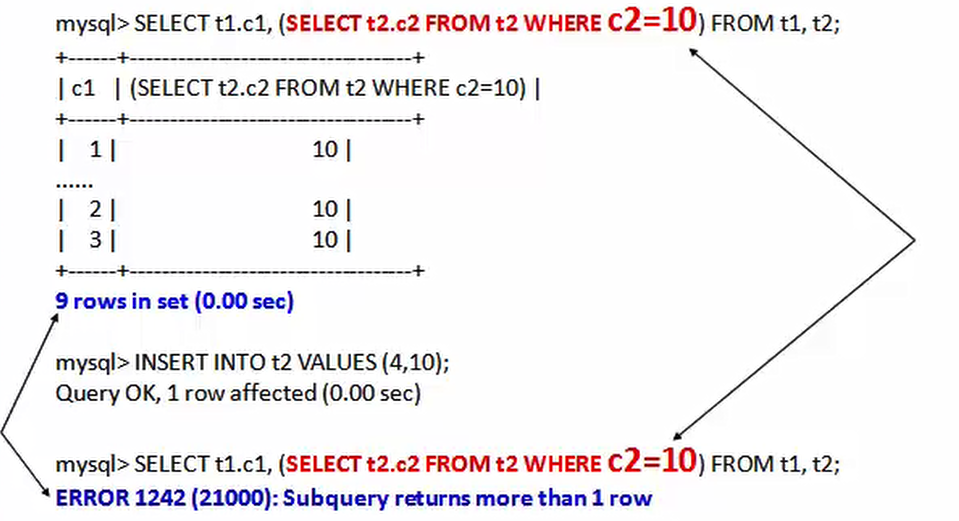



2 FORM字句位置
相关子查询出现在FROM子句中,数据库可能返回类似“在FROM子句中的子查询无法参考相同查询级别中的关系”的提示,所以相关子查询不能出现在FROM子句中;
非相关子查询出现在FROM子句中,可上拉子查询到父层,在多表连接时统一考虑连接代价然后择优。
示例:


3 WHERE子句位置
出现在WHERE子句中的子查询,是一个条件表达式的一部分,而表达式可以分解为操作符和操作数;根据参与运算的不同的数据类型,操作符也不尽相同,如INT类型有“<、>、=、<>”等操作,这对子查询均有一定的要求(如INT型的等值操作,要求查询必须是标量子查询)。另外,子查询出现在WHERE子句中的格式,也有用谓词指定的一些操作,如IN、BETWEEN、EXISTS等。
示例:


4 JOIN/ON子句位置
JOIN/ON子句可以拆分为两部分,一是JOIN块类似于FROM子句,二是ON子句块类似于WHERE子句,这两部分都可以出现子查询。子查询的处理方式同FROM子句和WHERE子句。
5 GROUPBY子句位置
目标列必须和GROUPBY关联.可将子查询写在GROUPBY位置处,但子查询用在GROUPBY处没有实用意义。
6ORDERBY子句位置
可将子查询写在ORDERBY位置处,但ORDERBY操作是作用在整条SQL语句上的,子查询用在ORDERBY处没有实用意义。
子查询的类型——从对象间的关系看:
1 相关子查询
子查询的执行依赖于外层父查询的一些属性值。子查询因依赖于父查询的参数,当父查询的参数改变时,子查询需要根据新参数值重新执行(查询优化器对相关子查询进行优化有一定意义),如:

2 非相关子查询
子查询的执行,不依赖于外层父查询的任何属性值。这样子查询具有独立性,可独自求解,形成一个子查询计划先于外层的查询求解,如:

子查询的类型——从特定谓词来看:
1 [NOT]IN/ALL/ANY/SOME子查询
语义相近,表示“[取反]存在/所有/任何/任何”,左面是操作数,右面是子查询,是最常见的子查询类型之一。
2 [NOT]EXISTS子查询
半连接语义,表示“[取反]存在”,没有左操作数,右面是子查询,也是最常见的子查询类型之一。
3其他子查询
除了上述两种外的所有子查询。
子查询的类型——从语句的构成复杂程度来看:
1 SPJ子查询
有选择、连接、投影操作组成的查询
2 GROUPBY子查询
SPJ子查询加上分组、聚集操作组成的查询。
3其他子查询
GROUPBY子查询中加上其他子句如Top-N、LIMIT/OFFSET、集合、排序等操作。
后两中子查询有时合称非SPJ查询。
子查询的类型——从结果的角度来看
1 标量子查询
子查询返回的结果集类型是一个简单值(return a scalar, a single value)。
2单行单列子查询
子查询返回的结果集类型是零条或一条单元组(return a zero or single row, but only a column).相似于标量子查询,但可能返回零条元组。
3 多行单列子查询
子查询返回的结果集类型是多条元组但只有一个简单列(return multiple rows, but only a column)。
4 表子查询
子查询返回的结果集类型是一个表(多行多列)(return a table, one or more rows of one or more columns)。
为什么要做子查询优化?
在数据库实现早期,查询优化器对子查询一般采用嵌套执行的方式,即父查询中的每一行,都执行一次子查询,这样子查询会执行很多次。这种执行方式效率低。
而对子查询进行优化,可能带来几个数量级的查询效率的提高。子查询转变成为连接操作之后,会得到如下好处:
1子查询不用执行很多次。
2优化器可以根据统计信息来选择不同的连接方法和不同的连接顺序。
子查询中的连接条件、过滤条件分别变成了父查询的连接条件、过滤条件,优化器可以对这些条件进行下推,以提高执行效率。
How to optimize SubQuery?
1 子查询合并(SubQuery Coalescing)
在某些条件下(语义等价:两个查询块产生同样的结果集),多个子查询能够合并成一个子查询(合并后还是子查询,以后可以通过其他技术消除掉子查询)。这样可以把多次表扫描、多次连接减少为单次表扫描和单次连接,如:
SELECT * FROM t1 WHERE a1<10 AND(
EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1)OR
EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2)
);
可优化为:
SELECT * FROM t1 WHERE a1<10 AND(
EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2))
/*两个ESISTS子句合并为一个,条件也进行了合并*/
);
2 子查询展开(SubQuery Unnesting)
又称为子查询反嵌套,又称为子查询上拉。
把一些子查询置于外层的父查询中,作为连接关系与外层父查询并列,其实质是把某些子查询重写为等价的多表连接操作(展开后,子查询不存在了,外部查询变成了多表连接)。
带来的好处是,有关的访问路径、连接方法和连接顺序可能被有效使用,使得查询语句的层次尽可能地减少。
常见的IN/ANY/SOME/ALL/EXISTS依据情况准换为半连接(SEMI JOIN)、普通类型的子查询消除等情况属于此类,如:
SELECT * FROM t1,(SELECT * FROM t2 WHERE t2.a2>10) v_t2
WHERE t1.a1<10 AND v_t2.a2<20;
可优化为:
SELECT * FROM t1,t2 WHERE t1.a1<10 AND t2.a2<20 AND t2.a2>10;
/*子查询变为了t1、t2表的连接操作,相当于把t2表从子查询中上拉了一层*/
3 聚集子查询消除(Aggregate SubQuery Elimination)
通常,一些系统支持的是标量聚集子查询消除。
如:
SELECT * FROM t1 WHERE t1.a1>(SELECT avg(t2.a2) FROM t2);
MySQL可以优化什么格式的子查询?
MySQl支持对简单SELECT查询中的子查询优化,包括:
1 简单SELECT查询中的子查询。
2 带有DISTINCT、ORDERBY、LIMIT操作的简单SELECT查询中的子查询。
CREATE TABLE t1 (a1 INT, b1 INT, PRIMARY KEY (a1));
CREATE TABLE t2 (a2 INT, b2 INT, PRIMARY KEY (a3));
CREATE TABLE t3 (a3 INT, b3 INT, PRIMARY KEY (a3));
插入10000行与上例同样的数据。
查询执行计划如下:
mysql>EXPLAIN EXTENDED SELECT * FROM t1 WHERE t1.a1<100 AND a1 IN (SELECT a2 FROM t2 WHERE t2.a2>10);

MySQL不支持对如下情况的子查询进行优化:
带有UNION操作。
带有GROUPBY、HAVING、聚集函数。
使用ORDERBY中带有LIMIT。
内表、外表的个数超过MySQL支持的最大表的连接数。
聚集函数操作在子查询中,查询执行计划如下:

子查询合并技术,不支持:
mysql>explain extended select * from t1 where a1<4 and (exists (select a2 from t2 where t2.a2<5 and t2.b2=1) or exists(select a2 from t2 where t2.a2<5 and t2.b2=2));


子查询展开(子查询反嵌套)技术,支持的不够好
mysql>explain extended select * from t1,(select * from t2 where t2.a2>10)v_t2 where t1.a1<10 and v_t2 .a2<20;

再看一个IN子查询的例子,查询执行计划如下:
mysql>explain extended select * from t1 where ta.a1<100 and a1 in (select a2 from t2 where t2.a2>10);
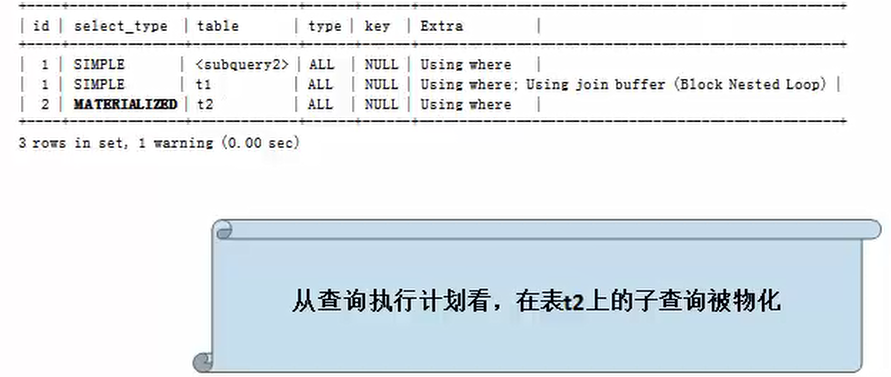

……
聚集子查询消除技术,不支持
mysql>explain extended select * from t1 where t1.a1>(select min(t2.a2) from t2);

Q:MySQL为什么不支持聚集子查询消除?
A:1 MySQL认为,聚集子查询,只需要执行一次,得到结果后,即可把结果缓冲到内存中供后续连接或过滤等操作使用,没有必要消除子查询。
2另外,如果聚集子查询在索引列上执行,则会更快得到查询结果,更能加速查询速度。

MySQL支持对哪些类型的子查询进行优化?
示例1 MySQL不支持对EXISTS类型的子查询做近一步的优化。
被查询优化器处理后的语句为:

EXISTS类型的相关子查询,查询执行计划如下:
mysql>explain extended select* from t1 where exists (select 1 from t2 where t1.a1=t2.a2 and t2.a2>10);

示例2 MySQL不支持对NOT EXISTS类型的子查询做进一步的优化。
被查询优化器处理后的语句为:

NOT EXISTS类型的相关子查询的查询执行计划如下:
mysql>explain extended select * from t1 where NOT EXISTS (select 1 from t2 where t1.a1=t2.a2 and t2.a2>10);
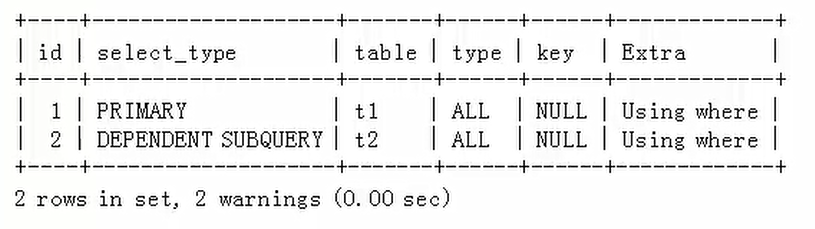
示例3 MySQL支持对IN类型的子查询的优化。
IN非相关子查询,查询计划如下:
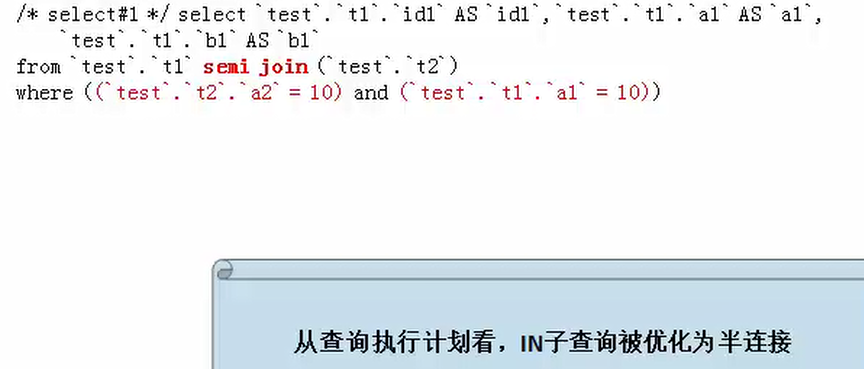
mysql>explain extended select * from t1 where t1.a1 IN (select a2 from t2 where t2.a2>10);

被查询优化器处理后的语句为
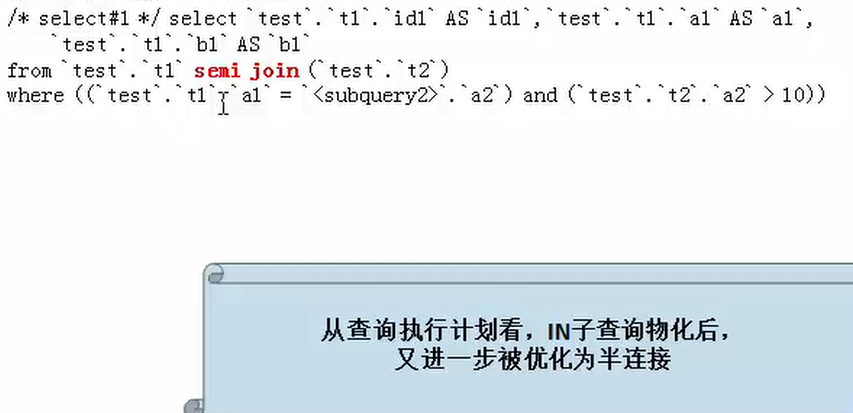
IN相关子查询,查询执行计划如下:
mysql>explain extended select * from t1 where t1.a1 IN(select a2 from t2 where t1.a1=10);

被查询优化器处理后的语句为:
示例4 MySQL支持对NOT IN类型的子查询的优化。
NOT IN非相关子查询,查询计划如下:
mysql>explain extended select * from t1 where t1.a1 NOT IN (select a2 from t2 where t2.a2>10);

被查询优化器处理后的语句为

示例5 MySQL支持对ALL类型的子查询的优化。
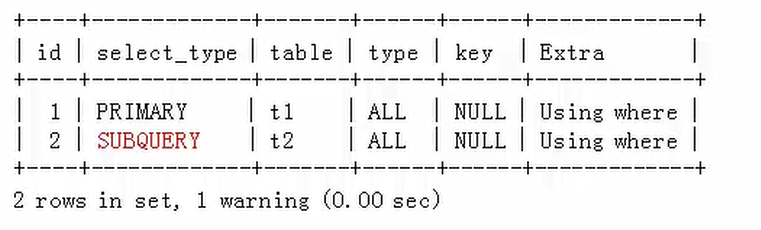
ALL非相关子查询,查询计划如下:
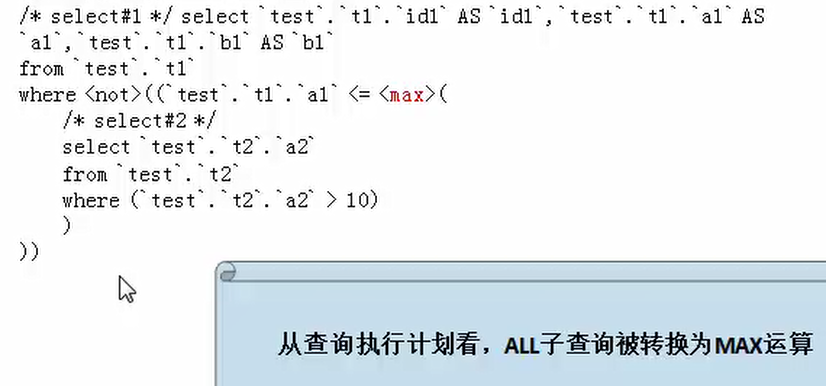
mysql>explain extended select * from t1 where t1.a1 >ALL (select a2 from t2 where t2.a2>10);
被查询优化器处理后的语句为
mysql>explain extended select * from t1 where t1.a1 =ALL (select a2 from t2 where t2.a2=10);
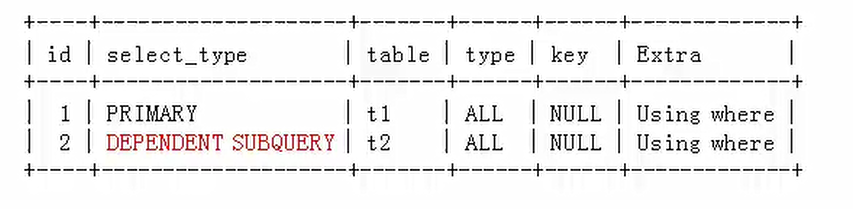
被查询优化器处理后的语句为

mysql>explain extended select * from t1 where t1.a1 <ALL (select a2 from t2 where t2.a2=10);

被查询优化器处理后的语句为

示例6 MySQL支持对SOME类型的子查询的优化。
使用了“>SOME”式子的子查询被优化,查询计划如下:
mysql>explain extended select * from t1 where t1.a1 >SOME (select a2 from t2 where t2.a2>10);
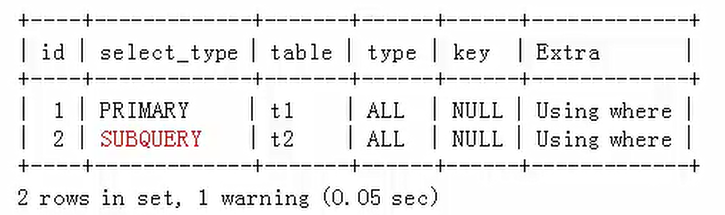
被查询优化器处理后的语句为
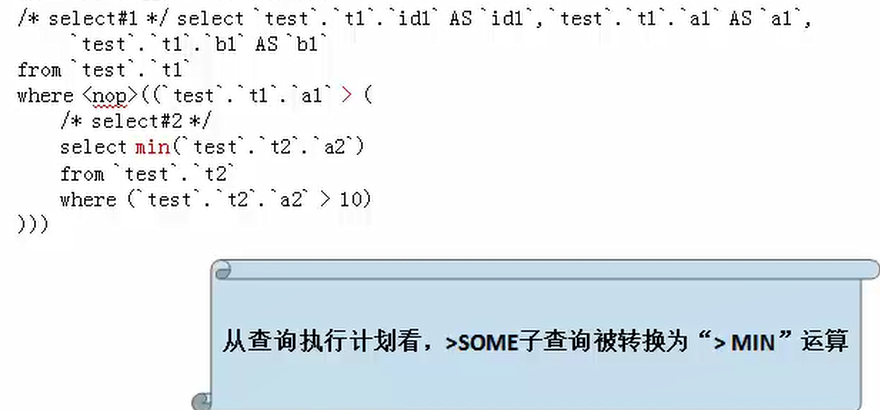
使用了“=SOME”式子的子查询被优化,查询计划如下:
mysql>explain extended select * from t1 where t1.a1 =SOME (select a2 from t2 where t2.a2=10);
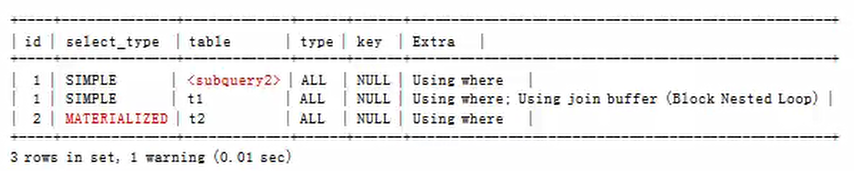
被查询优化器处理后的语句为
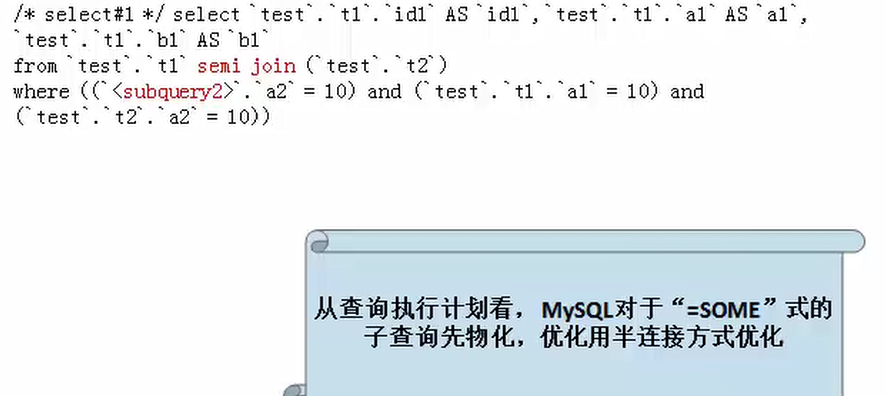
使用了“<SOME”式子的子查询被优化,查询计划如下:
mysql>explain extended select * from t1 where t1.a1 <SOME (select a2 from t2 where t2.a2=10);
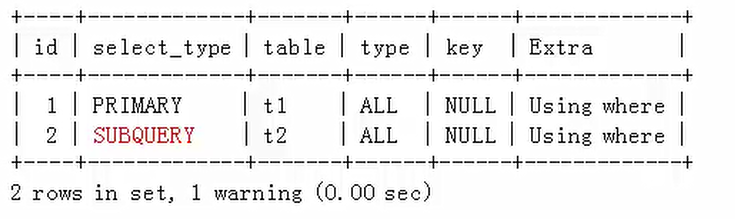
被查询优化器处理后的语句为

示例7 MySQL支持对ANY类型的子查询的优化。

使用了“=ANY”式子的子查询被优化,查询计划如下:
mysql>explain extended select * from t1 where t1.a1 =ANY (select a2 from t2 where t2.a2>10);

被查询优化器处理后的语句为

使用了“<ANY”式子的子查询被优化,查询计划如下:
mysql>explain extended select * from t1 where t1.a1 <ANY (select a2 from t2 where t2.a2>10);
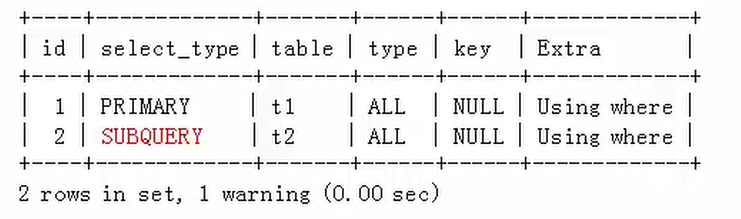
被查询优化器处理后的语句为
